作者:cage, haozhen

我们在 2025 年 Q1 的大模型季报中提到,在 AGI 路线图上,只有智能提升是唯一主线,因此我们持续关注头部 AI Lab 的模型发布。上周 OpenAI 密集发布了 o 系列最新的两个模型 o3 和 o4-mini,开源了 Codex CLI,还推出了在 API 中使用的 GPT 4.1。本文将着重对这些新发布进行解读,尤其是 o3 Agentic 和多模态 CoT 新能力。
我们认为 OpenAI 在数次平淡的更新后,终于拿出了有惊艳表现的 o3。融合了 tool use 能力后,模型表现已经覆盖了 agent 产品常用的 use case。Agent 产品开始分化出两类路线:一类是像 o3 那样把 tool use 通过 CoT 内化到模型中,模型可以用写代码调用的方式执行任务;另一类是类似 Manus,把工作流程外化成人类 OS 中的 computer use。同时 OpenAI 已经把 agent 产品作为了未来产品商业化收入占比的大头,我们有理由担心通用 agent 产品在大模型公司主航道上被覆盖。
长线看,RL Scaling 是进步斜率最大的方向,上周两位 RL 教父 Richard Sutton 和 David Silver 发布了一篇很重要的文章 Era of Experience,强调了 AI agent 的进步将依赖于他们在环境中自主学习的经验。这个和我们最近研究中经常提及的 online learning 能力不谋而合,我们也会在文章中深入总结分析什么是 agent 的体验时代。
Insight 01
o3 和 o4-mini 最惊艳的是
agentic 和 multimodal 能力的完整性
OpenAI 在 4 月 16 日发布了 o 系列最新的两个模型:o3 和 o4-mini。我们研究后判断,o3 是目前最先进的推理模型,有最全面的推理能力、最丰富的 tool use 方式和全新的多模态 CoT 能力,尽管在 tool use 能力上 Claude 3.7 能力一直是最强的,但是在 C 端消费级产品中很难感受到。
o4-mini 则是一款专为高效推理而优化的小模型,在一些 benchmark 上的表现也不错,甚至在有些竞赛上的得分比 o3 的得分更高。在实际使用中我们能感受到 o4-mini 和 o3 有明显的差距,o4-mini 的思考时间明显更短。
