



-
结构简单清晰,实现和部署相对直接 -
训练稳定性好,收敛行为可预测 -
在多样化任务上表现均衡,泛化能力强 -
工程上成熟,拥有丰富的优化方法和工具支持 -
随着参数规模增加,性能通常呈现可预测的提升
-
计算资源需求高,训练和推理成本大 -
自注意力机制的计算复杂度为O(n²),处理长序列效率低 -
内存占用大,对硬件要求高 -
扩展性受限,无法通过增加参数实现无限制的性能提升 -
模型参数规模与部署难度成正比,对普通终端设备不友好
-
需要高质量和一致性输出的商业应用 -
通用型AI服务,如GPT系列模型 -
拥有大量计算资源的组织和机构 -
研究基准模型,作为其他架构的比较对象 -
不专注于特定领域,而需要在多个领域有均衡表现的场景

# MoE层的伪代码简化实现
def moe_layer(x, experts, router):
# 计算每个专家的路由分数
routing_scores = router(x) # [batch_size, seq_len, num_experts]
# 选择Top-k专家
top_k_scores, top_k_indices = select_top_k(routing_scores, k=2)
# 将输入分发到选中的专家
outputs = []
for i, expert in enumerate(experts):
# 创建每个专家的掩码(哪些令牌被路由到此专家)
mask = (top_k_indices == i)
if mask.any():
# 只处理被路由到此专家的令牌
expert_input = x[mask]
expert_output = expert(expert_input)
outputs.append((mask, expert_output))
# 合并所有专家的输出
combined_output = combine_expert_outputs(outputs, shape=x.shape)
return combined_output-
训练效率高,相同计算预算下可使用更多参数 -
推理速度快,与稠密模型相比可节省大量计算 -
可扩展性强,理论上可以无限增加专家数量 -
在单位计算成本下,通常能达到更好的性能 -
不同专家可以专注于不同类型的任务,提高多领域能力
-
内存需求大,需要将所有专家加载到内存中 -
训练不稳定性较高,路由机制容易导致专家分配不均 -
微调难度大,容易出现过拟合现象 -
实现复杂,需要特殊的分布式训练策略 -
路由决策增加了额外的计算和决策延迟
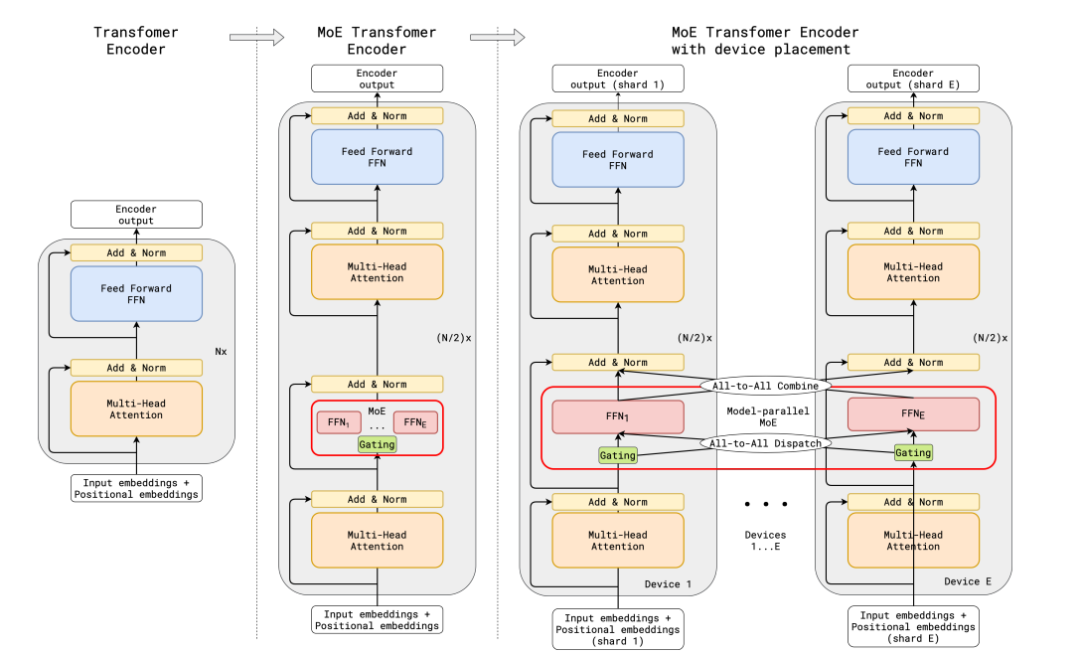
-
需要大规模参数但训练资源有限的情况 -
高吞吐量的推理服务环境 -
具有多台机器的分布式训练架构 -
追求极致性能的研究场景 -
具有明显领域差异的多任务学习场景 -
知识密集型任务(如事实回忆、知识问答等)

