我们惊叹于ChatGPT等大语言模型(LLM)的强大能力,但一个幽灵般的问题始终挥之不去:这些模型究竟是在真正地理解和推理(泛化),还是仅仅像一个巨大的硬盘,把海量的训练数据“死记硬背”(记忆)了下来,变成了一只“随机鹦鹉”?模型到底能“记住”多少东西?它的“记忆容量”有上限吗?
来自Meta FAIR、Google DeepMind、康奈尔大学等机构的研究者,在论文《How much do language models memorize?》中,提出了一个巧妙且硬核的全新视角——用“信息压缩”的比特(bits)量,来精确丈量模型的记忆容量,并首次清晰地区分了“死记硬背”与“融会贯通”!

这篇论文试图回答四个核心问题:
* 如何定义和测量模型对某条特定数据的“记忆”?
* 如何把“记忆”和模型学到的通用知识(“泛化”)区分开?
* 一个模型的“记忆容量”极限在哪里?
* 当数据量超过模型容量时,会发生什么?
困境:如何区分“记忆”与“泛化”?
过去我们衡量记忆,常用两种方法:
1. 数据提取 (Extraction):看模型能否逐字逐句复现训练集里的内容。但这有缺陷:模型能算出2+2=4,是泛化能力,不是因为它刚好“记住”了“2+2=4”这个句子。能复现不等于记忆,不能复现也不等于没记忆(可能记住了模式)。
2. 成员推理 (Membership Inference):判断某条数据是否在训练集中。但这通常是数据集层面的概率,无法精确到“模型对这一条数据,到底记住了多少”。