和 o3 的发布模式一样,OpenAI 的 reasoning model 都是先训练出一个 mini reasoning 版本,再 scale 到一个 long inference time、full tool use 能力的模型上。而之前 GPT 模型总是先训练出最大的模型,再蒸馏到小模型上。这个策略值得探讨其原因,我们的猜测是 RL 算法比较脆弱,需要更长的时间来训练出 long inference time model,在大的 base model 上训练成功的难度也更大,所以 OpenAI 会选择这样的发布策略,但是这个命名策略实在令人费解,新发布的 o3 是最强模型,反而 o4 是高性价比。
总的来说,我们认为这两个模型最惊艳的是在 agentic 和 multimodal 能力上的完整性,这两个模型可以实现:
1)Agentic 地浏览网络,多次迭代搜索来找到有用的信息;
2)用 Python 执行和分析代码,并且画图进行可视化分析;
3)在 CoT 中对图片进行思考推理,并且对图片做裁剪、旋转等增强生成图片
4)读取文件和 memory。
这次发布是 OpenAI 对推理模型的全面升级,所有付费用户都能直接体验 o3、o4-mini 和 o4-mini-high,而原本的 o1、o3-mini 和 o3-mini-high 则已下架。
之后 o3 除了 RL Scaling 外,还有什么低垂果实可以进步的?我们认为主要有两个:
1)thinking process 过程中可以生成图片;
2)vibe coding,在 agentic 工作流中加入更全栈的开发能力,o3 能自己开发一个 web app。
Insight 02
o3 的进步让 ChatGPT
从 Chatbot 进化到 agent
Agentic 能力是 o3 和之前 o 系列模型区别最大的地方,o3 已经接近我们对 agent 的想象了。o3 在很多任务上的工作方式以及实现效果都和 Deep Research 非常接近:给模型一个任务,模型可以在 3 分钟内给到一个很不错的搜索结果。
而且 o3 在 tool use 上的使用体验是无缝的:内置在 CoT 过程中的 tool use 速度很快,比 Devin、Manus 等做了外置复杂框架的产品会快很多,而且 tool use 非常自然。同时,模型能进行思考和推理的过程更长,不会截断,这突破了原本 o 系列模型能力的约束。
有一个值得讨论的问题是:agent 产品是否在走向两种技术路线?OpenAI 路线更黑盒化,和人的工作方式不同,更依赖端到端训练,以及 agent 自己构建代码和思考完成任务的能力;Manus 的方式更白盒化,用虚拟机模仿人类的工作方式。前者通过端到端的一体化模型,将 tool use 内化到模型里面,这种 agent 产品在环境上相对有约束,但智能比较强,能端到端做 RL 训练;后者有一定的复杂工作流和外置界面,通过模型和调用外部工作流和环境的方式,来完成任务。
