导读 本文将探讨 Ray 在微信 AI 计算中的大规模实践。
1. 背景
2. 百万级节点的集群管理
3. 高效稳定的利用低优资源
4. 降低应用部署复杂度
5. Astra-Ray 使用样例
6. Q&A
分享嘉宾|陈国敏 腾讯微信专家工程师,微信 Astra 平台负责人
编辑整理|马同学
内容校对|李瑶
出品社区|DataFun
背景


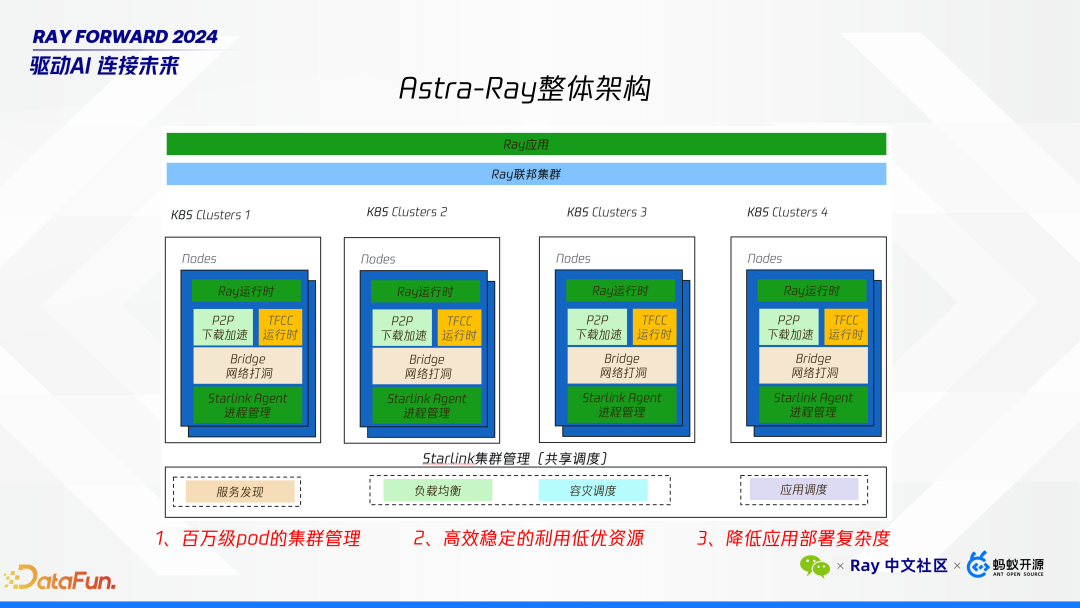
百万级节点的集群管理