# 连续时间SSM的数学描述
x'(t) = Ax(t) + Bu(t) # 状态更新方程
y(t) = Cx(t) + Du(t) # 输出方程
其中:
- x(t) 是n维隐藏状态向量
- u(t) 是输入向量
- y(t) 是输出向量
- A, B, C, D 是可学习的参数矩阵-
计算复杂度为O(n),处理长序列效率高 -
推理速度快,与序列长度呈线性关系 -
内存占用较小,状态表示紧凑 -
选择性机制使模型能高效处理不相关信息 -
在长文本、基因组学等长序列场景表现优异
-
技术相对较新,工程实践和优化方法尚不成熟 -
设计和调优难度大,对数学背景要求高 -
与Transformer相比,缺乏平行处理多个关联项的能力 -
模型理解和可解释性较弱 -
大规模应用的案例仍然有限
-
长文本处理和理解任务 -
实时/低延迟的序列预测场景 -
资源受限的部署环境(如移动设备) -
基因组学等生物信息学长序列分析 -
需要处理百万级长度序列的场景 -
音频、视频等时间序列数据处理
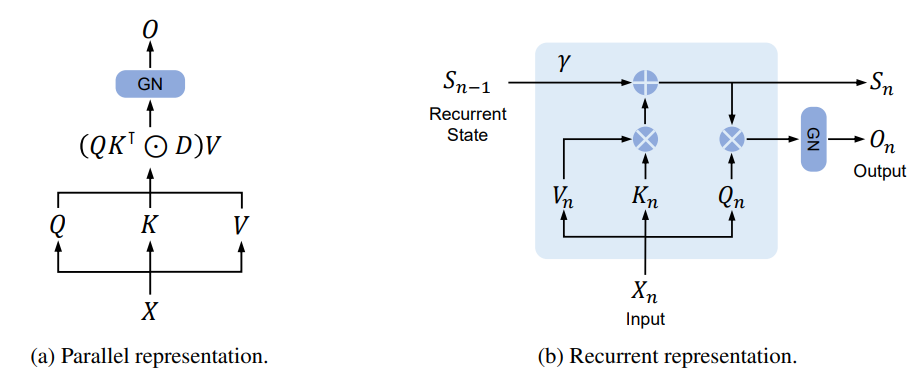
# RetNet中保留机制的简化公式
# 并行表示(用于训练)
y_i = sum_{j≤i} exp(-(i-j)/γ) · (q_i · k_j^T) · v_j
# 递归表示(用于推理)
s_i = exp(-1/γ) · s_{i-1} + k_i · v_i
y_i = q_i · s_i
其中:
- q_i, k_i, v_i 分别是查询、键和值向量
- s_i 是隐藏状态
- γ 是衰减率参数-
训练时并行计算,效率与Transformer相当 -
推理时递归计算,内存使用率高,速度快 -
推理延迟低,适合高吞吐量场景 -
内存消耗较小,缓存开销低于Transformer -
在大规模模型(>2B参数)中表现尤为出色
-
相对较新,生态系统和工具支持有限 -
在小规模模型上可能不如Transformer -
对特定硬件的优化不如Transformer成熟 -
保留机制可能无法像注意力机制那样灵活捕获全局关系 -
实现和优化的技术挑战大

-
大规模语言模型(特别是参数>2B的模型) -
需要高吞吐量和低延迟的在线服务 -
内存资源受限的推理环境 -
需要均衡训练效率和推理效率的场景 -
长序列推理场景,特别是需要持续生成文本的应用
# 基本RNN递归公式
h_t = tanh(W_h · h_{t-1} + W_x · x_t + b)
y_t = W_y · h_t + b_y
# LSTM递归公式(简化版)
f_t = sigmoid(W_f · [h_{t-1}, x_t] + b_f) # 遗忘门
i_t = sigmoid(W_i · [h_{t-1}, x_t] + b_i) # 输入门
o_t = sigmoid(W_o · [h_{t-1}, x_t] + b_o) # 输出门
c_t = f_t * c_{t-1} + i_t * tanh(W_c · [h_{t-1}, x_t] + b_c) # 单元状态
h_t = o_t * tanh(c_t) # 隐藏状态-
计算复杂度为O(n),适合处理长序列 -
内存占用小,状态表示紧凑 -
推理速度快,每步计算量固定 -
天然适合自回归生成任务 -
在有限资源环境中性能优异
-
训练不易并行化,效率低 -
传统RNN难以捕获长期依赖关系 -
训练不稳定,容易出现梯度消失/爆炸 -
模型表达能力有限,规模扩展困难 -
没有全局上下文视角,处理长文本理解能力弱
-
在训练时并行计算,类似Transformer -
在推理时递归计算,类似RNN -
计算复杂度和内存使用随序列长度线性增长
-
计算资源有限的推理环境 -
需要处理超长序列的场景 -
实时/低延迟的文本生成应用 -
移动设备等边缘计算场景 -
流数据处理和在线学习场景