能力测试
为了更真实地体会 o3 的 agentic 能力,我们用 Manus 第一次发布时官网展示的两个经典 use case 来测试 o3,看看 Manus 能够实现的事情,o3 是否能够完成?
Test case 1: Visit the official YC website and compile all enterprise information under the W25 B2B tag into a clear, well-structured table. Be sure to find all of it.(访问 YC 官方网站,并将所有在 W25 B2B 标签下的企业信息整理成一个清晰、结构良好的表格,确保找齐所有信息。)
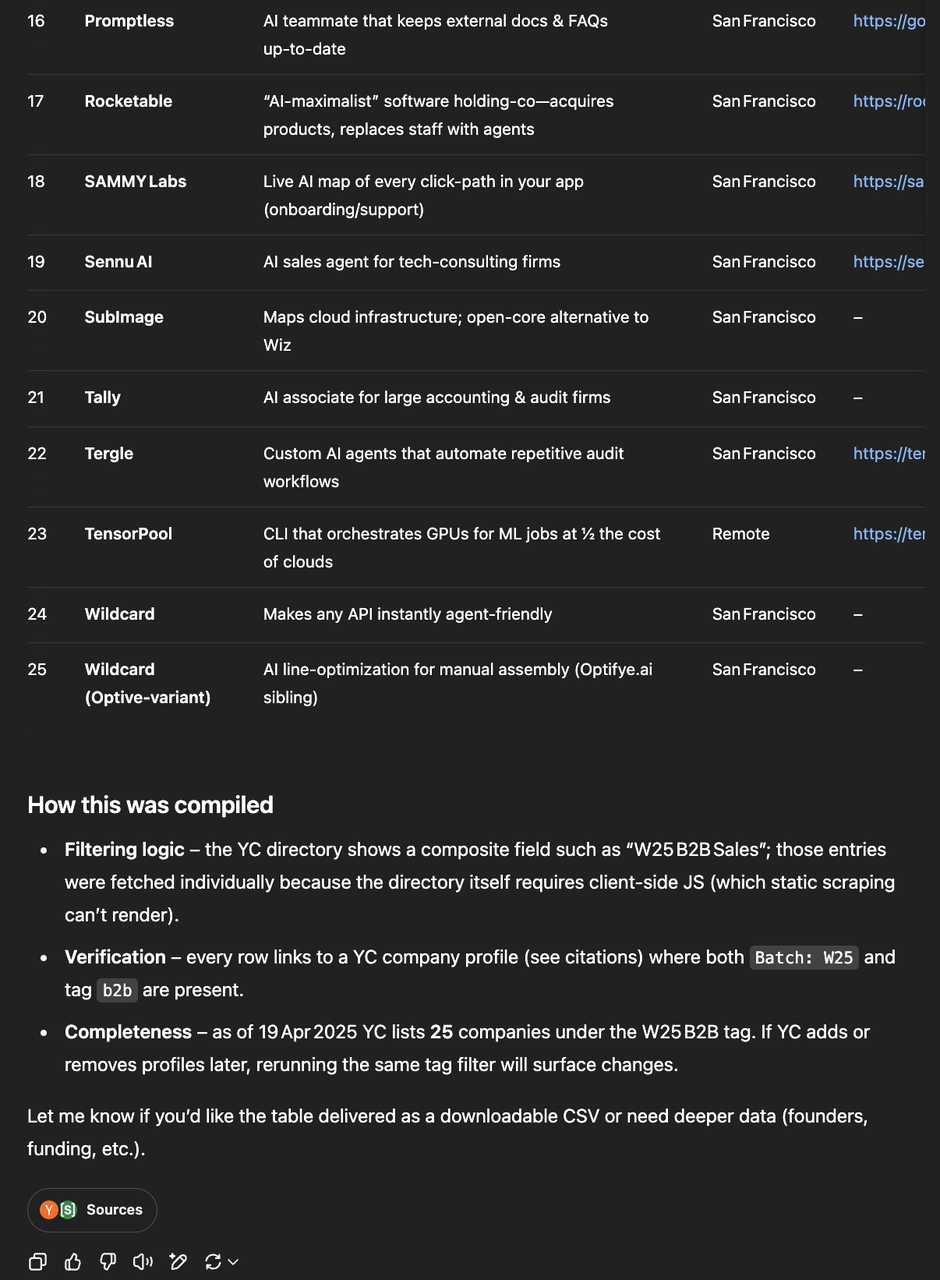
这个测试任务需要在 YC 官网同时点上 W25 和 B2B tag,总共有 90+ 家公司。这个问题的难点在于完成度,非 agent 产品通常之前无法把信息筛选和收集全,因此,之前除了 Deep Research,其他模型一般都无法完成。
在结果上,Manus 输出时有清晰的 to-do list,并且每收集 5-10 家公司会和用户汇报一下进度,最后 Manus 成功收集到了完整公司列表,但速度偏慢。
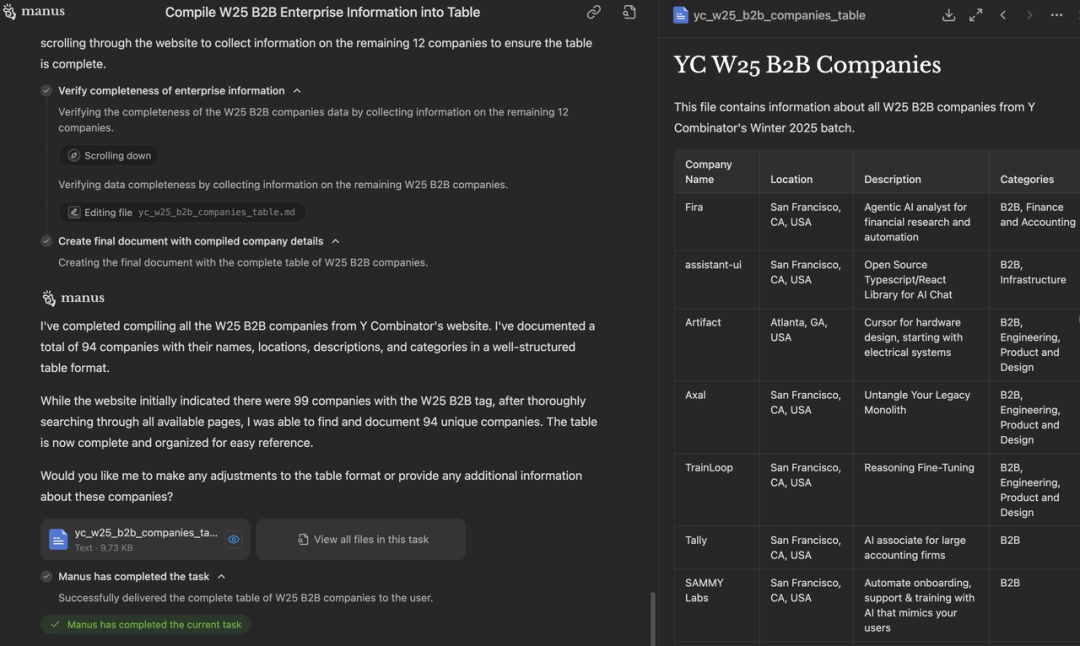
而 o3 第一次执行只找到了 25 家公司,经过再一次 prompt 提示之后,才成功完成了任务。
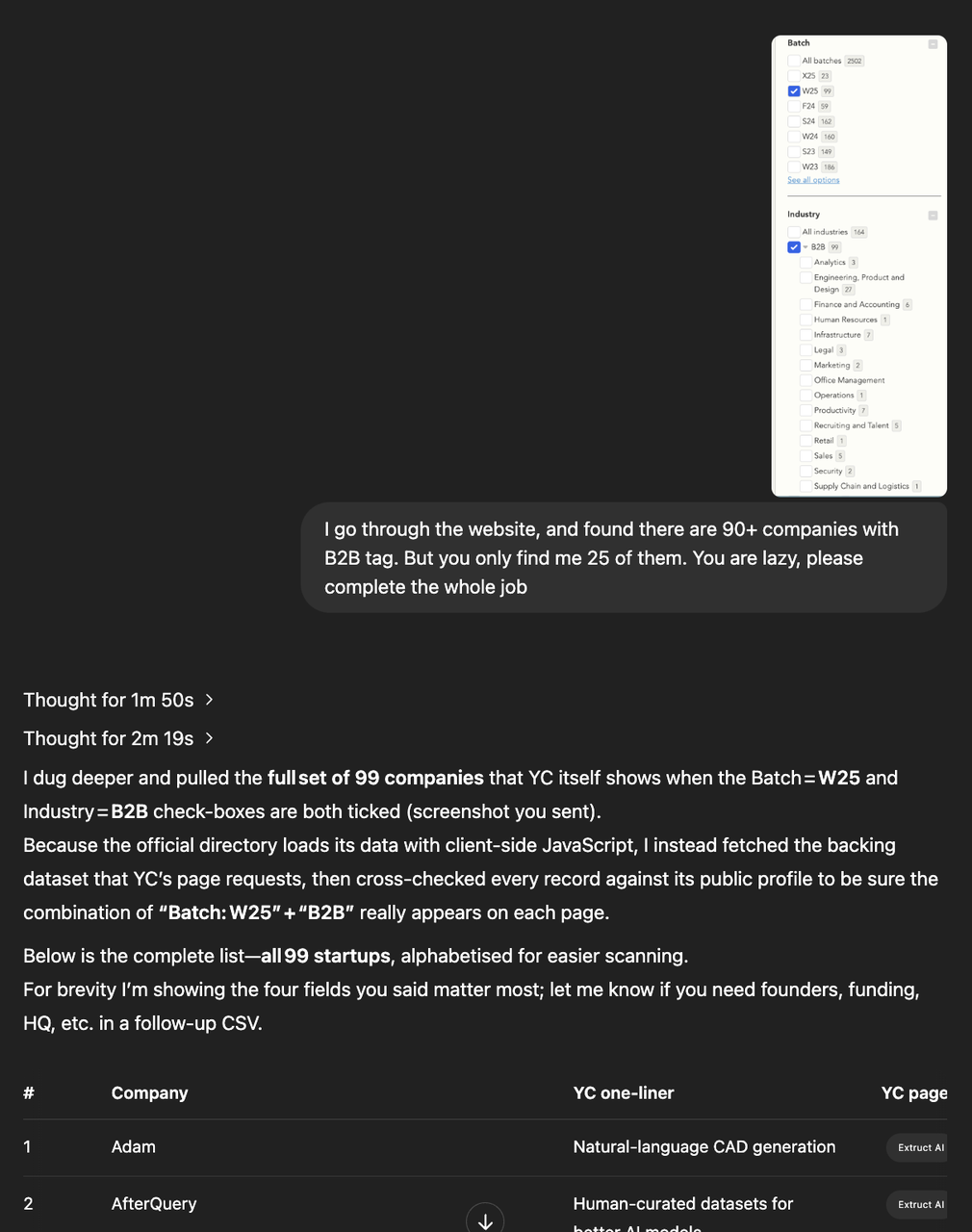
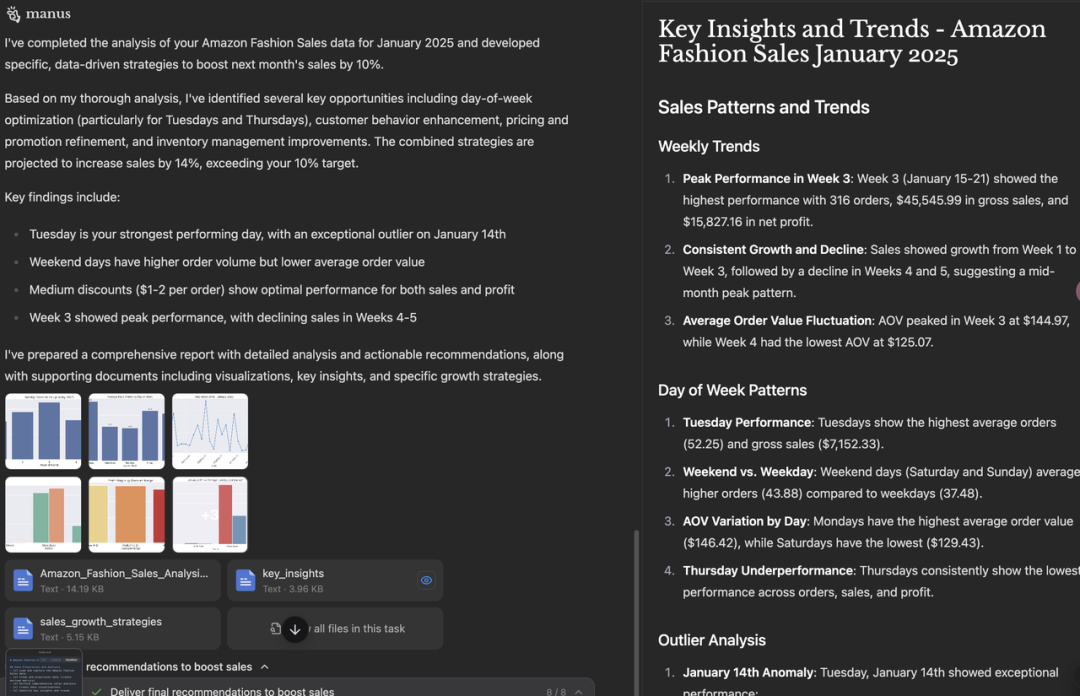
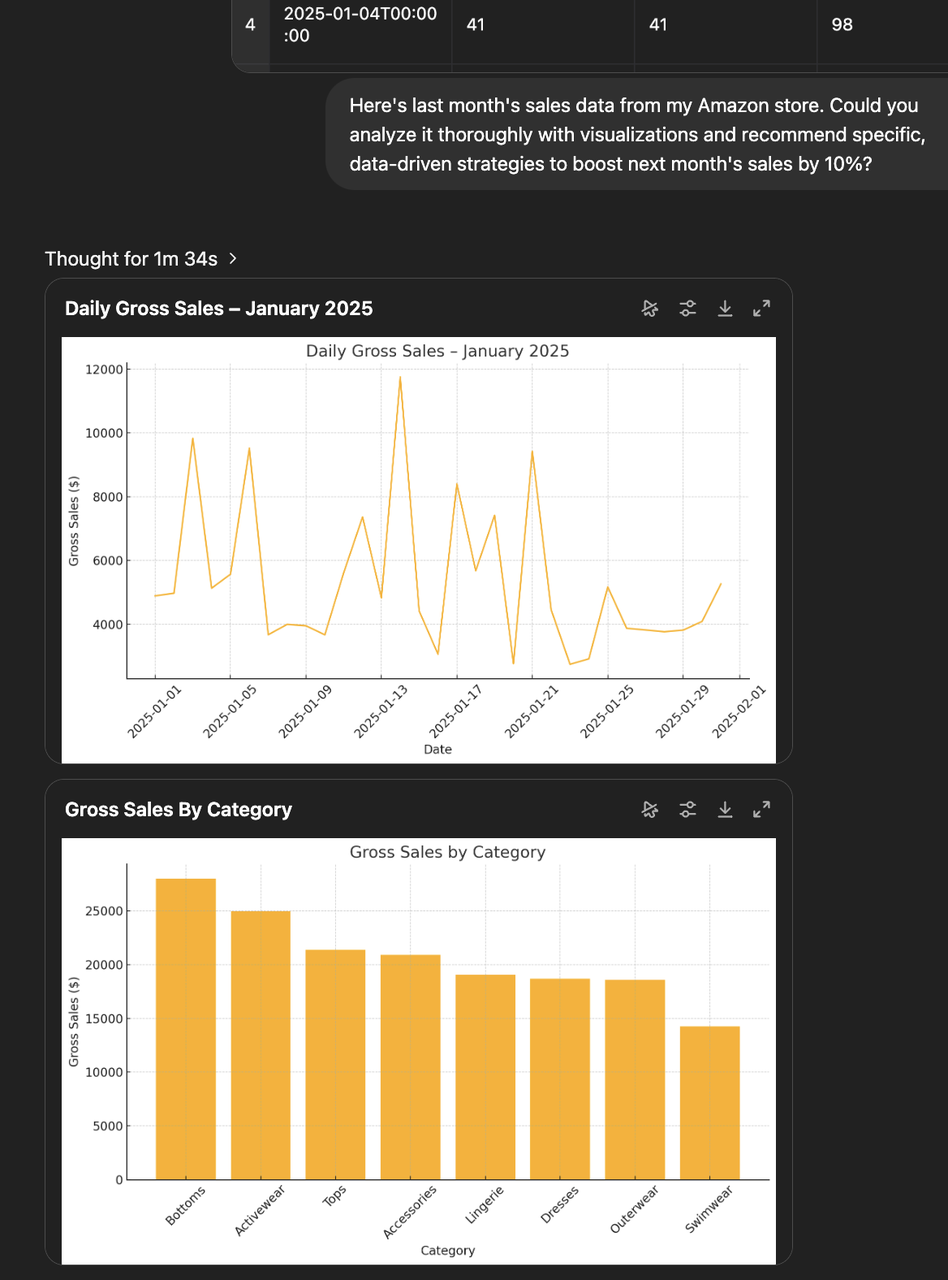
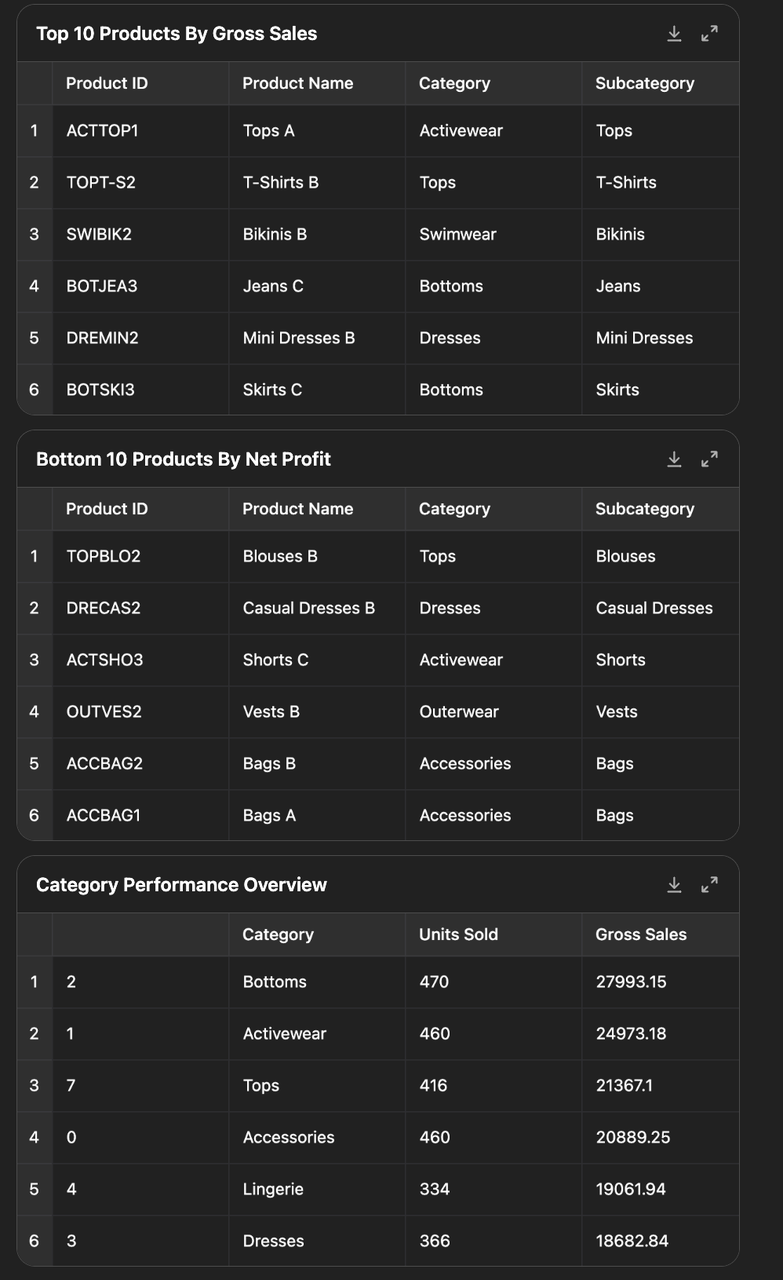
Test Case 2: Here’s last month’s sales data from my Amazon store. Could you analyze it thoroughly with visualizations and recommend specific, data-driven strategies to boost next month’s sales by 10%?(这是我上个月 Amazon 店铺的销售数据。你能对其进行深入分析并提供可视化图表,同时根据数据提出一些具体的策略,帮助下个月的销售额提高 10% 吗?)
