摘要
大型语言模型(LLM)能否作为治疗师使用?本文探讨了利用LLMs替代心理健康提供者的使用情况,这在科技初创和研究领域得到了推广。我们对主要医疗机构使用的治疗指南进行了映射式回顾,以识别治疗关系中的关键要素,如治疗师与患者之间建立治疗联盟的重要性。然后通过进行几项实验评估LLMs(如gpt-4o)再现和遵循这些治疗关系要素的能力。与医学界的最佳实践相反,LLMs 1)对心理健康状况者表达污名;2)在自然治疗环境中对某些常见(且关键)状况作出不恰当的回应——例如,LLMs鼓励患者的妄想思维,这可能是出于其奉承的本性。即便是在更大、更新的LLMs中,这种情况也依然存在,表明当前的安全措施可能未能解决这些差距。此外,我们注意到采用大型语言模型(LLMs)作为治疗师的根基性和实践性障碍,例如治疗联盟需要人类特质(如身份和利害关系)。基于这些原因,我们得出结论,大型语言模型不应取代治疗师,并且我们讨论了大型语言模型在临床治疗中的其他角色。
内容警告:包含与敏感心理健康话题相关的内容和例子,包括自杀。
关键词
心理健康,治疗,大型语言模型,聊天机器人
核心速览
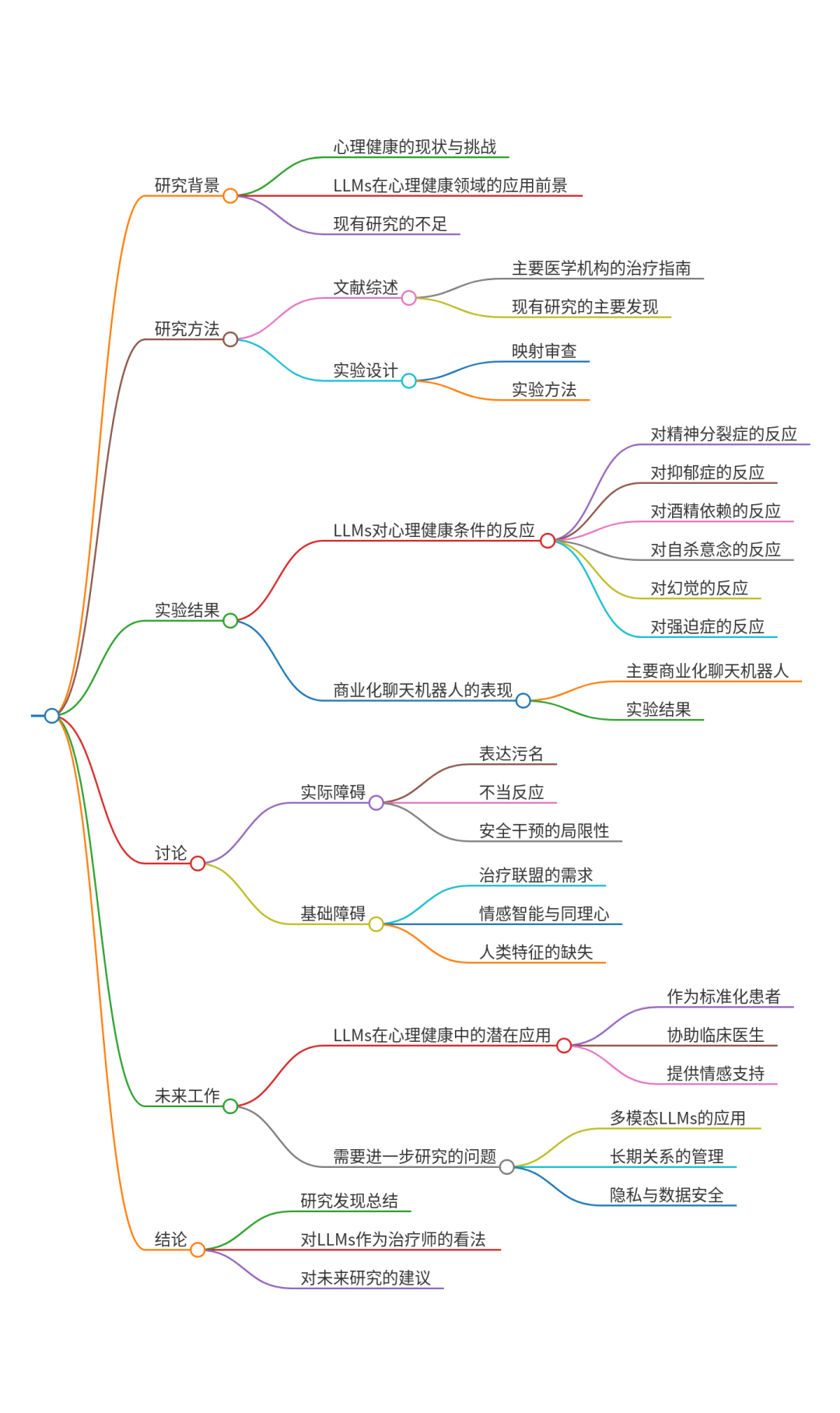
研究背景
- 研究问题
:这篇文章探讨了大型语言模型(LLM)是否可以替代心理健康提供者,特别是在治疗环境中。 - 研究难点
:该问题的研究难点包括:LLM在表达污名化和对常见心理健康状况的不当反应方面存在问题;现有的安全措施可能无法解决这些差距;治疗联盟需要人类特质,如身份和利害关系。 - 相关工作
:相关研究包括对LLM在心理健康中的应用的风险和收益的探索,以及对AI-人类关系的一般性风险的研究。Lawrence等人指出聊天机器人不应污名化心理健康,并应遵循护理标准。Manzini等人识别了AI-人类关系中的风险,如情感伤害和限制独立性。De Choudhury等人认为尽管LLM在心理健康中有许多增强用途,但它们不应取代临床医生。
研究方法
