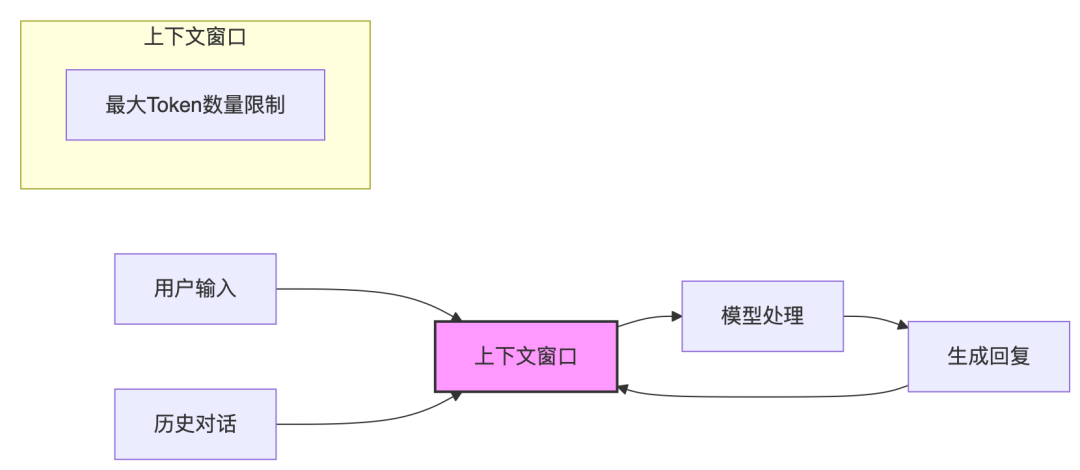
-
Embedding(嵌入):首先,输入的文本会被转换为向量表示,即嵌入过程。这一步将文本中的词汇或短语映射为高维向量,以便模型能够处理和理解。 -
Decoder(解码):接下来,解码器会基于嵌入的向量进行处理,生成下一个词的概率分布。解码器利用注意力机制和其他模型结构,预测下一个最可能的词。 -
Sampling(采样):最后,从解码器生成的概率分布中进行采样,选择一个具体的词作为输出。这一步决定了最终生成的文本内容。

二、大模型推理核心技术
1. 基础架构与优化技术