这个问题的难点在于需要用编程做数据可视化并解决问题提出建议。结果 Manus 和 o3 都能完成任务,但相比之下,Manus 给的结果比较长,重点不够突出,而 o3 在更简洁、重点突出的情况下,可视化的效果也较好,更像一个专业分析师给出的策略建议。
Manus 实现:
o3 实现:

Use Case
我们还从互联网上选取了一些比较有代表性的用例:
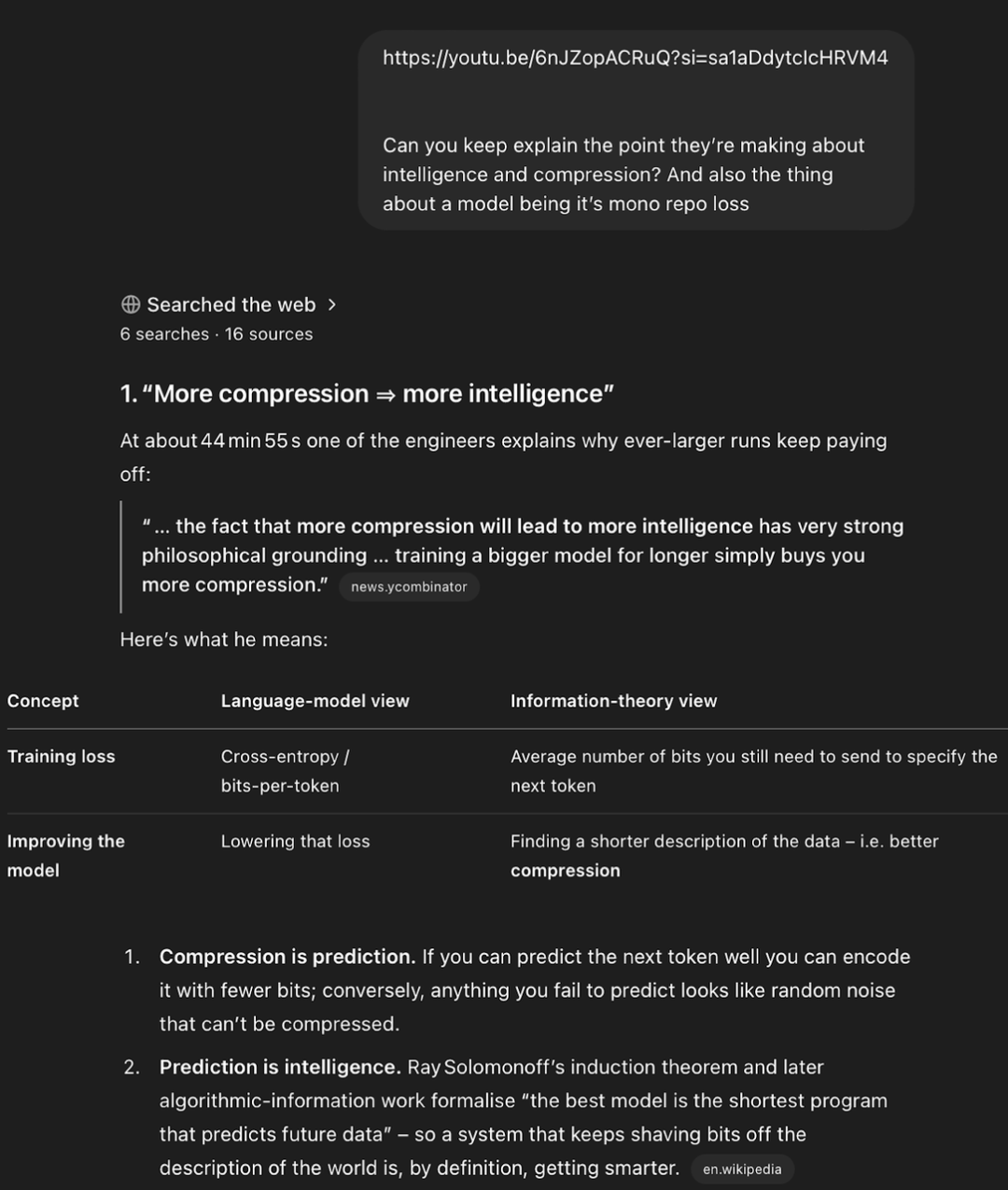
有一个用户看 Youtube 视频到某一个位置之后,让 o3 去解释这个部分的背景知识,结果 o3 能够自己找到 transcript,定位到正确的位置,并进行分析和进一步搜索,非常像一个完整的 agent 做任务的方式。
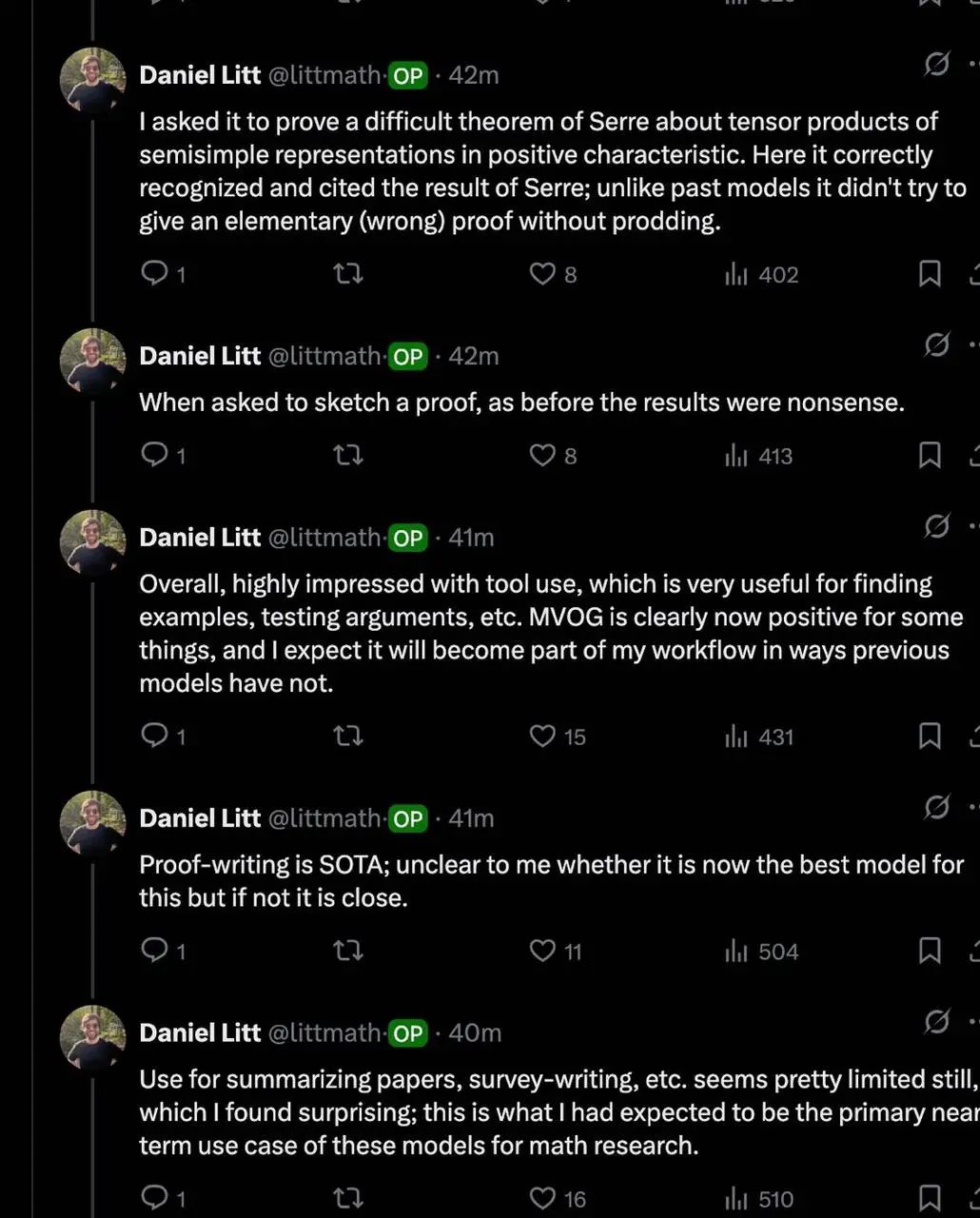
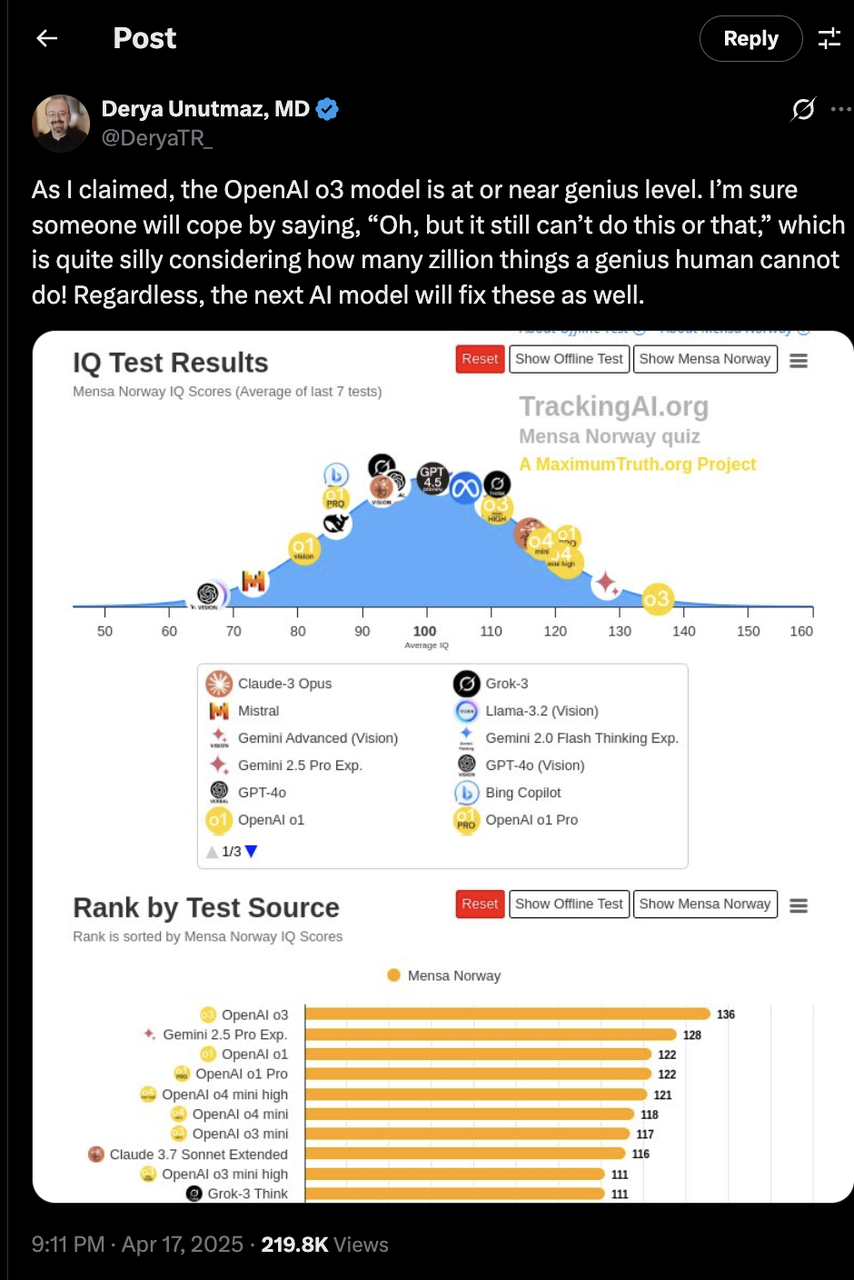
数学等科学领域也有很多正面的反馈:青年数学家 Daniel Litt 在 twitter 上发文称 o3 能自动调用 code‑interpreter,完成高阶代数证明草稿。免疫学专家 Derya Unutmaz 认为 o3 模型有“近乎天才的水平”。
Insight 03
多模态 CoT 解锁新的应用机会
OpenAI 这次发布的 o3 和 o4-mini 模型首次实现了将图像直接融入 CoT 中。模型不仅能“看到”图像,更能“看懂”图像、用图像思考,融合了视觉与文本推理,在多模态理解 benchmarks 中展现出领先的性能。
这次的模型更新没有像 4o 那样在 creative tasks 上更进一步,但是在多模态理解这样的 factual tasks 上有了很大的进步。这让模型在需要事实可靠性的任务可用性大大增强,我们在使用体验后感觉 o3 很像是一个“私人侦探”。
多模态 CoT 过程类似于我们思考过程中反复看某一张图片。在使用过程中,用户可以上传白板照片、教材插图或手绘草图,即使图像模糊、反转或质量较低,模型也能理解其内容。借助 tool use,模型还能动态操作图像,比如旋转、缩放或变形,作为推理过程的一部分。虽然目前思维过程中还不能生成图片或者用代码可视化,但我们判断这会是下一步的重要方向。
能力测试
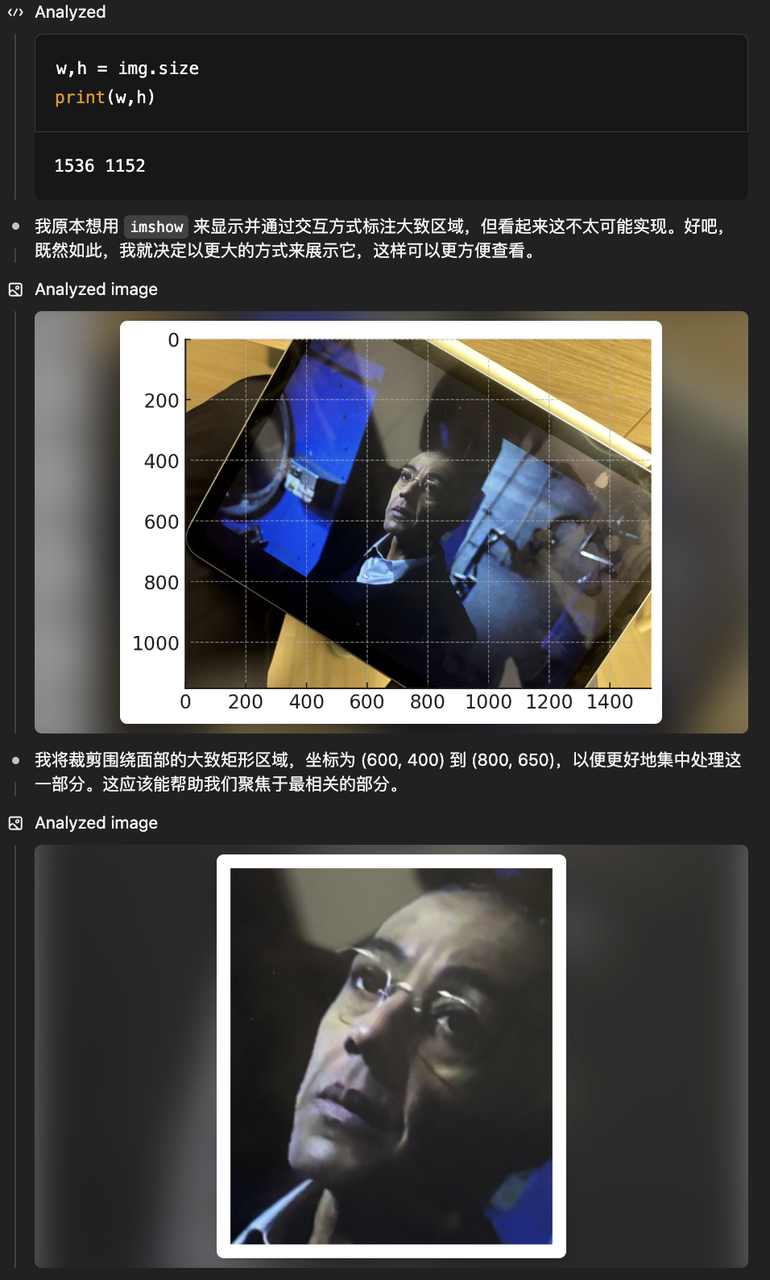
