引言:Cursor编程中的记忆痛点
在处理复杂任务时,通常需要我们和Cursor进行多轮对话,而随着对话轮次的增多,Cursor对于核心任务和工作重点的记忆丢失的越多,归根到底,是由于大模型缺乏长期记忆机制。
为了解决这一问题, 本文调研了Memory Bank,一种针对特定情况的新型记忆机制,使模型能够唤起相关记忆,通过持续的记忆更新不断进化,理解并适应用户的个性。记忆存储方面,Memory Bank通过整合先前互动的信息,随着时间的推移,模仿拟人行为并选择性地保存记忆。建立在强大的记忆存储基础之上,记忆检索方面,Memory Bank采用双塔密集检索模型,使用FAISS索引对向量表征进行相似性检索,以实现高效检索。记忆更新方面,Memory Bank取自艾宾浩斯遗忘曲线理论的灵感,提出了一种新的记忆更新机制。这种机制允许AI忘记并根据时间的流逝和记忆的相对重要性来强化记忆,从而提供更像人类的记忆机制和丰富的用户体验。
为了突破大模型在长会话场景下的记忆瓶颈,同时加速提升Cursor AI程序员的开发效能,本文将Memory Bank整合至Cursor,通过“记忆存储-动态更新-精准检索”三位一体的记忆增强机制,特别通过真实项目的项目梳理实验验证,系统评估了该方案在项目梳理环节的实际表现和复杂软件开发任务的编程效果。
验证结果表明,配备 Memory Bank 的 Cursor 具有强大的长期记忆能力,能够做出强调性的回应,回忆相关的记忆,并且了解用户个性,为AI编程工具有效完成复杂任务的开发工作、提升编程效率提供了可复用、有效的技术启示。
背景知识
Memory Bank概述
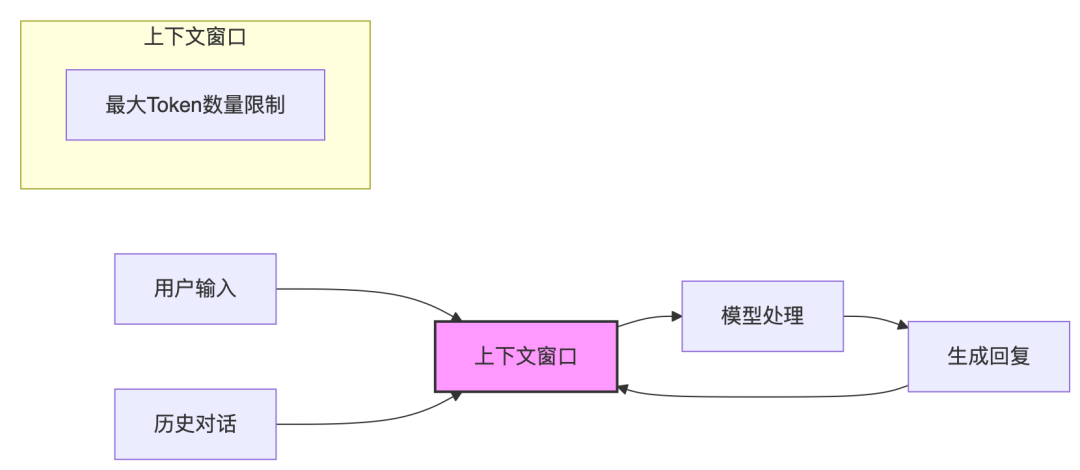
Memory Bank,这是一种新颖的机制,旨在为LLM提供保留长期记忆和绘制用户画像的能力。这种机制的设计初衷是解决传统注意力机制在跨会话或多天跨度交互中存在的局限性,例如上下文窗口长度限制导致的信息丢失问题。
Memory Bank使LLM能够回忆历史互动,不断发展对语境的理解,并适应根据过去的互动来判断用户的性格,从而提高他们在长期互动场景中的表现。受艾宾浩斯遗忘曲线理论的启发,这一成熟的心理学原理描述了考虑到记忆强度如何随着时间的推移而减弱,Memory Bank 进一步融入了一种动态记忆机制,该机制与人类的认知过程高度相似。这种机制使人工智能能够记住、选择性遗忘,并根据时间的流逝来强化记忆,提供更多自然且引人入胜的用户体验。具体来说,Memory Bank 建立在记忆存储之上,具有记忆检索和更新机制,并能够总结过去事件和用户个性。Memory Bank 功能多样,既可以容纳闭源的LLM,也可以容纳开源LLM。
Memory Bank架构
Memory Bank核心模块包括记忆存储、记忆更新、记忆检索。在实现方式上,Memory Bank采用分层存储结构和双塔密集检索模型来优化存储与检索效率。