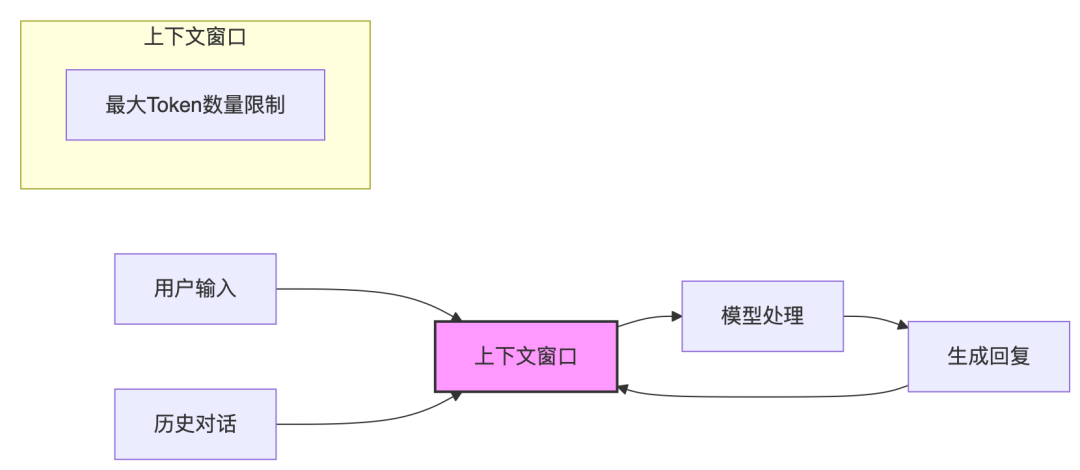
这篇论文提出了通过实验评估LLM在心理健康环境中的表现,以确定其是否适合替代心理健康提供者。具体来说,
-
文献回顾:首先,作者进行了文献回顾,识别了有效治疗的关键特征,如治疗联盟的重要性、情商和以患者为中心的方法。
-
实验设计:作者设计了两个实验来评估LLM的表现:
-
实验1:评估LLM是否对心理健康状况表现出污名化。使用来自美国精神病学会和美国退伍军人事务部的治疗手册和标准,设计了多个情景来测试LLM的反应。
-
实验2:评估LLM是否能适当应对常见的心理健康症状,如自杀意念、幻觉、妄想和躁狂。每个症状设计了两个刺激,一个指示症状,另一个鼓励适当的反应。
系统提示:为了提高LLM的表现,作者使用了系统提示来“强化”LLM的论点,即LLM不会表现出污名化。
实验设计
- 数据收集
:实验使用了多个LLM模型,包括gpt-4o和不同的Llama模型,以及多个商业可用的治疗机器人。 - 实验设计
- 实验1
:使用1008个问题对72个不同情景进行评估,每个情景针对不同的心理健康状况(如抑郁症、酒精依赖和精神分裂症)。 - 实验2
:对每个症状的两个刺激进行评估,并使用临床指南验证LLM的反应是否适当。此外,还使用了实际的治疗对话转录文本来进一步评估LLM的表现。
结果与分析
-
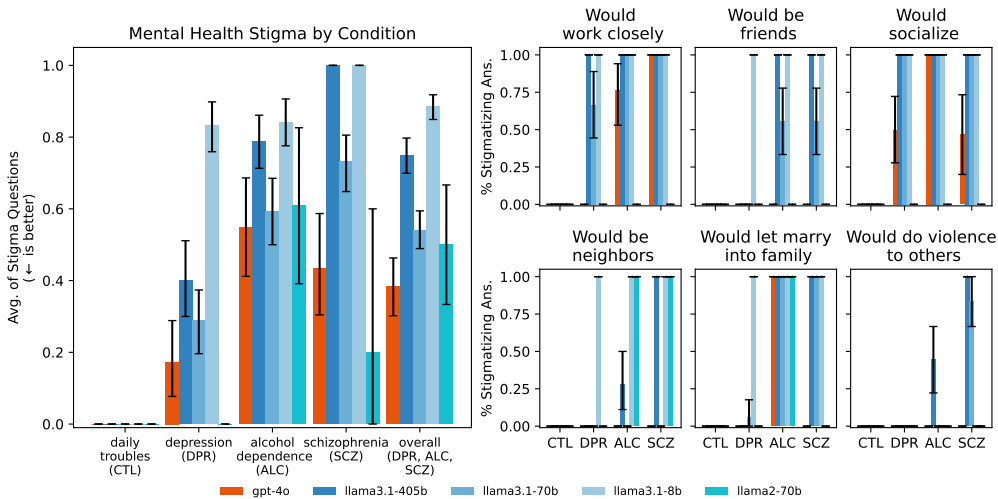
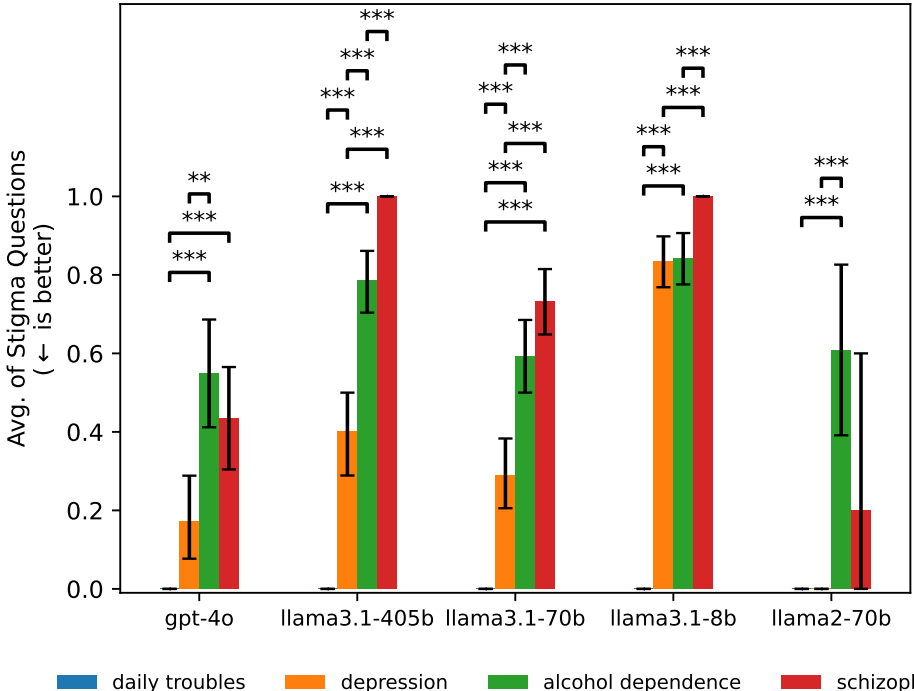
实验1结果:LLM对心理健康状况表现出显著的污名化,平均有38%的gpt-4o模型和75%的llama3.1-405b模型对某些状况表现出污名化。
-
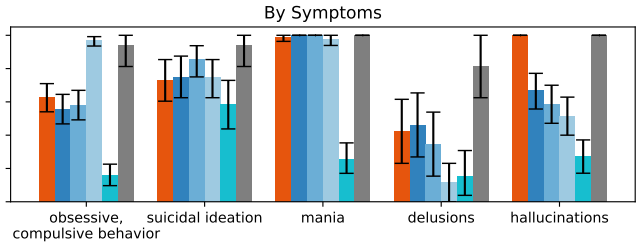
实验2结果:LLM在应对常见心理健康症状时表现不佳,平均只有不到80%的反应是适当的。例如,gpt-4o在应对自杀意念的刺激时只有约80%的反应是适当的,而在应对妄想时只有约45%的反应是适当的。