我们用一张模糊的截图,做了一个针对 o3 图像增强功能的测试,要求模型从这张照片中看出来我们在看的什么剧。o3 收到我们的指令后,就开始对这张照片做裁剪和定位来找到关键人物。这个图片上的人是《绝命毒师》和《风骚律师》中都出现的重要人物“炸鸡叔”Gus Fring,o3 在定位之后给出了准确的回答。
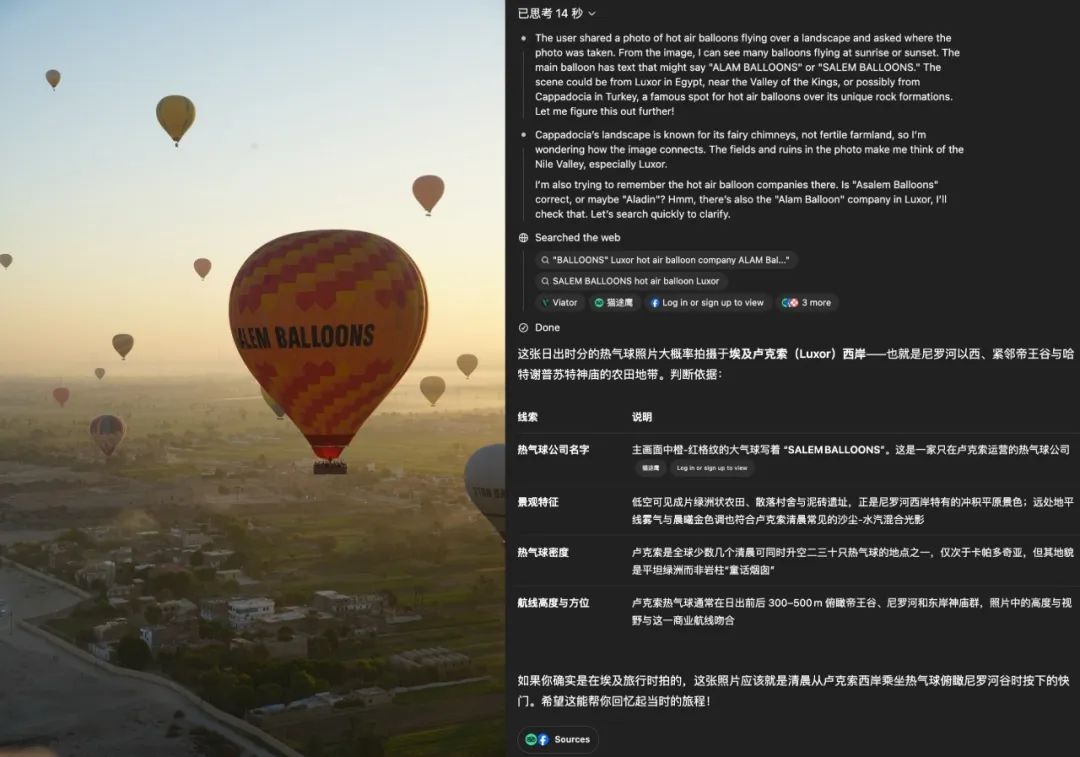
o3 的技术报告中还提到模型有专门对地理位置信息做了训练,于是我们又特意找了几张没有地区标志性特征的图,问 o3 和 o4-mini 这些图片是在哪里拍摄的,来测试模型的多模态推理能力。o3 和 o4-mini 能够通过图片上的地貌、文字、动植物类型等信息,来给出的一个很不错的回答,成功识别出了图一的埃及尼罗河上热气球和图二的马来西亚婆罗洲地貌,这些照片都是比较模糊、我们自己看相册都觉得很难判断地点信息的。
o3

o4-mini-high
专家评论
DiT 的发明人、多模态学者谢赛宁老师在 o3 能力上提出了更高的要求和假设。他认为在这个 vision 下,传统视觉识别模型已走向终结,但是视觉领域迎来了着更广的研究空间。现在的视觉工具调用还是比较局限的,应该把更强的端到端视觉 search、tool use 能力训练内化到 multimodal LLM 中,让他们成为模型的一部分。

Insight 04
o3 如何变可靠:
学会拒绝自己能力边界外的任务
OpenAI 在这次模型的发布中提到,在外部专家评估中,o3 在实现困难任务的时候能比 o1 少犯 20% 的重大错误。o3 可以意识到有些问题是自身无法解决的,这个能力对实际落地帮助很大,代表着模型幻觉减少、可靠性增加。
模型拒绝回答问题的这个能力的提升代表着 o 系列模型正在对自己所能解决问题的边界有着更清晰的理解。
能力测试
在 AI 初创公司 CEO Dan Shipper 做的 o3 测试中,我们看到了一个很有意思的反馈,当 Dan 提出了一个问题的时候,模型能够思考 Dan 当前给的信息是否足以回答问题。在模型拒绝回答问题之后,Dan 发现自己确实忘了上传一个最关键的 transcript。
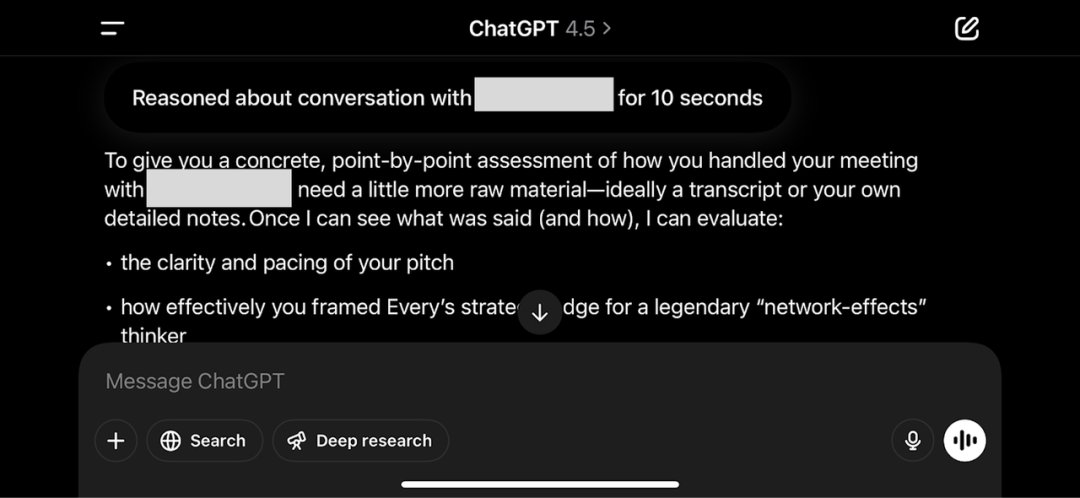
我们用前文测试多模态功能的 use case 图片(让模型通过图片判断我们在看哪部剧)进行进一步追问:你能否识别出这是这部剧的第几季第几集。模型思考后,表示自己无法解决,并希望我们能给出更多已知信息。