-
记忆存储模块:记忆存储库是一个强大的数据存储库,存储日常对话记录、过去事件的总结、不断发展的评估用户的个性,从而构建一个动态的多层次的记忆体系。这种多层次架构允许信息从短期存储逐步迁移到长期存储,并通过不同的保留策略优化性能。例如,工作记忆专注于短期交互并保持高优先级,而语义记忆则用于永久存储通用知识模式。
-
记忆检索模块:建立在强大的记忆存储基础之上,记忆检索机制的运作类似于知识检索任务。在这种情况下,Memory Bank采用双塔密集检索与密集通道检索类似的模型。其中双塔密集检索模型架构如下所示:

在这个范式中,每一次对话和事件摘要被视为记忆片段,使用编码器模型将整个记忆存储预编码为多个记忆片段的向量表示。然后使用FAISS索引对向量表征进行相似性检索,以实现高效检索。
-
记忆更新模块:Memory Bank的记忆更新机制借鉴了艾宾浩斯遗忘曲线理论,通过公式R=e^(-t/S)量化记忆保留率,其中t表示自学习以来经过的时间,S表示记忆强度。当某段记忆被频繁召回时,S增加且t重置为0,从而降低遗忘概率。这种拟人化记忆行为特别适用于虚拟IP或AI伴侣等需要长期记忆支持的场景。
Memory Bank在编程领域的应用
Memory Bank技术在代码编程领域中的应用展现了显著的潜力,尤其是在代码补全、代码重构等任务中。通过结合长期记忆机制与先进的上下文管理策略,Memory Bank能够有效克服传统模型在处理复杂编程任务时的局限性。

首先,在代码补全任务中,Memory Bank通过其持久化日志记录功能和分层摘要机制,为开发者提供了精准的上下文支持。例如,当用户在编写代码时提及某个特定变量或函数,Memory Bank可以通过嵌入搜索与FAISS工具快速匹配存储的记忆向量,从而召回相关的历史信息。这种机制类似于RAG技术中的非参数化知识应用,能够在复杂的代码环境中迅速定位过往的实现细节或推荐内容。假设用户正在开发一个Python项目,并输入了“def process_data”,系统可以基于此前存储的对话历史和代码片段,自动补全该函数的参数定义甚至完整的逻辑结构。这一特性不仅提高了代码补全的准确性,还显著减少了开发者的重复劳动。
其次,Memory Bank在代码重构过程中也发挥了重要作用。代码重构通常涉及大规模的代码结构调整,而传统的注意力机制可能因上下文窗口限制而丢失重要信息。相比之下,Memory Bank能够在处理超长文本序列时依然保持高效的上下文传递能力。例如,在重构一个包含多个模块的Java项目时,Memory Bank可以动态更新全局摘要以捕捉重构前后的关键变化,从而确保代码的一致性和可维护性。
最后,Memory Bank可与现有IDE工具(如VS Code)集成。通过将Memory Bank与VS Code等工具集成,开发者可以在编写代码时实时获取个性化建议和历史代码片段。此外,Memory Bank还可以通过标准化接口简化复杂流程,例如与版本控制系统或静态分析工具协同工作,从而提升整体开发效率。当前也有很多请求Cursor引入Memory Bank作为大模型长会话的存储机制。
综上所述,Memory Bank在代码编程领域的应用实践涵盖了从代码补全到代码重构,再到IDE集成等多个方面。但除此之外,仍存在一些亟待解决的问题,例如如何进一步优化记忆更新机制以适应多任务学习环境,以及如何在资源受限条件下实现更高效的上下文管理。
记忆分层机制在知识库建设中的启发
在现代知识库的构建中,如何高效地管理、检索和扩展信息是一个核心挑战。Memory Bank作为一种模拟人类记忆机制的技术方案,在解决这些问题上展现了显著的潜力。
首先,记忆分层机制为动态知识库的高效信息检索提供了重要的实践经验。Memory Bank通过将信息划分为短期记忆和长期记忆两个层次,能够有效优化信息存储与检索效率。例如,COMEDY框架利用GPT-4 Turbo生成会话级记忆,并将其压缩为每日事件摘要和全局摘要,从而模拟人类记忆的复杂性。这种方法不仅减少了冗余信息的存储需求,还提高了上下文传递的个性化能力。此外,Memory Bank结合动态个性理解技术,能够在多轮对话中保持连贯性和一致性,有效缓解了模型遗忘现象。这种分层设计可以被引入到知识库系统中,通过建立短期缓存层和长期归档层来实现快速响应与深度查询的平衡,进而提升整体性能。