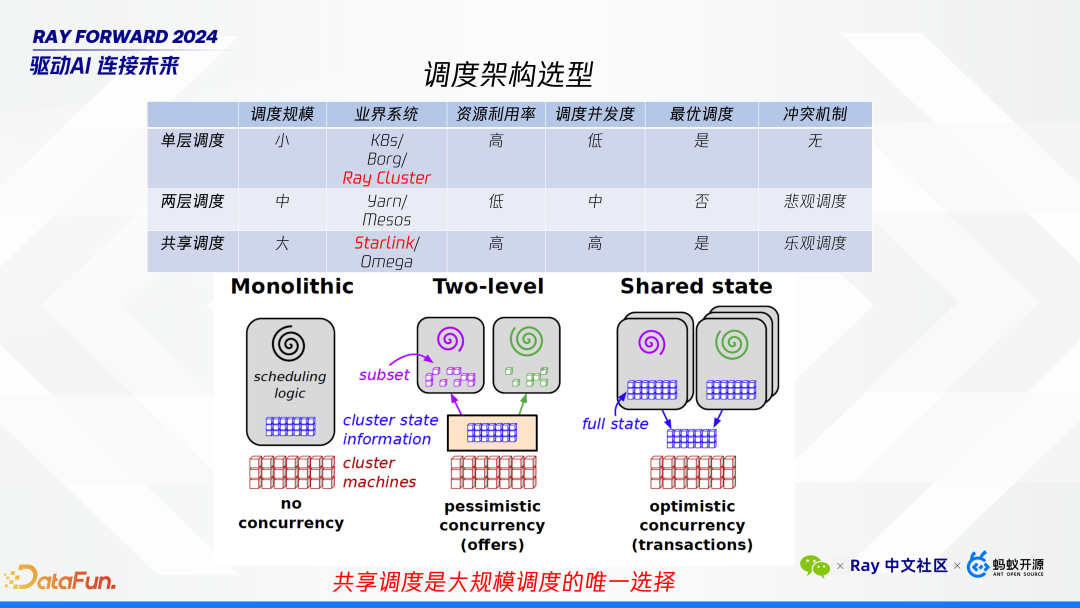
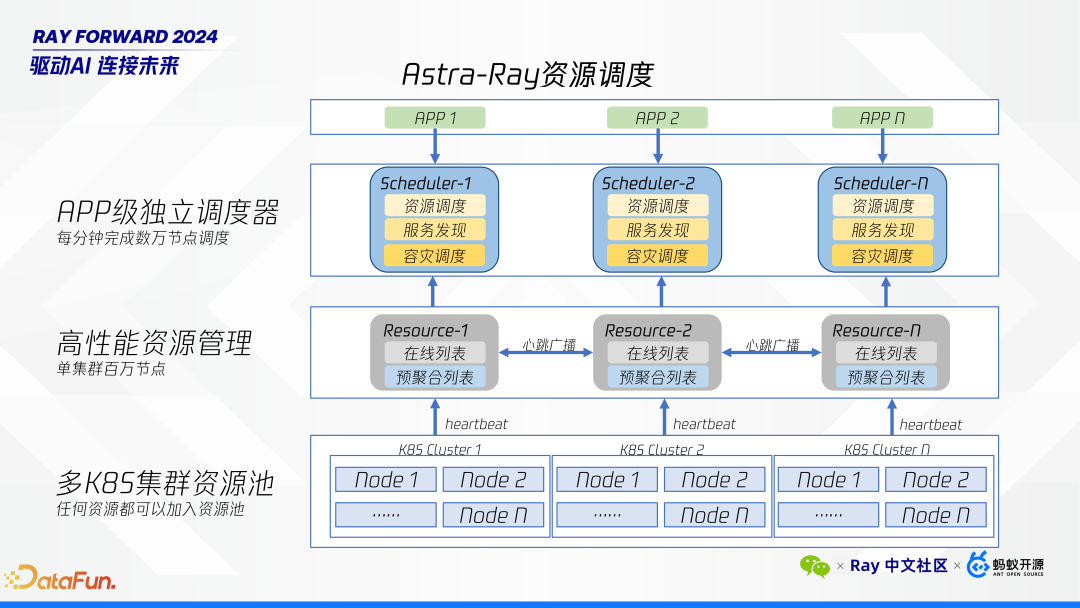
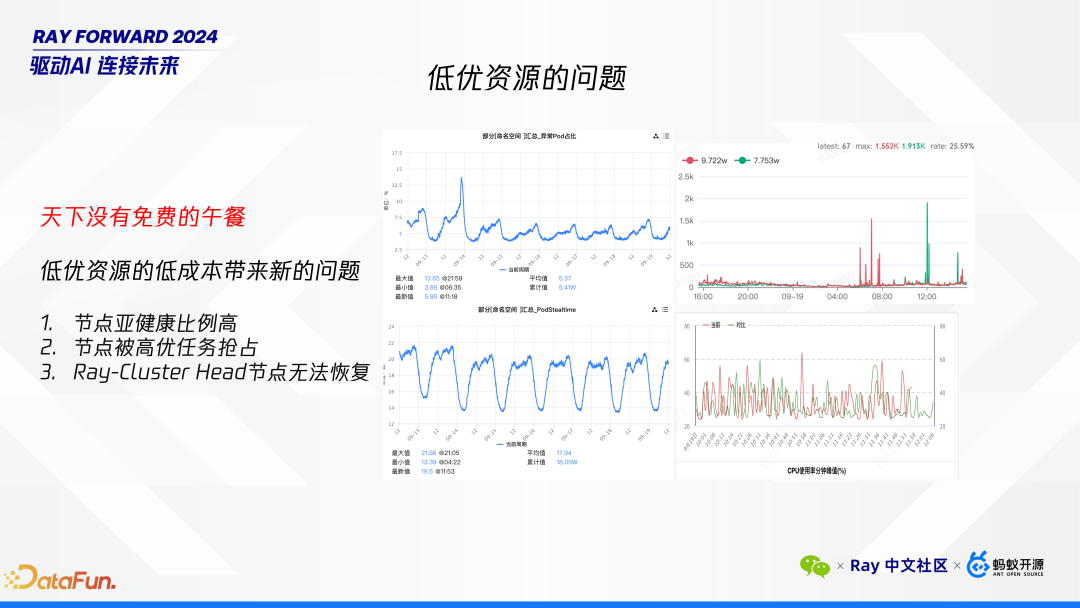
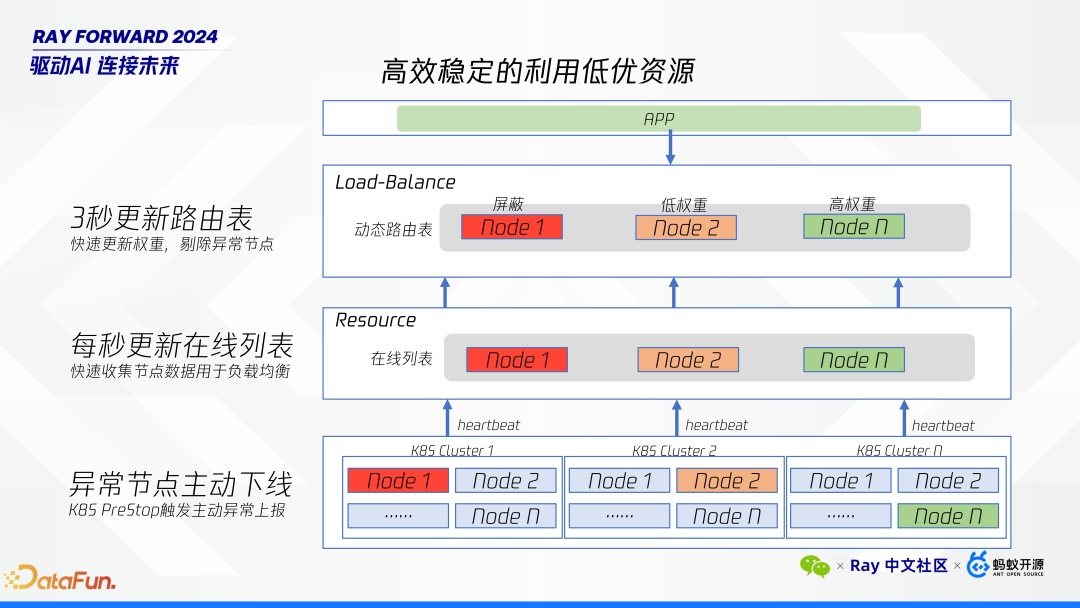
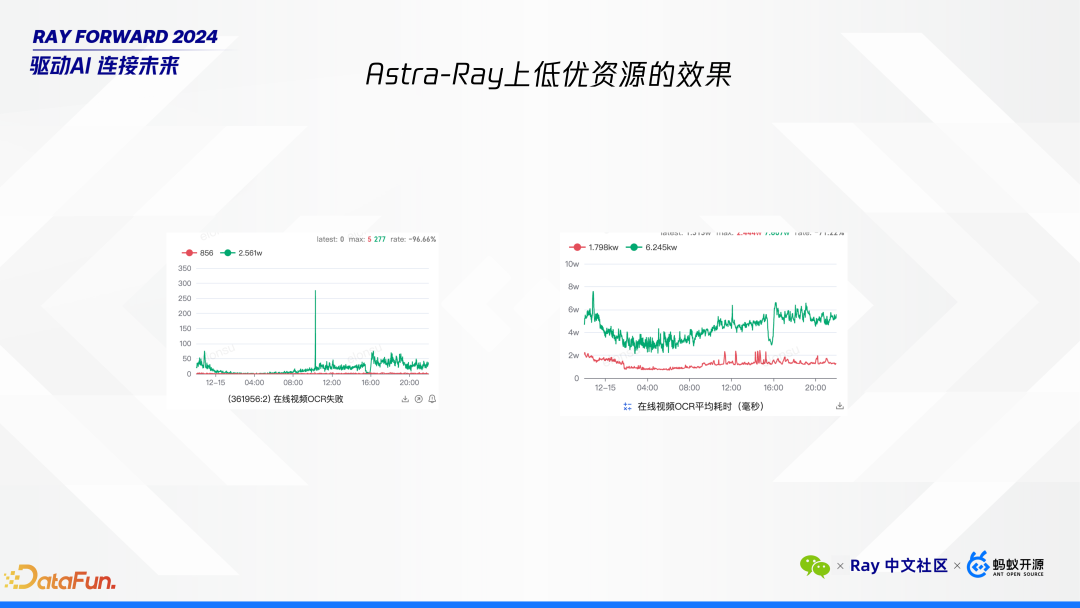
高效稳定地利用低优资源
-
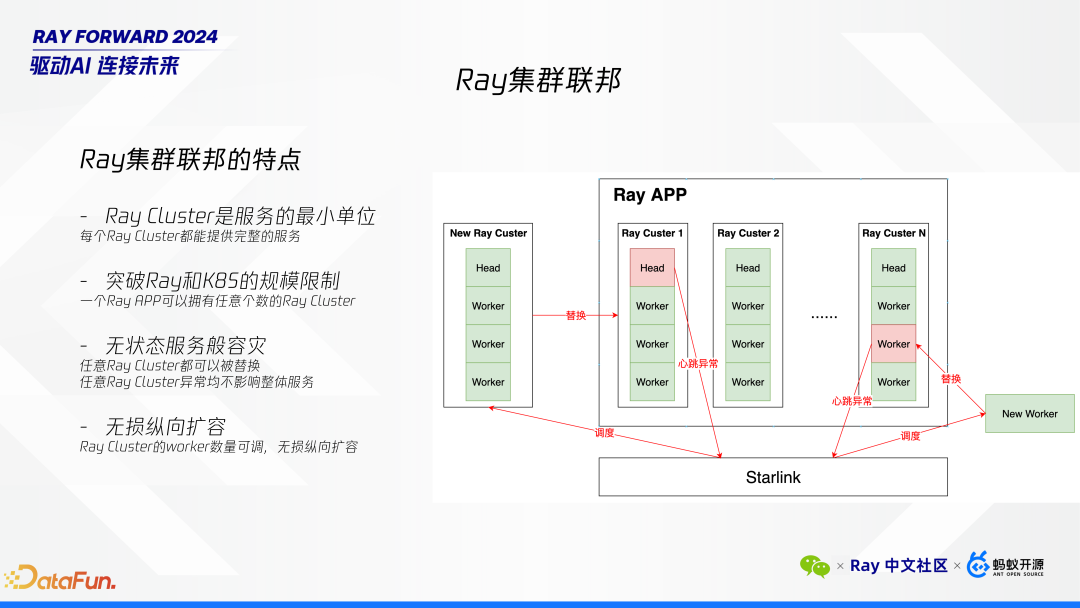