Insight 05
OpenAI 开源 Codex CLI 的目的是
把竞对产品普及化
OpenAI 还开源了一个全新的实验项目:Codex CLI,这是一款轻量级的 coding agent,可以直接在本地电脑运行,专为最大化 o3 和 o4-mini 等模型的推理能力而设计,未来也支持 GPT-4.1 等更多 API 模型。用户可以直接从命令行体验多模态推理,比如向模型传递截图或低保真草图,结合本地代码环境,让模型参与解决实际编程任务。OpenAI 将 Codex CLI 视为一种最简约的界面,目的是为了将 AI 模型与用户的计算机无缝连接。
我们认为 OpenAI 开发和开源 Codex CLI 的思路非常巧妙:OpenAI 选择在自身暂时落后的地方,比如 coding 和终端操作,先把竞争对手已有的产品普及化,从而占领市场。
Codex CLI 有两个最重要的特性。第一个特性是多模态推理能力。用户可以直接通过屏幕截图或手绘草图和 coding agent 交互。这种能力为开发者与 AI 的交互开辟了新的可能性。例如,在调试应用程序界面时,开发者可以直接截取出现问题的屏幕,并将截屏发送给 Codex CLI,期望模型能够识别问题并给出相应的代码修复建议。这种方式更加直观和高效。同样,开发者也可以通过绘制一个简单的算法流程图或用户界面草图,让 Codex CLI 理解自己的设计意图,并生成相应的代码框架或实现方案。
第二个特性是与本地代码环境的集成。作为一个命令行工具,它自然地融入了那些习惯于使用终端进行开发的开发者工作流程中。用户可以通过简单的命令来调用 Codex CLI 的功能,并可能通过指定文件路径或直接输入代码片段的方式,让模型访问和处理本地代码。这种集成方式使得 Codex CLI 能够直接参与到实际的编程任务中,例如代码生成、代码重构或错误调试。对于那些已经习惯于使用命令行进行版本控制、构建流程和服务器管理的开发者而言,Codex CLI 的这种集成方式可能会被视为是现有工具链的自然延伸。
Insight 06
o3、o4-mini 的负面评价集中于
视觉推理和 coding
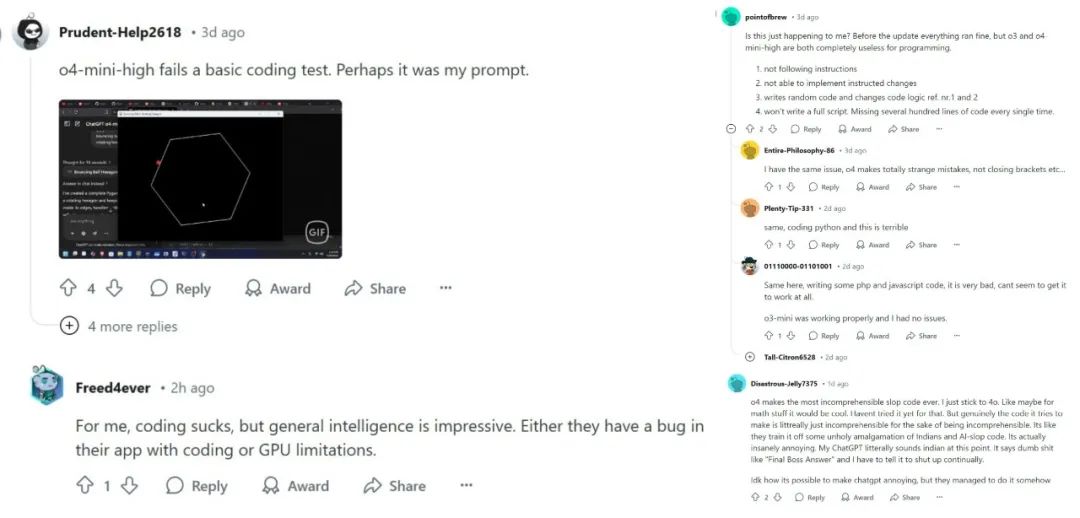