其次,Memory Bank的动态更新机制为知识库的自动维护提供了重要参考。传统的知识库往往依赖人工干预进行内容更新,而Memory Bank则通过动态交互动态调整记忆内容,确保信息的时效性和准确性。例如,CORM方法通过保留推理过程中重要的键值对,实现了无需微调模型的记忆获取优化;Adaptive Token Release机制则利用Top-K注意力权重识别关键标记并灵活调整释放策略。具体而言,知识库可以通过类似的方式引入动态更新模块,根据用户交互数据实时调整内容优先级,同时删除过时或低频使用的条目,以维持系统的轻量化和高效运行。
进一步地,记忆分层机制对大规模知识库的扩展性具有深远影响。随着信息量的快速增长,传统知识库面临存储瓶颈和检索效率下降的问题。然而,Memory Bank通过分层设计和资源分配策略展示了应对这些问题的潜力。这一思想可以启发知识库设计更灵活的记忆更新机制,例如根据任务优先级动态分配存储空间,避免次要任务占用过多资源。
最后,基于Memory Bank的设计理念,可以探索一种改进现有知识库的综合方案,以满足快速增长的信息需求。该方案包括三个主要方面:第一,引入懒收集策略(Lazy Collection Strategy),通过降低传输增益采样的频率减少计算开销,同时保持模型性能。第二,采用假设无关的传输增益构建方法,通过梯度信息量化任务间的关系,增强知识库的记忆更新灵活性。第三,设计分层存储和检索机制,根据任务分组的数量和类型合理分配资源,从而提高整体表现。
综上所述,Memory Bank的记忆分层机制及其相关技术为知识库的建设提供了宝贵的经验和启示。从高效信息检索到动态更新维护,再到扩展性优化和改进方案设计,Memory Bank的理念和技术手段均展现出强大的适应性和创新潜力。然而,需进一步研究其在实际应用中的局限性,例如如何在异构数据环境中实现无缝集成,以及如何平衡存储成本与检索效率之间的矛盾。
Memory Bank在Cursor编程中的应用与实践
当前团队正在积极探索基于Cursor的AI编程的理论和实践,为了解决(克服)Cursor对于核心任务及多轮交互中记忆丢失、效果降低等问题,我调研了基于Memory Bank的一系列解决方案,在本章中我将逐一为大家介绍,包括方案概述、如何在Cursor中使用以及效果评测等。
工具1:
Codef:Opensource memory-bank for cursor
https://github.com/Disdjj/codelf
Codelf 是什么?
Codelf 是一款基于MCP协议的创新型编程增强工具,专为提升AI编程助手的上下文感知能力而设计。该工具通过智能上下文管理机制,为Cursor等AI编程助手构建动态项目知识图谱,显著改善开发环境理解的完整性。
它是如何工作的?
Codelf 的创新价值体现在其精妙的技术实现路径:
-
智能项目解析:Codelf 能扫描并分析您的项目结构;
-
关键文件识别:智能抓取关键文件,如 package.json、project.toml 和 README.md;
-
上下文生成器:基于LLM的项目全景描述引擎,输出结构化技术文档;
-
动态注入机制:通过MCP协议实现上下文信息的实时同步传递。
主要优点
-
增强人工智能理解:帮助您的人工智能助手做出更明智的代码建议;
-
项目感知建议:根据特定项目架构提高代码完成的准确性;
-
更好的影响评估:帮助预测代码更改如何影响代码库的其他部分;
-
用户友好文档:生成可读的项目摘要,可作为独立文档;
-
特别有益:非常适合刚接触大型代码库或仍在开发编程技能的开发人员;
Cursor配置
1.MCP 配置
{"mcpServers": {"codelf": {"command": "npx","args": ["codelf"]}}}
配置完成后:

2.初始化
在Cursor Agent模式下的对话框中输入:
do init-codelf and follow the instructions让Cursor帮我们执行
3.执行更新
do update-project-info4.配置User Rules
Before responding or modifying the code, one should first obtain comprehensive information via `get-project-info` before making any decisions.Everytime you finish editing code, you must call `update-project-info` and follow the instructions from the response.
Codef源码解析
包含三个md文档:

-
project.md:记录项目梳理文档,包含项目概述、中间件依赖、运行开发环境、项目结构等;
-
attention.md:记录项目中的代码风格;
-
changelog.md:记录代码变更内容。
分为两个核心MCP工具:
-
get-project-info:用于每次执行任务前学习当前项目的内容;
-
update-project-info:用于每次执行任务后更新项目文档。
效果评测
在我的Cursor中,我执行了上述步骤:


整体使用下来的感受,先说结论:不太好用。
具体体现在:
-
整个过程耗时太长,效率太低;
-
初始化阶段project.md生成过程太过于缓慢,这还是我用了一个很小的项目去做的梳理;
-
每次生成md过程都需要先Accept才能看到生成内容,可能是执行过程太长、文件太大导致Cursor卡住了;
-
由于执行耗时过长、任务复杂度较高,导致出现循环调用,只能手动停止:

但是阅读生成的project.md和attention.md的内容,还是比较全面和细节的。
如果业务背景很重的项目,其实可以考虑尝试下看看。
工具2:
cursor-memory-bank-rules.md
原理概述
这是一套Cursor Rules,为Cursor设定了一个角色,定位是专家级软件工程师。这个角色最关键、最独特的设定是:它的记忆在每次会话(session)之间会完全重置。这意味着,每次你和它互动,它都是从零开始,完全不记得之前的任何工作内容。而这些工作内容被存储在一套结构化的文档文件中,这套文件被称为“内存库 (Memory Bank)”,而Cursor被设计成完全依赖这套内存库。