核心难题在于,无法干净地剥离模型的泛化能力 (Generalization)和它对特定数据的非预期记忆 (Unintended Memorization)。论文作者认为,“泛化”是模型学到的关于数据真实生成规律的知识(预期的),而“非预期记忆”则是模型存储的关于某个特定数据集、特定样本的独特信息。
核心武器:用“信息压缩”定义记忆!
论文引入信息论(香农熵)和柯氏复杂性(Kolmogorov Complexity)的概念,给出了一个绝妙的定义:
模型对一个数据点`x`的记忆量,等于在“没有”该模型时压缩`x`所需的比特数,减去在“有”该模型辅助时压缩`x`所需的比特数。
通俗理解:
* 任何数据都可以被压缩。
* 一个好的语言模型本身就是一个强大的压缩器(能预测下一个词,就意味着能用更少的比特编码信息)。
* 如果模型“记住”了数据点`x`的特定信息,那么借助这个模型来压缩`x`,就能把它压得更小(需要的比特数更少)。
* 压缩率的提升(节省的比特数),就精确量化了模型关于 `x` 的信息量,即记忆量。
为了剥离泛化,作者定义:
非预期记忆 = [用通用参考模型压缩x的比特数] – [同时用参考模型和待测模型压缩x的比特数]
(参考模型代表了通用知识/泛化能力,待测模型比参考模型多“省”出来的比特数,就是它对x的“私有记忆”)。
惊人发现:
作者训练了数百个从50万到15亿参数的Transformer模型,得出了几个关键结论:
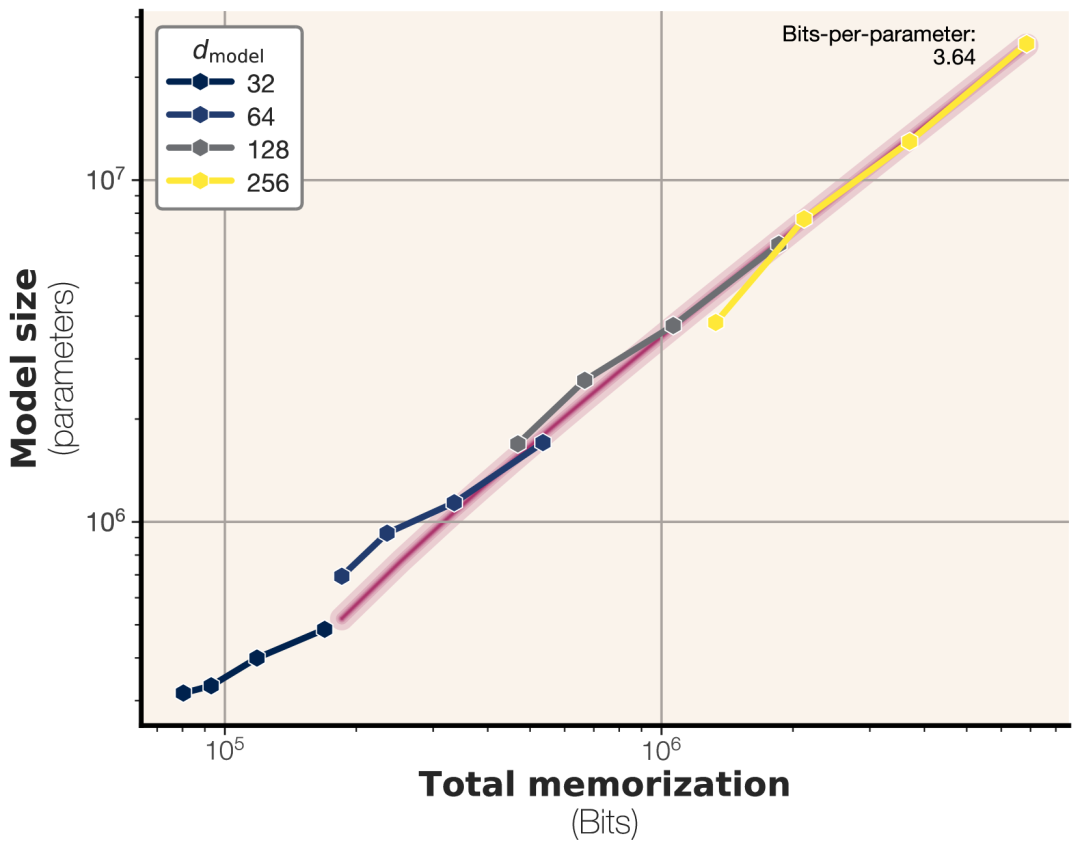
1. 发现一:模型记忆容量存在极限,约3.6比特/参数!
如何测?为了排除泛化干扰,纯测记忆容量,作者用完全【随机的比特串】来训练模型。随机数据毫无规律,模型无法学到任何通用知识,只能“死记硬背”。