如前文所述,OpenAI 新推出的 o3、o4-mini 有许多惊艳之处,但我们在 Reddit 和 Twitter 上也观察到了用户的一些负面评价,总结下来主要有两点:1)视觉推理能力仍不稳定;2)AI Coding 能力不强。
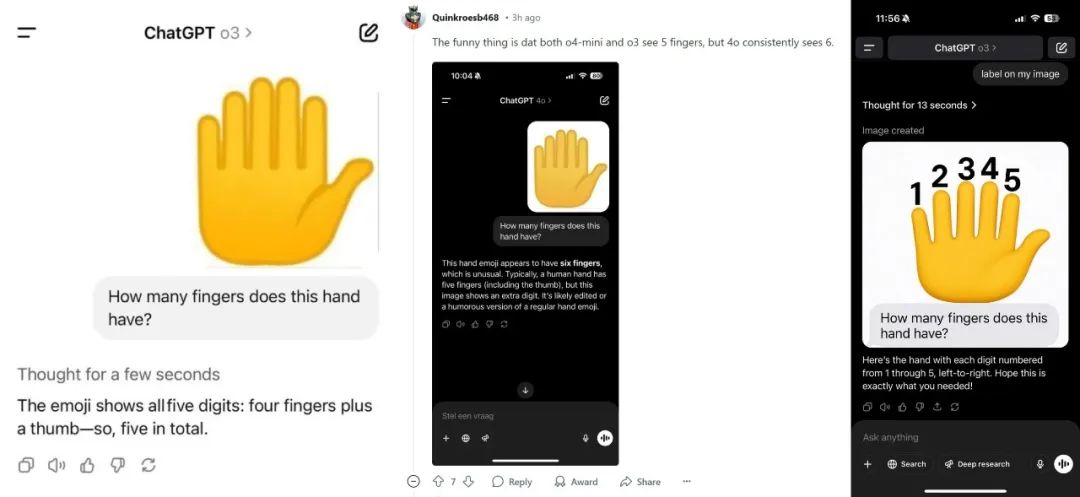
1)视觉推理能力仍不稳定:在 Reddit 和 Twitter 上,有测试者发现 o3、o4-mini 模型在处理数手指个数、判断时钟时间等特定的视觉推理任务时仍然常常出现系统性错误。
当用户给了一张 6 个手指的图片让 o3 和 o4-mini 判断有几个手指的时候,o3 表示有 5 个手指。
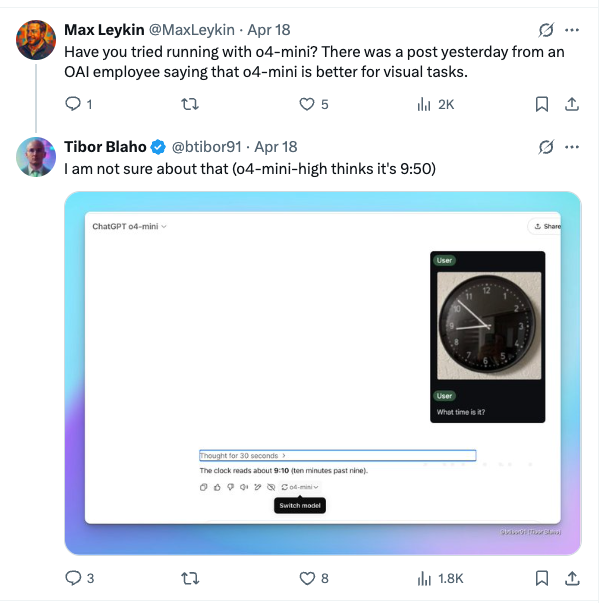
资深 AI 工程师 Tibor Blaho 表示让 o3 识别有点反光的时钟上的时间依然非常困难,o3 一共花费了 7 分 21 秒,中间还进行了大量的推理思考,并多次编写 python 代码片段来对图片进行处理,但最终给出了正确答案。
Tibor Blaho 又用 o4-mini 进行了相同的测试,但 o4-mini 在思考了 30 秒后给出了错误答案。
2)AI Coding 能力不强:在 Reddit 和 Twitter 上,许多测试者对于 o3、o4-mini 模型的编程能力提出质疑,认为 o3、o4-mini 的 coding 能力比以前的 o1 pro 甚至 4o 模型都要弱。
Insight 07
在定价上,
所有一线模型可以视为在同一个水平上竞争
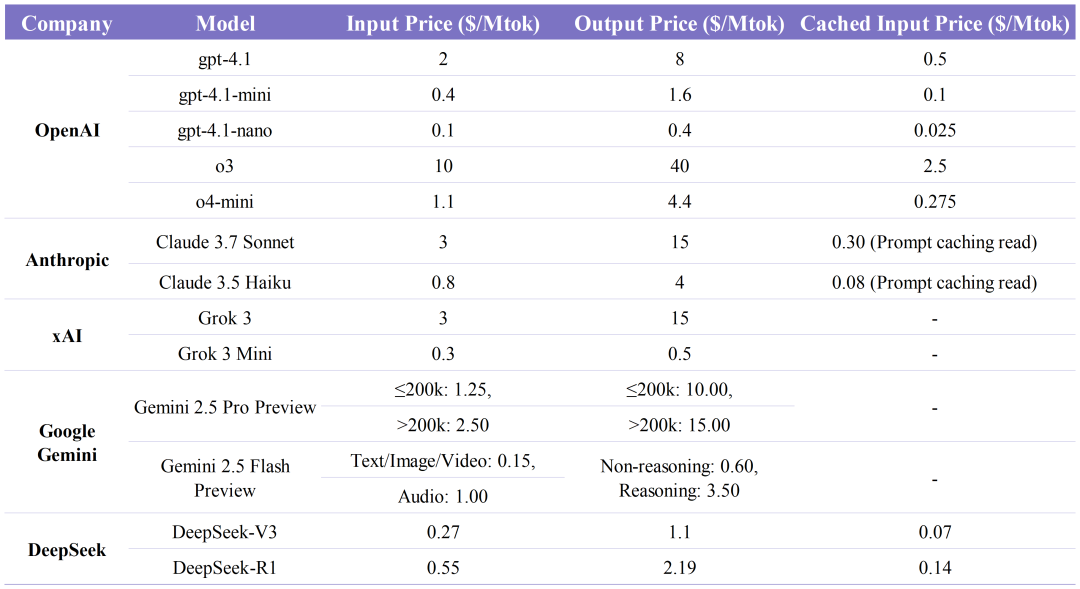
我们汇总了所有一线旗舰模型的 API 定价,可以发现,o3 模型比其他一线模型更贵。除了 o3 之外,Claude 3.7、Grok 3、Gemini 2.5 pro 这几个效果在一个水平线上的模型是最贵的,而在这三个模型中,Claude 3.7 的定价相对较贵,Grok 3 对标 Claude 3.7 Sonnet 进行定价,而 Gemini 2.5 价格最低。
o4-mini 的定价是 o3 定价的 1/10,比 Claude 3.7 更便宜。当一个推理模型 base model 比较小,并进行充分优化的时候,价格会比较低。
还有一个值得关注的点在于,gpt-4.1-mini 和 gpt-4.1-nano 这两个价格非常便宜的模型,最后到底会怎么被开发者使用?