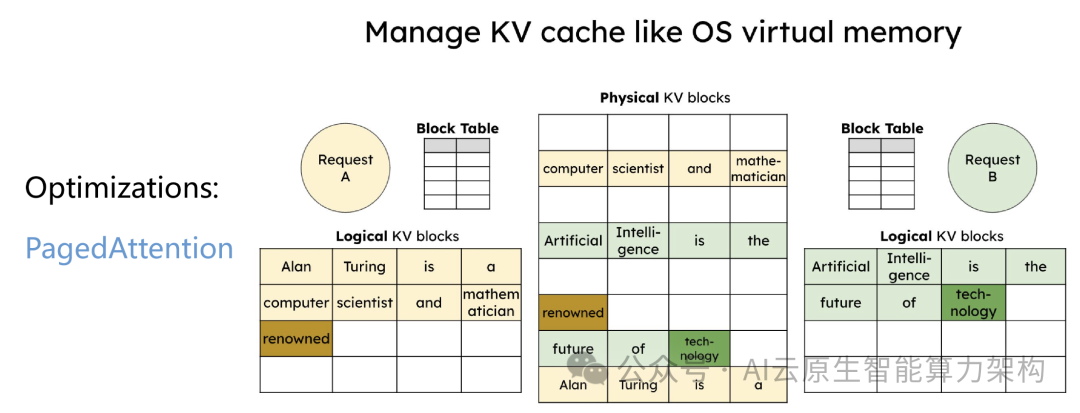
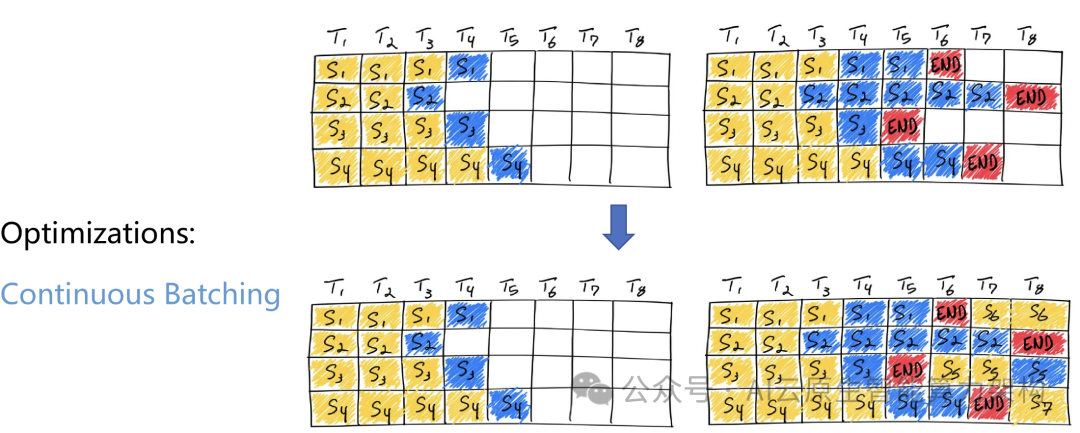
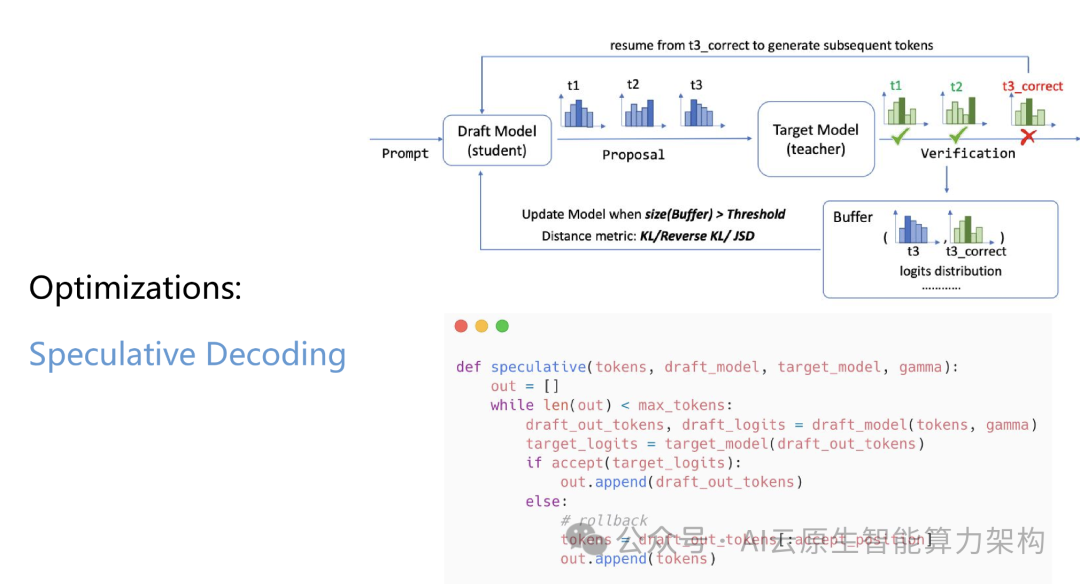
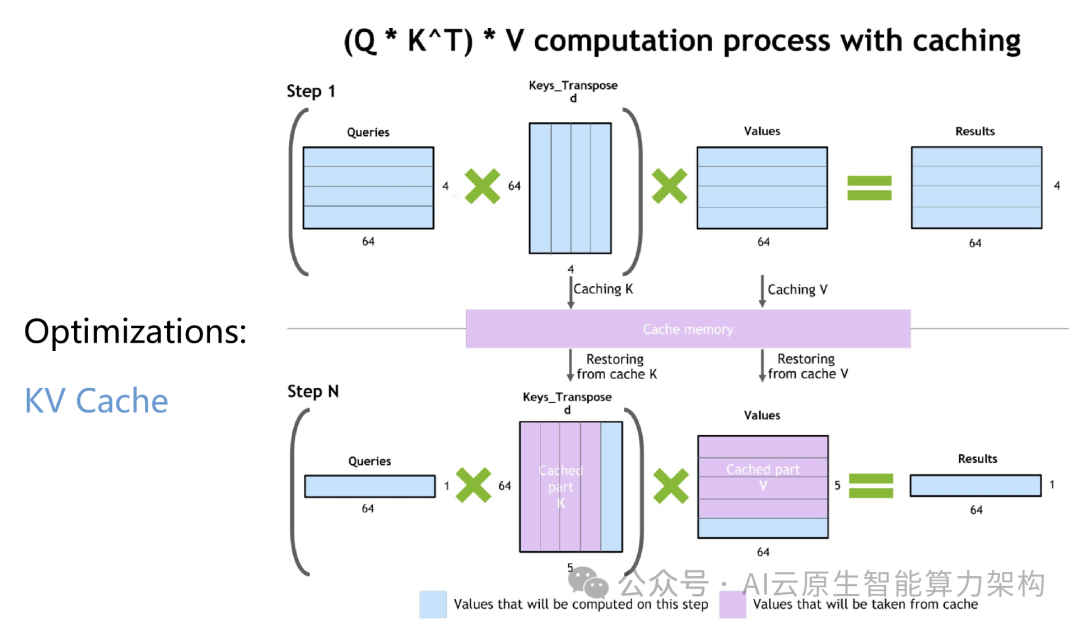
2. 推理引擎与工具链

框架对比:
三、大模型推理现状与挑战
1. 行业痛点
2. 产业趋势
四、Xinference:企业级推理与部署平台
1. 核心能力
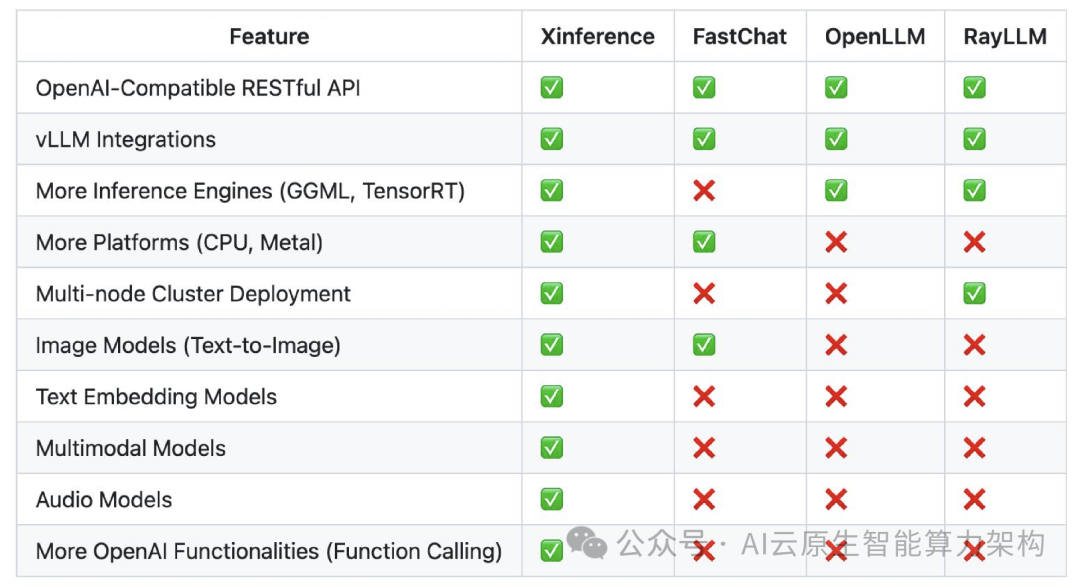