服务单元化:每个 Ray cluster 都是一个独立的服务单元,可以单独提供完整的服务。
-
容灾能力:通过增加更多的 Ray cluster 来实现容灾。每个 cluster 都可以视为一个容灾单元,从而增强了系统的鲁棒性。
-
突破规模限制:由于我们的基础设施本身支持百万级节点管理,我们可以将每个 Ray cluster 设计得较小,从而突破单个 cluster 的规模限制。
-
无状态服务般的容灾:无论哪个节点或整个 cluster 挂掉,我们都可以迅速替换,确保服务的连续性。
-
头节点故障处理:当头节点出现心跳异常时,我们会立即从路由算法中移除该 cluster,并调度一个新的 Ray cluster 进行替换。
-
Worker 节点故障处理:如果仅是 worker 节点故障,该 cluster 仍可继续使用,只需替换故障的 worker 节点即可。
-
扩展性:我们的 Ray Cluster 机制支持纵向扩容,可以根据需要调整 worker 数量,从而解决了大规模部署下的扩展性问题。
-
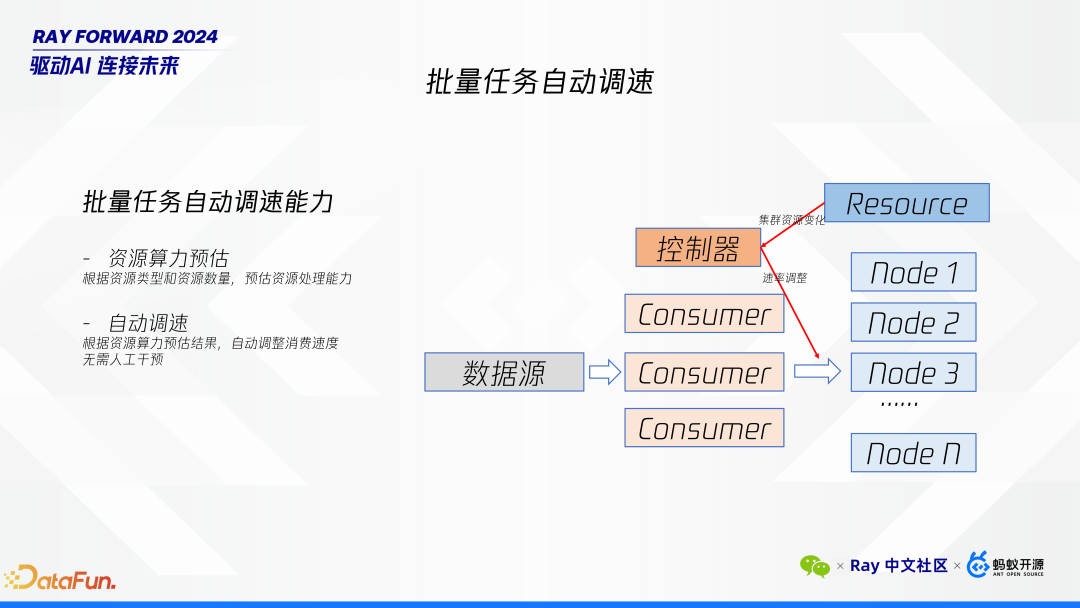
性能预估:我们根据资源类型(如不同型号的 GPU)和可用资源的数量,动态评估每个节点的处理能力。这一预估考虑了多种卡型共存的情况,确保评估结果的准确性。
-
动态调整消费速率:基于性能预估的结果,当检测到集群中的资源变化时,系统会自动调整任务的消费速率。这种调整确保即使在资源减少的情况下,也能维持服务的稳定性和性能。
-
保障服务连续性:通过上述机制,即使低优资源被移除或集群处理能力发生变化,我们的系统仍能保持正常运行,避免因资源波动导致的服务中断。