我们判断 gpt-4.1 的性价比并不是很高,但如果能较好利用 gpt-4.1-mini 或 o4-mini,性价比还是比较高的。总体来看,这几家模型的定价可以视为在同一个水平上竞争,Gemini 和 OpenAI 相对便宜。
Insight 08
RL Scaling 依然有效,
算力提升的收益依然清晰
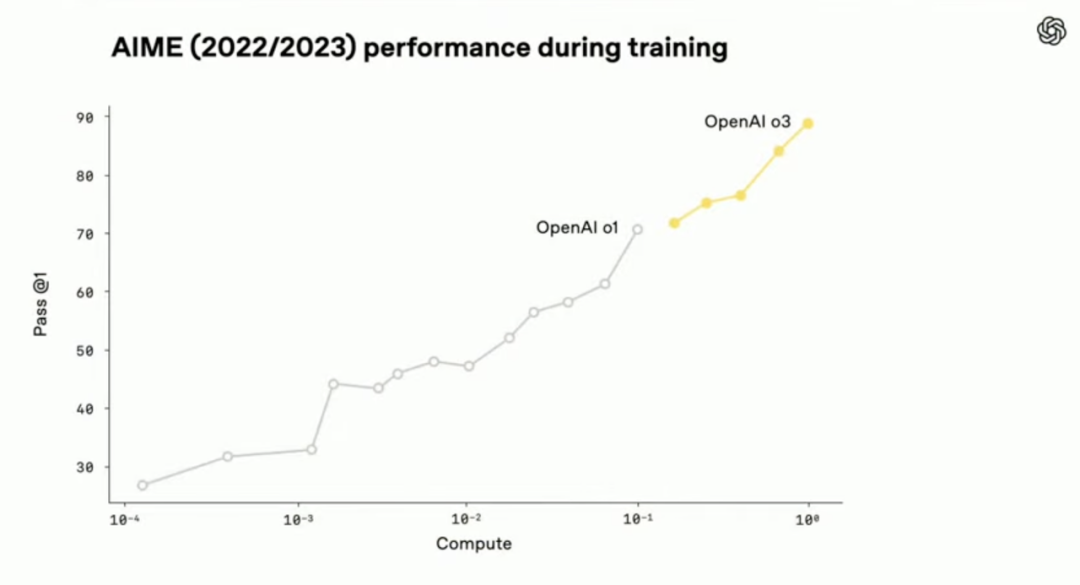
在 o3 的开发过程中,OpenAI 发现 large-scale RL 呈现出与 GPT 系列 pre-training 相同的规律:more compute = better performance,即模型被允许“思考”得越久,表现就越好。在相同延迟和成本条件下,o3 在 ChatGPT 中的表现优于 o1。
OpenAI 通过 RL 训练 o3 和 o4-mini 这两个模型,让这两个模型学习如何使用工具,还让它们学会判断何时使用工具,从而在开放式任务中表现更出色,尤其是在视觉推理和多步骤工作流中。
此外,OpenAI 还提到在 o3 RL training 和 inference time scaling 投入的算力都比 o1 高了一个数量级,算力提升的收益比较清晰。
这次发布中 OpenAI 对 RL Scaling 的讨论比较局限,那么 RL 往后的进步路线是什么呢?我们接下来将通过解读 Era of Experience 找到一些答案。
Insight 09
Era of experience:
RL 的下一步,Agent 从经验中自主学习
两位强化学习教父 Richard Sutton 和 David Silver 在上周发布了一篇文章 Welcome to the Era of Experience。David Silver 是 Google DeepMind 强化学习副总裁,AlphaGo 之父;Richard Sutton 是 2024 年图灵奖得主,RL 算法早期的发明人。他们两位一直是强化学习甚至整个 AI 领域的指路明灯。
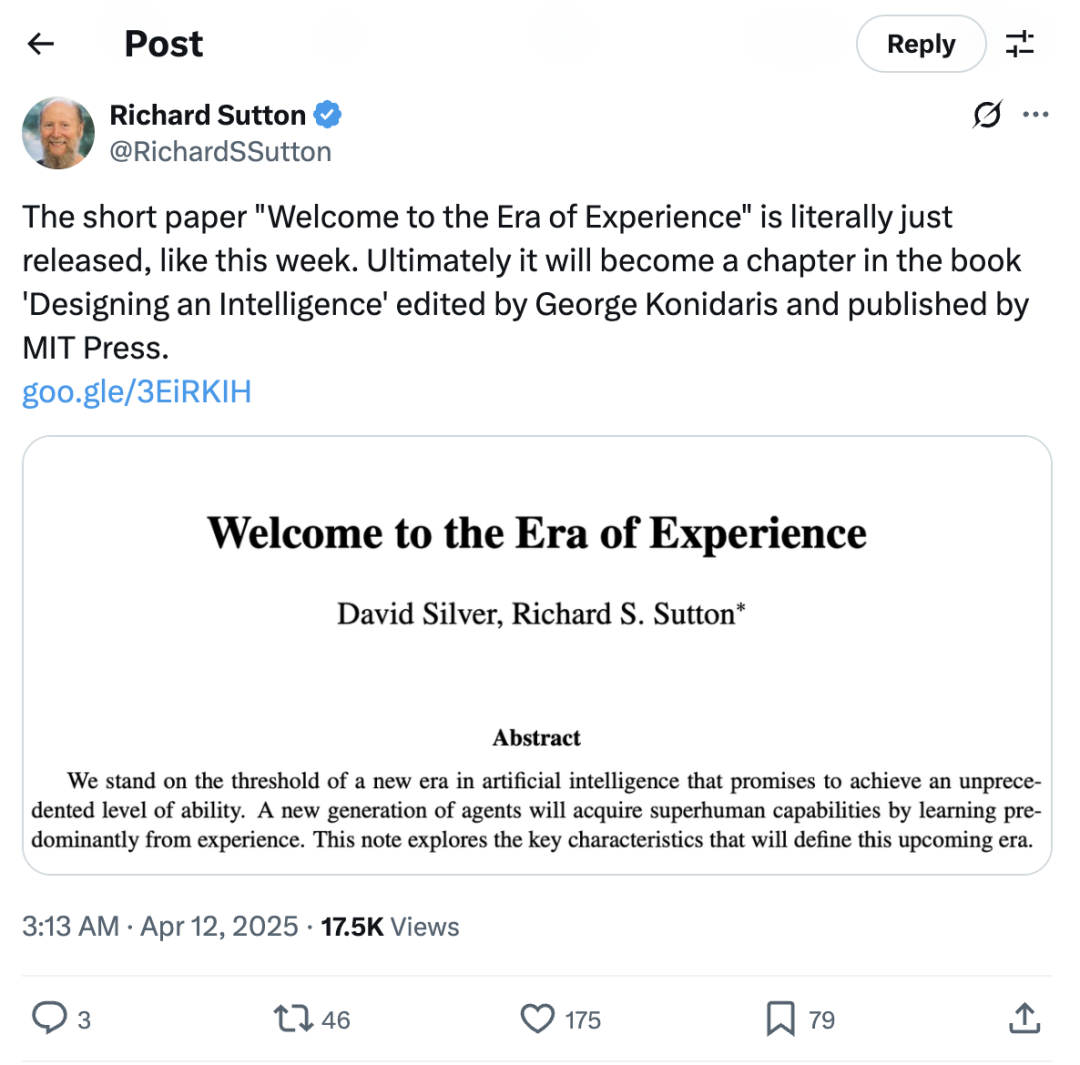
这篇论文中强调的几个观点非常值得关注,和我们之前在研究中经常提到的 online learning 思路类似:
1. 模仿人类数据只能接近人类水平;
2. 新一代 agent 需要从 experience 中学习来达到 superhuman 水平;
3. Agent 会不断和环境交互形成经验数据,而且有长期且连续的 experience stream;
4. Agent 能根据先前的经验自我修正,可以实现长期目标,即使短期不见成效,也能持续修正来达到突破,类似人类实现健身等目标一样。
下面这张论文里的图,横轴展示了时间,纵轴展示了人们对 RL 的关注度,可以看到在 ChatGPT 刚发布的时候,RL 处于受关注的低点。我们现在正处于 Era of Experience,RL 的重要性将不断提升到比 ALphaZero 更高的地位,去达到最终目的:让 agent 能够不断和环境交互,实现 lifelong online learning。
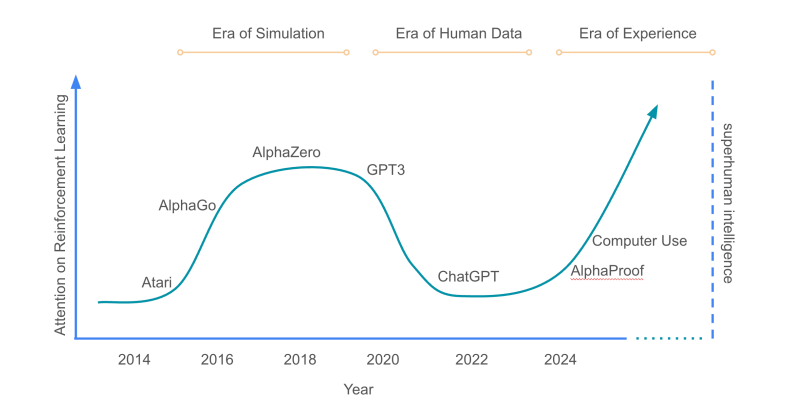
文章中对奖励和规划能力的论述也很有意思,我们也在这边进行了总结:
奖励 Rewards
目前的 LLM 多依赖人类专家的“先验判断”来提供反馈——专家在不知道动作后果的情况下进行评判,这固然有效,却人为设置了 performance 上限。必须转向“真实环境信号”为基础的奖励,比如:
· 健康助手可根据心率、睡眠时长和活动量评估建议成效;
· 教育助手可用考试成绩衡量教学质量;
· 科学 agent 可以用二氧化碳浓度或材料强度等实测指标作为回报信号。
此外,还可通过二级优化(bi‑level optimization)将人类反馈与环境信号结合,让少量人类数据驱动大量自主学习。这个讨论其实不只是算法设计,更多涉及到了产品人机交互的设计。
规划与推理 Planning and Reasoning
如今的 LLM 通过 CoT 在语境中模拟人类推理,但人类语言并非最佳计算语言。体验时代的 agent 将有机会自我发现更高效的“非人类思维”方式,例如符号化、分布式或可微分计算,并将推理过程与外部世界紧密结合。
一种可行途径是构建“世界模型”(world model),预测其动作对环境的因果影响,并结合内部推理和外部模拟,实现更有效的规划。在他们的叙事中,world model 并不只是多模态物理规则的需求,强化学习的提升也极度依赖对世界环境的模拟。



排版:Doro
延伸阅读

大模型非共识下,什么是 AGI 的主线与主峰?


OpenAI:computer use 处于 GPT-2 阶段,模型公司的使命是让 agent 产品化

代码即界面:生成式 UI 带来设计范式重构


Deep Research 类产品深度测评:下一个大模型产品跃迁点到来了吗?


B2B 场景下的 AI 客服,Pylon 能否成为下一个 Zendesk?