-
任意到任意(Any-to-Any)模型:能够接收任何模态的输入并生成任何模态的输出,如Gemini Ultra、GPT-4o等。 -
模态无关的架构设计:发展通用的架构,能够以相同的方式处理不同模态的信息,降低对特定模态处理的依赖。 -
更高效的模态对齐技术:改进模态间的对齐和融合方法,使模型能更好地理解跨模态的关系。 -
新型分词和编码方法:开发更高效的多模态分词器和编码器,提高模型处理不同类型数据的能力。 -
架构与底层基础模型的解耦:使多模态能力成为可即插即用的模块,便于与不同基础模型组合。
-
通用AI服务:Dense架构(如GPT系列)提供最稳定的性能 -
知识密集型任务:MoE架构可能表现更佳 -
长文本处理:SSM或RNN变体可能是更好选择 -
高吞吐量服务:RetNet或RWKV可能更适合
-
训练资源充足:可以考虑Dense或MoE架构 -
训练资源有限:SSM或RetNet可能更合适 -
推理延迟要求低:SSM、RetNet或RNN变体更合适 -
内存受限环境:避免选择MoE,优先考虑SSM或RNN变体
-
生产环境:优先选择成熟的Dense架构 -
研究环境:可以尝试新型架构如SSM、RetNet -
需要工具生态支持:Dense和MoE架构拥有更丰富的工具 -
愿意承担技术风险:新型架构可能提供更好性能/成本比

-
MoE-Mamba:结合MoE的专家路由和Mamba的高效序列处理 -
Sparse-RetNet:在RetNet基础上引入稀疏激活 -
Transformer-SSM混合模型:在不同层使用不同架构,如浅层使用SSM处理长序列,深层使用Transformer进行推理 -
架构自适应模型:根据输入内容和计算资源动态选择最适合的架构
-
计算效率优先:随着模型规模不断扩大,计算效率将成为架构设计的首要考量。MoE、SSM、RetNet等高效架构将得到更广泛的应用。 -
硬件协同设计:架构设计将更加关注与特定硬件平台的协同优化,如专为GPU/TPU/ASIC设计的算法和数据流。 -
动态与自适应:未来架构可能具备更强的动态性和自适应性,能根据输入内容和资源约束自动调整计算方式。 -
长序列处理能力:处理超长文本的能力将成为架构设计的关键考量,SSM和RetNet等架构在这方面具有先天优势。 -
多模态无缝集成:架构设计将更加关注多模态信息的无缝处理,打破模态边界。

-
算力效率革命:新架构可能彻底改变AI计算效率水平 -
民主化AI:高效架构降低门槛,使更多组织能部署大模型 -
边缘AI:适合资源受限环境的架构推动边缘设备的AI应用 -
领域定制:专业化架构针对特定领域优化性能 -
架构融合:不同架构思想的融合带来创新突破
-
工程复杂性:新架构带来实现和维护的挑战 -
生态系统建设:新架构需要完善的工具和库支持 -
理论理解:对新架构原理的深入理解仍不充分 -
评估标准:不同架构难以公平比较 -
技术整合:如何在保持简洁性的同时整合多种优势
-
Vaswani, A., et al. (2017). “Attention Is All You Need”. NeurIPS 2017. -
Brown, T., et al. (2020). “Language Models are Few-Shot Learners”. NeurIPS 2020. -
Fedus, W., et al. (2022). “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity”. Journal of Machine Learning Research. -
Gu, A., et al. (2023). “Mamba: Linear-Time Sequence Modeling with Selective State Spaces”. arXiv:2312.00752. -
Sun, Z., et al. (2023). “Retentive Network: A Successor to Transformer for Large Language Models”. arXiv:2307.08621. -
Peng, B., et al. (2023). “RWKV: Reinventing RNNs for the Transformer Era”. arXiv:2305.13048. -
Zhai, S., et al. (2022). “LiT: Zero-Shot Transfer with Locked-image Text Tuning”. CVPR 2022. -
Shazeer, N., et al. (2017). “Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer”. ICLR 2017. -
Alayrac, J. B., et al. (2022). “Flamingo: a Visual Language Model for Few-Shot Learning”. NeurIPS 2022. -
Gu, A., et al. (2024). “Mamba-2: Improving State Space Models with Attention”. arXiv:2405.21060.
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END