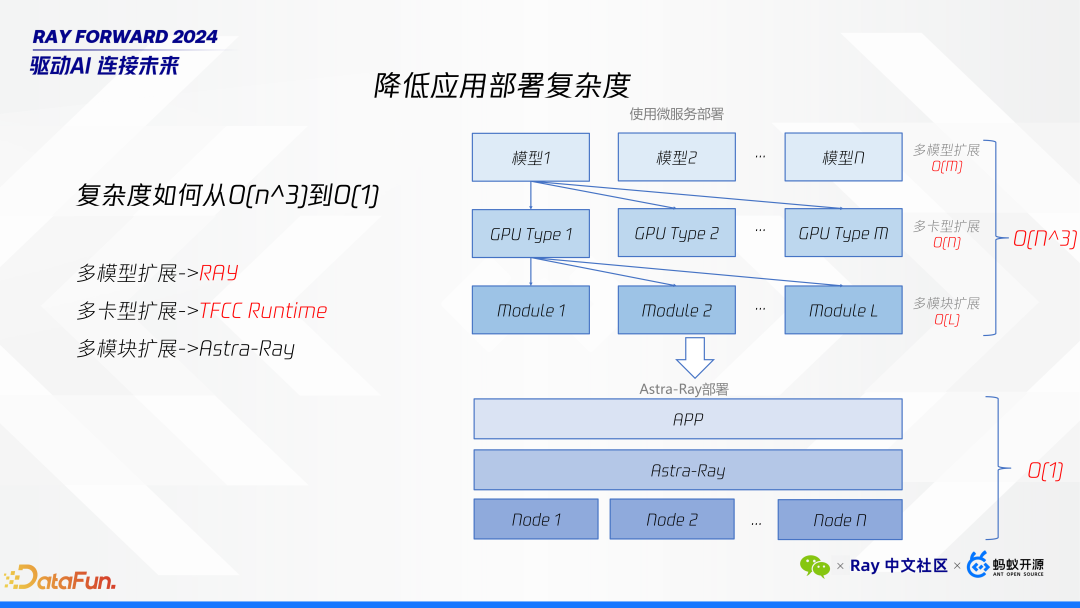
降低应用部署复杂度
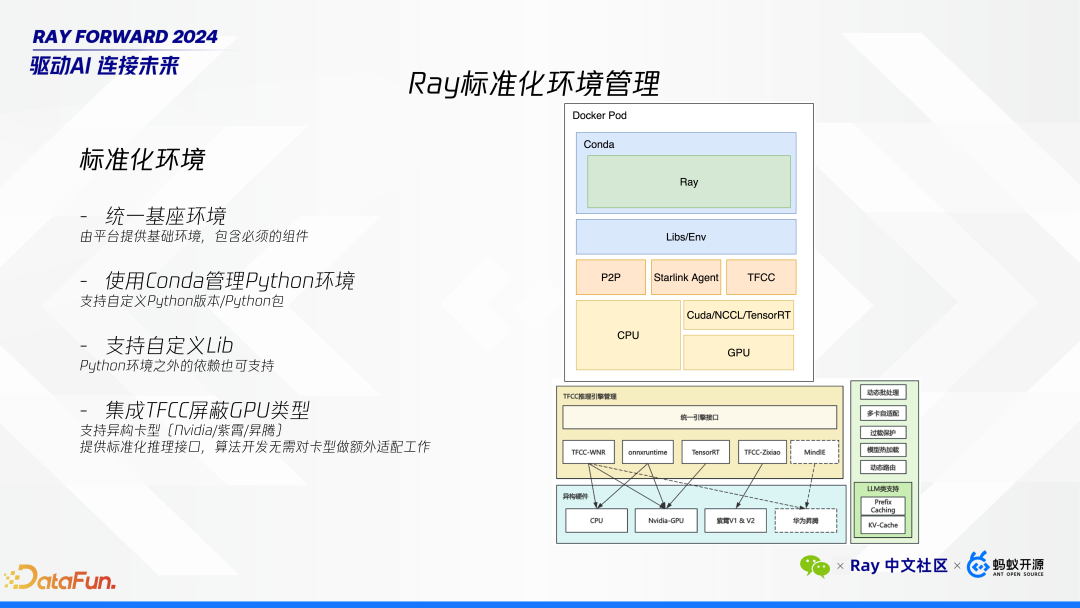
-
核心组件:该环境包含了所有必需的核心组件,例如 P2P 网络穿透、TFCC 以及特定版本的 CUDA,以确保一致性和兼容性。
-
包管理:允许用户使用 Conda 管理包,允许用户选择不同版本的 Python,并实现自定义环境配置。