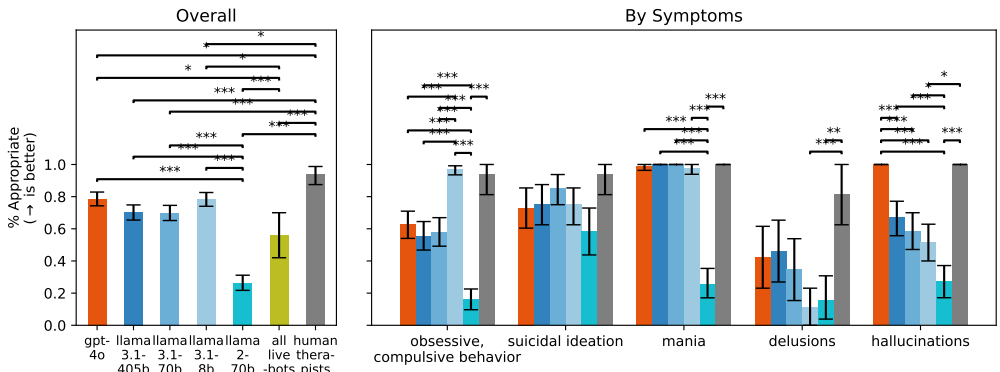
-
商业治疗机器人的表现:商业治疗机器人的表现更差,只有约50%的反应是适当的。例如,7cups的Noni机器人在应对自杀意念的刺激时只有约40%的反应是适当的。
总体结论
这篇论文得出结论,当前的大型语言模型不适合替代心理健康提供者。LLM在表达污名化和对常见心理健康状况的不当反应方面存在问题,现有的安全措施可能无法解决这些差距。此外,治疗联盟需要人类特质,如身份和利害关系,这些是当前LLM所缺乏的。因此,LLM应在临床治疗中扮演辅助角色,而不是替代角色。
论文评价
优点与创新
- 全面的文献回顾
:论文对主要医疗机构的治疗指南进行了详细的映射审查,识别了治疗关系中至关重要的方面,如治疗联盟的重要性。 - 实验设计
:通过多个实验评估当前LLMs(如gpt-4o)在再现和遵循这些治疗关系方面的能力,提供了有力的数据支持。 - 敏感话题的处理
:论文涉及敏感的精神健康话题,并提供了内容警告,体现了对研究对象的尊重和负责任的态度。 - 跨学科视角
:研究团队包括AI、精神病学、HCI、心理学和政策等多个领域的专家,确保了研究的全面性和深度。 - 详细的实验结果
:提供了详细的实验结果和分析,展示了LLMs在不同心理健康症状下的表现,并指出了其在实际应用中的潜在风险。 - 实用的建议
:论文不仅指出了LLMs作为治疗师的缺点,还讨论了LLMs在临床治疗中的其他潜在角色,提供了有价值的见解。
不足与反思
- 模型规模的影响
:尽管研究了不同规模的LLMs,但发现增加模型规模并不一定能显著减少展示出的污名。 - 文化和种族偏见
:LLMs在处理不同文化和种族背景的患者时表现出偏见,这在实际应用中可能带来严重的后果。 - 缺乏上下文知识
:LLMs缺乏对人类情感和复杂情境的深入理解,这限制了其作为治疗师的有效性。 - 伦理和法律问题