2. 生态整合
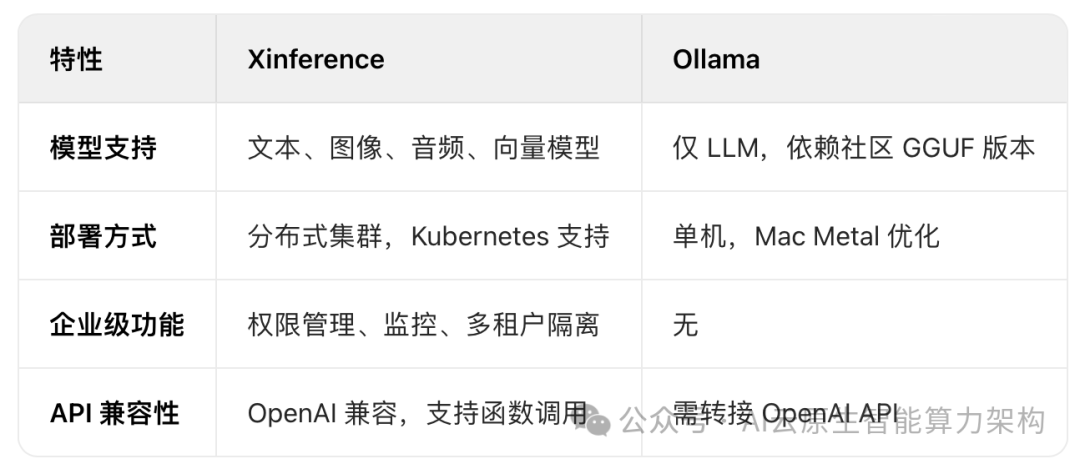
3. 优势对比
4. 典型案例
四、未来展望
多模态扩展:支持 ComfyUI,提供端到端语音能力。
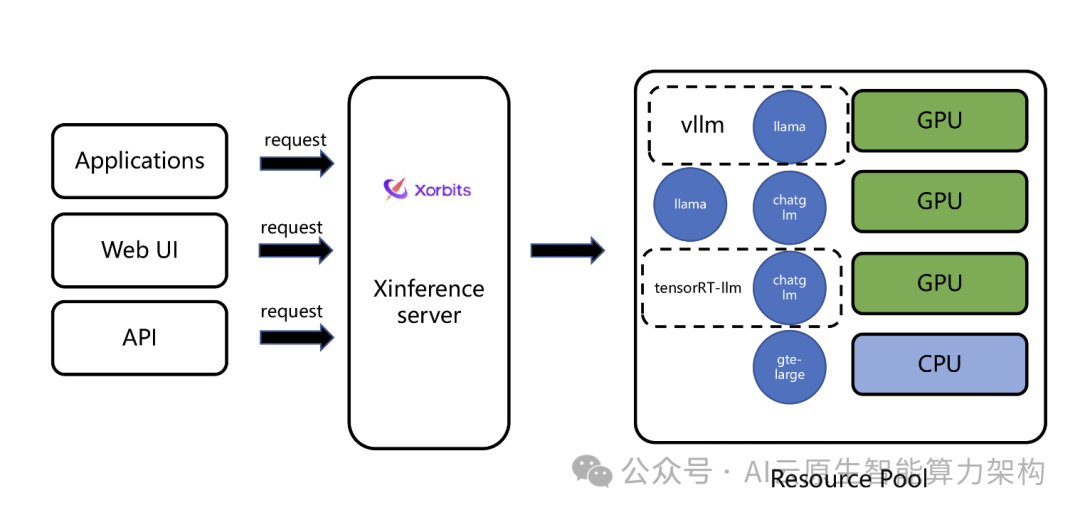
大模型推理面临 “效果 – 性能 – 成本” 的三角挑战,Xinference 通过分布式架构、多引擎支持和企业级特性,提供了从个人部署到企业级应用的全链路解决方案。
其生态整合能力和国产化适配,使其成为 AI 基础设施的核心选择。
未来,随着多模态和实时推理需求的增长,Xinference 将持续推动大模型落地的效率与灵活性。
GitHub: https://github.com/xorbitsai/inference


-
突发!百度放大招!文心大模型 4.5 Turbo发布!2025 -
突发!OpenAI 预测到 2029 年营收将达到 1250 亿美元,超过英伟达和 Meta !2025 -
突发!Meta发布开源大模型Llama 4 !2025 -
突发!英伟达 H20 芯片全面禁售深度分析! 2025
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END