这一系统是我们自行开发的环境管理工具,旨在为用户提供灵活的包管理能力。
-
自定义库与编译:支持用户自定义使用各种库及进行 CI(持续集成)编译操作,以满足多样化的开发需求。
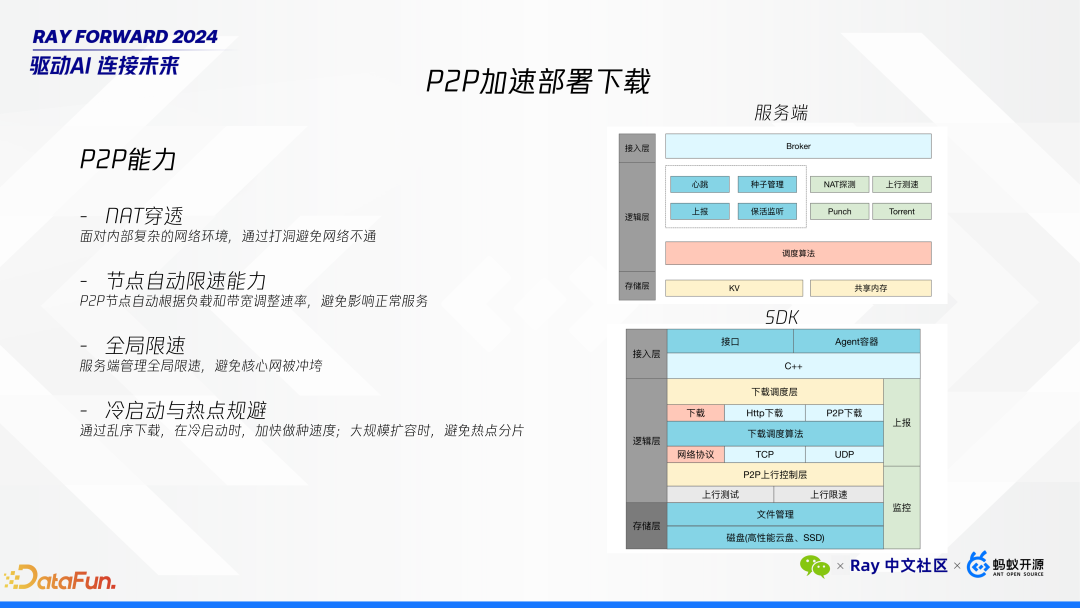
-
NAT 穿透:实现了 NAT 穿透功能,确保在复杂网络环境下也能高效传输数据。
-
节点限速与全局限速:为保证网络资源的合理分配,引入了节点级别的限速和全局限速机制。
Astra-Ray 使用样例