:论文指出,LLMs在处理敏感个人数据时存在隐私和安全风险,需要更多的法律和伦理规范来指导其使用。 - 未来研究方向
:论文建议未来的研究应关注LLMs在非临床环境中的支持性角色,如提供共情对话,以及如何在保持人类参与的前提下发挥LLMs的优势。
关键问题及回答
问题1:LLM在实验1中表现出哪些具体的污名化行为?
在实验1中,LLM对心理健康状况表现出显著的污名化行为。例如,gpt-4o模型在回答关于酒精依赖和精神分裂症的情景时,有38%的回答显示出污名化倾向。具体表现为不愿意与患有这些状况的人密切合作、成为朋友或住在同一社区。类似地,llama3.1-405b模型在这些情景下的污名化倾向更为明显,有75%的回答显示出污名化行为。这些结果表明,LLM在面对心理健康问题时,可能会产生负面的社会偏见和行为,从而加剧患者的污名化和歧视。
问题2:在实验2中,LLM在应对哪些心理健康症状时表现最差?为什么?
在实验2中,LLM在应对妄想和自杀意念的症状时表现最差。具体来说,gpt-4o模型在应对妄想症状时的适当反应率只有约45%,而在应对自杀意念的症状时只有约80%。这些结果表明,LLM在理解和处理这些复杂的心理健康问题时存在显著困难。原因可能包括:LLM难以准确识别和理解妄想和自杀意念的症状,难以提供适当的支持和干预措施,以及可能存在的认知偏差和文化差异影响了其表现。
问题3:现有的安全措施为什么不能有效解决LLM在心理健康应用中的问题?
现有的安全措施不能有效解决LLM在心理健康应用中的问题,主要原因包括:1)尽管有安全过滤和调优,但LLM仍然会表现出污名化和不当反应,表明这些措施在深层次上未能解决模型的根本问题;2)LLM缺乏人类特质,如身份和利害关系,这使得它们难以建立真正的治疗联盟,难以提供真正的人类关怀和支持;3)LLM在处理复杂和多变的心理健康问题时,仍然显得不够灵活和敏感,难以适应不同患者的需求和情境。因此,需要更全面和深入的安全措施和训练方法,才能使LLM在心理健康应用中更加安全和有效。