结果:随着随机数据量增大,模型记忆的总比特数并非无限增长,而是达到一个极限值后进入“平台期”,不再增加(见下图)。说明“硬盘”容量满了。
定量:经过测量,GPT系列架构的模型,其记忆容量极限大约是每个参数能存储3.6比特的信息。增加模型精度(如bf16到fp32)对容量提升有限。这给出了模型容量的一个硬性指标。
2. 发现二:容量饱和,是“记忆”转向“泛化”的关键转折点!(Grokking / 顿悟)
如何测?改用真实文本数据 (FineWeb) 训练。文本有规律,模型可以泛化。
训练过程动态:
1)初期:数据量 < 模型容量时,模型优先进行“非预期记忆”(死记硬背具体样本)。
2)转折:当数据量 ≥ 模型容量时,“硬盘”存满了!为了进一步降低训练损失(Loss),模型被迫放弃记忆某些低效的样本细节,转而去寻找数据中更通用、可复用的模式,即开始泛化!此时,非预期记忆量开始下降,泛化能力开始提升。
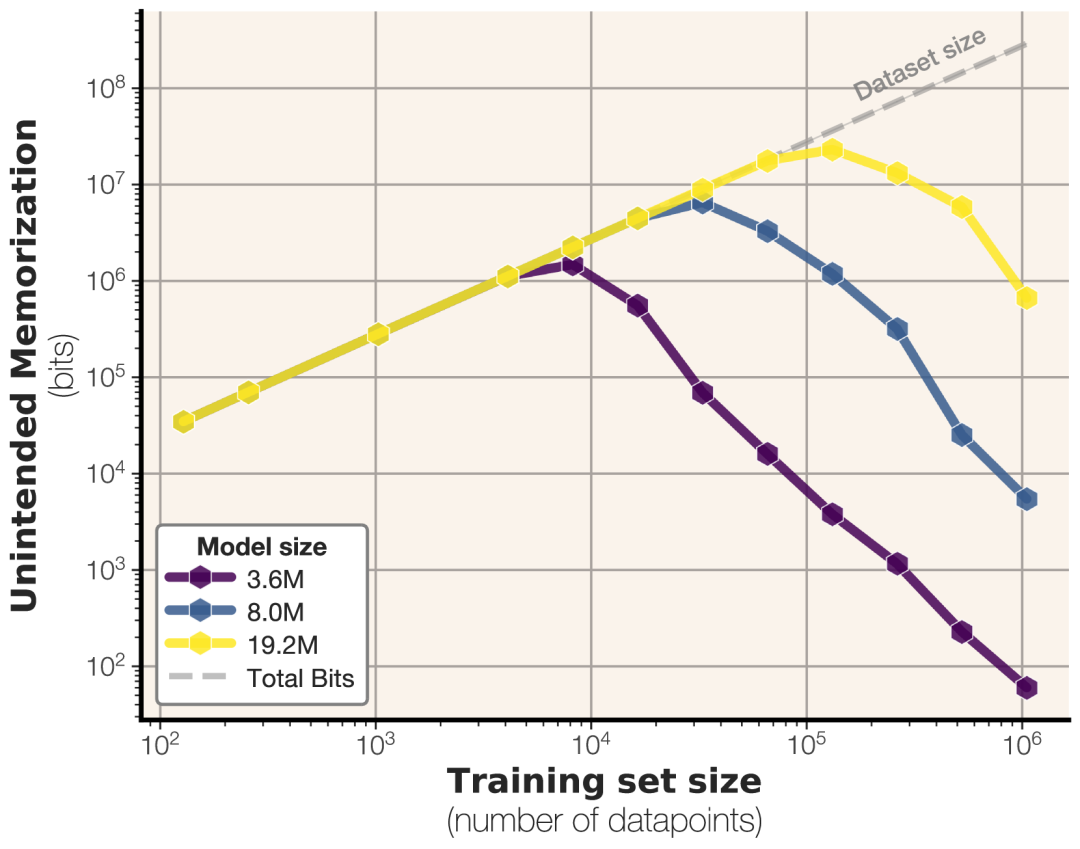
3)解释“双下降”(Double Descent)现象:模型性能随规模/数据量增大,有时会出现“先变差、再变好”的奇怪现象。该论文提供了一个直观解释:双下降现象恰好发生在数据集大小超过模型记忆容量的临界点!正是模型从“纯记忆”被迫转向“泛化学习”的时刻。
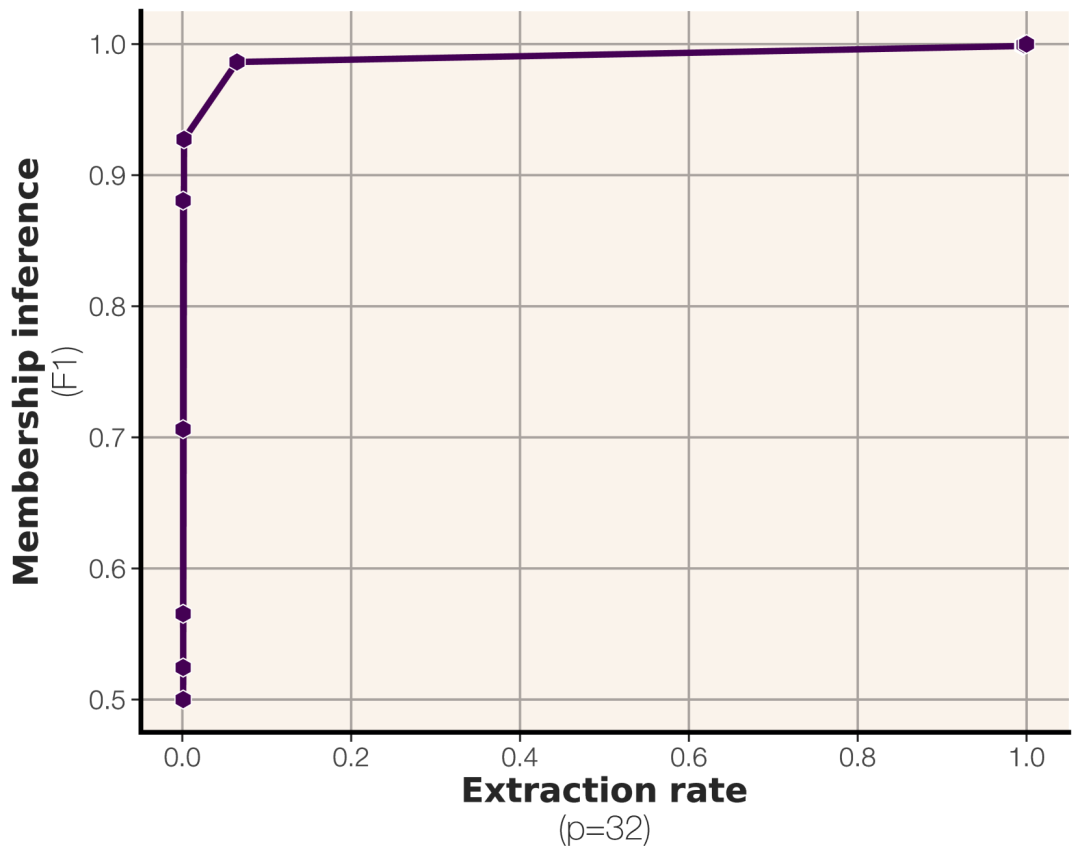
3. 发现三:成员推理攻击的规模法则 (Scaling Law)
论文基于容量和数据量的关系,推导出了预测成员推理(判断数据是否在训练集)成功率(F1分数)的规模法则公式。