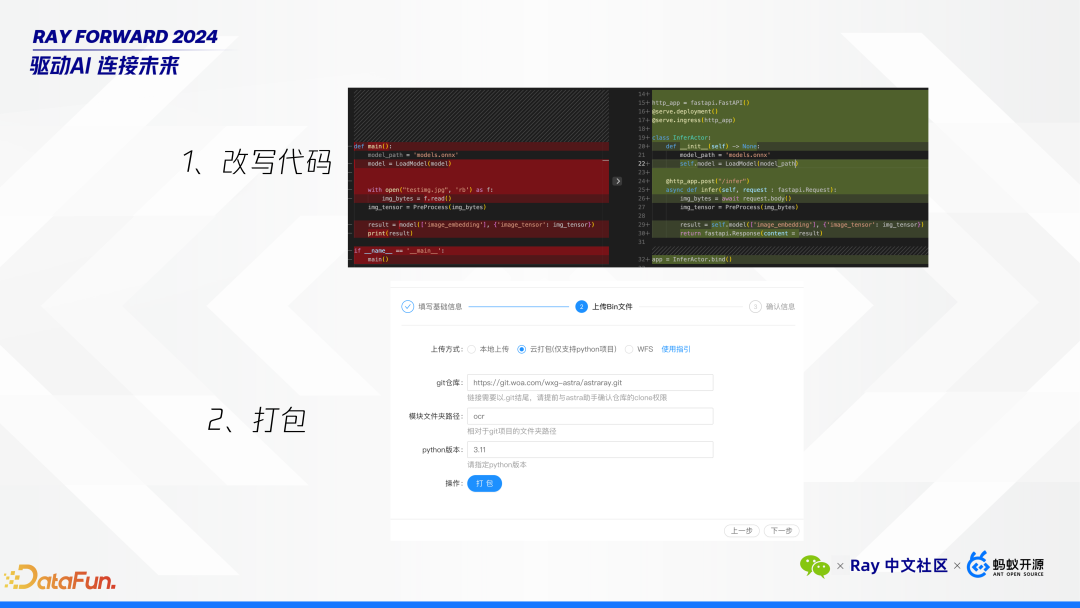
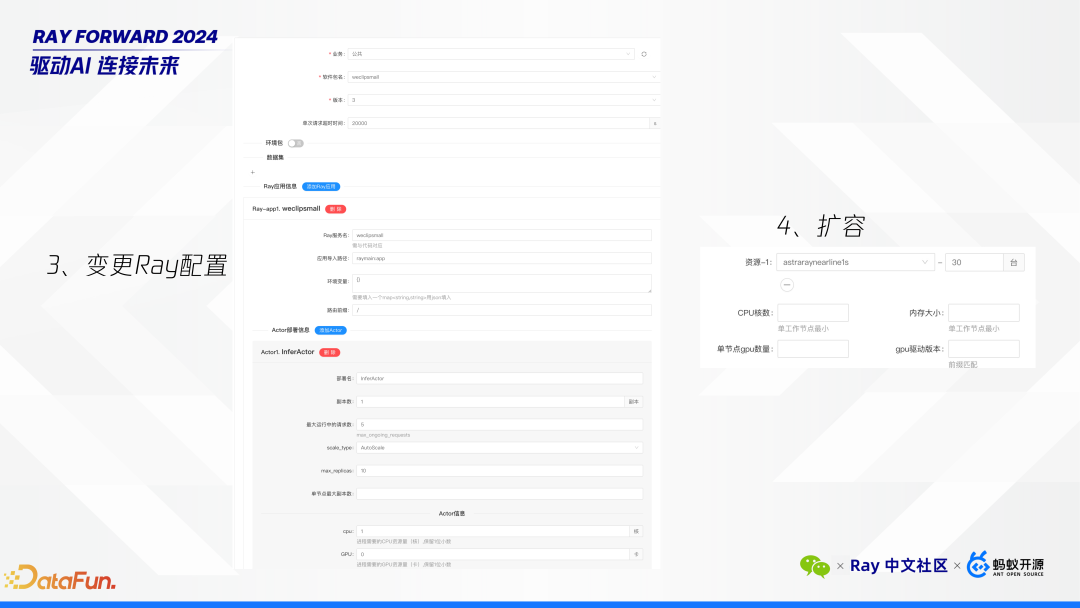
-
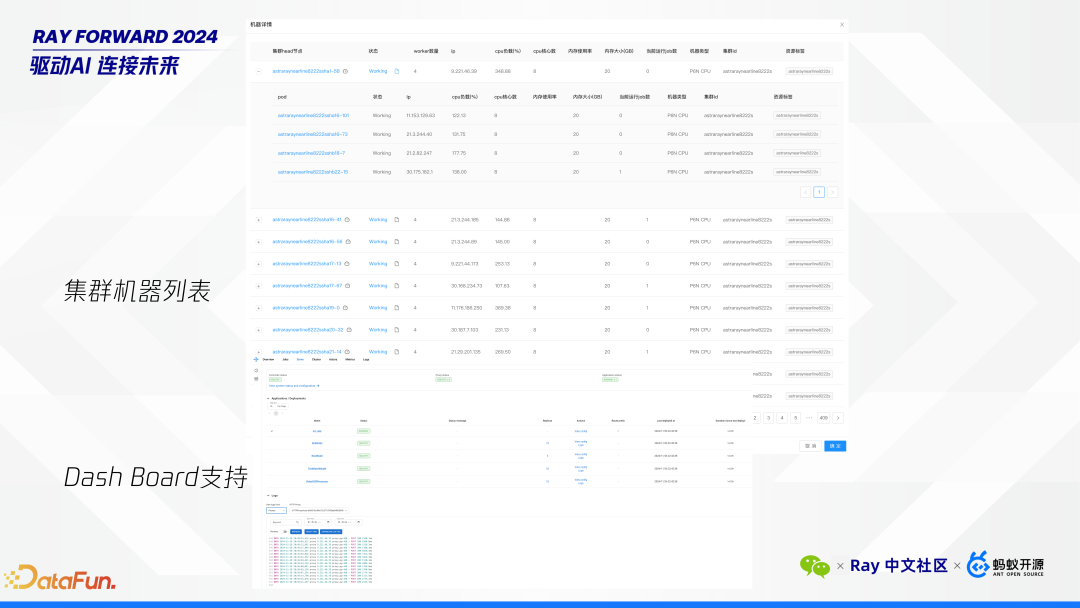
Ray Dashboard:用户可以通过 dashboard 查看请求的状态和性能指标。
-
日志调试:平台支持日志记录和调试功能,帮助用户快速定位和解决问题。
Q&A

往期推荐

点个在看你最好看
SPRING HAS ARRIVED