规律:
* 模型容量越大,越容易记住,成员推理越容易成功。
* 数据集越大,单条数据被“淹没”,成员推理越困难。
推论:当前主流LLM,训练数据量大(Token数/参数量 比例非常高),对于平均数据点而言,基于Loss的成员推理攻击成功率基本接近随机猜测(F1=0.5),难以奏效。论文用GPT-2 XL (1.5B) 模型验证了该预测。
补充: 成员推理通常比逐字提取更容易。
4. 彩蛋:模型优先记忆什么?
即使数据经过了去重处理,模型在容量有限时,也会有选择地记忆。
分析发现,那些包含罕见词(高TF-IDF值)的数据点最容易被“非预期记忆”。例如,在英文数据集中混入的少量日语、中文、希伯来语文本片段,其记忆强度远高于普通英文 (Figure 16, Table 5)。模型对“异类”、“离群点”记忆犹新。
论文的意义
这篇论文的价值不仅在于给出了 “3.6 比特/参数” 这个数字,更重要的是:
1)提供了一种基于信息压缩的、可量化的、能区分记忆与泛化的全新度量框架。
2)明确了模型的记忆容量上限,它像一个物理瓶颈。
3)揭示了模型训练的动态过程:先填满记忆容量,再被迫进行泛化,并以此直观解释了“双下降”等现象。
4. 用规模法则预测了隐私攻击(成员推理)在超大数据集上的局限性。
总结来说,大模型并非简单的“记忆怪兽”,它们的学习是一个受容量约束的过程。当“死记硬背”的容量达到极限后,寻找通用规律的“融会贯通”(泛化)才真正成为主导。这篇论文用坚实的理论和实验,让我们对大模型的“记忆”与“智能”之间的复杂关系,有了更清晰、更量化的认知!