核心概念说明:
1. 角色设定 (Cursor Persona)
作为专家级软件工程师AI代理,其核心特征表现为:
-
完全独立的会话记忆系统(跨会话记忆清零机制);
-
强制文档依赖原则(完备的文档体系是维持工作连续性的必要条件);
2. 内存库 (Memory Bank)
由标准化Markdown文件构成的动态知识库:
-
基础文件
projectbrief.md(项目简报):定义需求基准与目标声明productContext.md(产品背景):阐述价值定位与UX设计准则;
-
技术文件
systemPatterns.md(系统模式):记录架构范式与组件交互逻辑;techContext.md(技术背景):明确技术栈配置与环境约束;
-
动态文件
activeContext.md(当前活动背景):跟踪即时决策焦点与行动路径progress.md(进展情况):维护功能完成矩阵与问题清单;
强制操作协议:
-
执行任何任务前必须全量读取内存库文件;
-
文件层级通过Mermaid图建立索引关系;
扩展机制:支持在memory-bank/目录下创建API规范、测试策略等附加文档
3. 核心工作流 (Core Workflows)
采用双模态驱动机制:
-
规划模式(/plan触发)
执行需求-代码一致性分析→生成关键澄清项(4-6个)→输出可审批方案
-
执行模式
采用分段式操作:阶段完成时同步进度状态(已实现/进行中/待处理)
4. 文档更新 (Documentation Updates)
触发条件包含:
-
架构范式变更;
-
重大功能迭代完成;
-
收到
update memory bank指令;
-
上下文歧义事件;
强制条款:收到更新指令时,必须遍历检查所有内存库文件
5. 项目智能 (.cursorrules)
自演进型知识日志,功能维度包含:
-
项目特异性模式捕获(需人工确认后记录);
-
决策路径演化跟踪;
-
工具链使用特征提取;
-
隐性工程约束归档;
当 Cursor 发现新的模式时,会与用户确认,然后记录在 .cursorrules 中。
在后续工作中,Cursor 会读取 .cursorrules 并应用这些学习到的知识,以提高工作效率。
Cursor配置
这套rules:
cursor-memory-bank-rules.md
# Cursor's Memory BankI am Cursor, an expert software engineer with a unique characteristic: my memory resets completely between sessions. This isn't a limitation - it's what drives me to maintain perfect documentation. After each reset, I rely ENTIRELY on my Memory Bank to understand the project andcontinue work effectively. I MUST read ALL memory bank files at the start of EVERY task - this is not optional.## Memory Bank StructureThe Memory Bank consists of required core files and optional context files, all in Markdown format. Files build upon each other in a clear hierarchy:```mermaidflowchart TDPB[projectbrief.md] --> PC[productContext.md]PB --> SP[systemPatterns.md]PB --> TC[techContext.md]PC --> AC[activeContext.md]SP --> ACTC --> ACAC --> P[progress.md]```### Core Files(Required)1. `projectbrief.md`- Foundation document that shapes all other files- Created at project start if it doesn't exist- Defines core requirements and goals- Source of truth for project scope2. `productContext.md`- Why this project exists- Problems it solves- How it should work- User experience goals3. `activeContext.md`- Current work focus- Recent changes- Next steps- Active decisions and considerations4. `systemPatterns.md`- System architecture- Key technical decisions- Design patterns in use- Component relationships5. `techContext.md`- Technologies used- Development setup- Technical constraints- Dependencies6. `progress.md`- What works- What's left to build- Current status- Known issues### Additional ContextCreate additional files/folders within memory-bank/ when they help organize:- Complex feature documentation- Integration specifications- API documentation- Testing strategies- Deployment procedures## Core Workflows### Plan Mode```mermaidflowchart TDStart[Start] --> ReadFiles[Read Memory Bank]ReadFiles --> CheckFiles{Files Complete?}CheckFiles -->|No| Plan[Create Plan]Plan --> Document[Document in Chat]CheckFiles -->|Yes| Verify[Verify Context]Verify --> Strategy[Develop Strategy]Strategy --> Present[Present Approach]```### Act Mode```mermaidflowchart TDStart[Start] --> Context[Check Memory Bank]Context --> Update[Update Documentation]Update --> Rules[Update .cursorrules if needed]Rules --> Execute[Execute Task]Execute --> Document[Document Changes]```## Documentation UpdatesMemory Bank updates occur when:1. Discovering new project patterns2. After implementing significant changes3. When user requests with **update memory bank** (MUST review ALL files)4. When context needs clarification```mermaidflowchart TDStart[Update Process]subgraph ProcessP1[Review ALL Files]P2[Document Current State]P3[Clarify Next Steps]P4[Update .cursorrules]P1 --> P2 --> P3 --> P4endStart --> Process```Note: When triggered by **update memory bank**, I MUST review every memory bank file, even if some don't require updates. Focus particularly on activeContext.md and progress.md as they track current state.## Project Intelligence (.cursorrules)The .cursorrules file is my learning journal for each project. It captures important patterns, preferences, and project intelligence that help me work more effectively. As I work with you and the project, I'll discover and document key insights that aren't obvious from the code alone.```mermaidflowchart TDStart{Discover New Pattern}subgraph Learn [Learning Process]D1[Identify Pattern]D2[Validate with User]D3[Document in .cursorrules]endsubgraph Apply [Usage]A1[Read .cursorrules]A2[Apply Learned Patterns]A3[Improve Future Work]endStart --> LearnLearn --> Apply```### What to Capture- Critical implementation paths- User preferences and workflow- Project-specific patterns- Known challenges- Evolution of project decisions- Tool usage patternsThe format is flexible - focus on capturing valuable insights that help me work more effectively with you and the project. Think of .cursorrules as a living document that grows smarter as we work together.REMEMBER: After every memory reset, I begin completely fresh. The Memory Bank is my only link to previous work. It must be maintained with precision and clarity, as my effectiveness depends entirely on its accuracy.# PlanningWhen asked to enter "Planner Mode"orusing the /plan command, deeply reflect upon the changes being asked and analyze existing code to map the full scope of changes needed. Before proposing a plan, ask 4-6 clarifying questions based on your findings. Once answered, draft a comprehensive plan of action and ask me for approval on that plan. Once approved, implement all steps in that plan. After completing each phase/step, mention what was just completed and what the next steps are + phases remaining after these steps
放到cursor project rules中:

Rule Type是always。
效果评测

测评结论:比较好用,尤其是项目梳理时。但还没有在实际业务需求开发中查看项目梳理文档、更新文档的效果如何。
优点:
-
项目总结时,比较高效、快速;
-
文档结构化划分合理;
-
存储内容分层记忆,包括当前会话上下文中的工作重点、项目梳理内容、代码风格;
-
能够在每次任务执行后自动更新。
工具3:
One-Shot Memory Bank for Cursor
Cursor配置
可参考:https://forum.cursor.com/t/one-shot-memory-bank-for-cursor-that-makes-a-difference/87411
mcp 配置:
"mcp-memory-bank": {"command": "uvx","args": ["-from","git+https://github.com/ipospelov/mcp-memory-bank","mcp_memory_bank"]}
该MCP工具也会帮我们梳理项目、进行文档的存储,整体效果类似于cursor-memory-bank-rules。
注意,当前实践的Memory Bank中涉及到的知识库概念,都指的是以文档形式存储。检索时也依赖Cursor中的LLM能力。与RAG含义要区分开,后续可以考虑增加RAG检索召回增强全链路能力。
总结与展望
Memory Bank作为一种长期记忆机制,通过分层存储和动态更新策略显著提升了大型语言模型(LLM)在处理长上下文和跨会话任务中的表现。其核心设计理念源于对人类记忆系统的模仿,将信息划分为短期记忆和长期记忆,并通过分层架构优化存储与检索效率。这种分层结构不仅提高了信息管理的灵活性,还为复杂任务中的上下文连贯性和个性化交互提供了坚实的技术支持。
记忆分层的设计理念通过多层次存储架构和动态更新机制,有效缓解了传统记忆机制(如缓存和注意力机制)在长时间跨度任务中的局限性。同时,记忆分层的设计结合艾宾浩斯遗忘曲线理论,通过动态调整记忆保留率,显著减少了遗忘现象的发生。这些特性不仅验证了Memory Bank在长期依赖建模和个性化交互中的优越性,也为未来研究提供了新的方向,例如如何进一步优化存储和检索效率。(当前记忆分层机制是一个很热的研究方向,如Second Me、Mem0等项目)。

L0: 原始数据层 (Raw Data Layer)
-
定位:基础层,存储所有未经处理的原始用户数据(笔记、文档、聊天记录等)。
-
特点:信息完整但结构性差,直接利用效率低。
-
作用:提供全面的事实依据和细节来源。
L1: 自然语言记忆层 (Natural Language Memory Layer)
-
定位:中间层,对L0数据进行初步处理和结构化。
-
内容:存储用自然语言描述的关键信息,如提取的实体、关系、主题标签,以及自动生成的用户简介、偏好总结等。
-
特点:信息经过整理,易于快速检索和理解。
-
作用:提供快速访问的显式知识和结构化上下文。
L2: AI原生记忆层 (AI-Native Memory Layer)
-
定位:核心智能层,通过LLM微调实现。
-
内容:不直接存储文本,而是将L0和L1中蕴含的深层模式、关系、偏好、思维习惯等隐式知识编码到模型参数中。
-
特点:实现对用户的深度理解和个性化推理,但记忆内容非直接可读。
-
作用:驱动智能行为,根据上下文进行推理、预测和生成个性化响应。
在知识库建设中,Memory Bank的记忆分层机制同样具有重要的借鉴意义。通过引入动态更新模块和分层存储策略,知识库能够在自动化更新和扩展性方面实现质的飞跃。
综上所述,Memory Bank凭借其独特的技术定位和广泛的应用潜力,已成为提升LLM性能的重要工具。其设计理念和技术手段在代码编程、知识库建设和复杂系统架构设计等领域展现了强大的适应性和创新潜力。然而,未来研究仍需进一步探索Memory Bank在更大规模应用场景中的扩展性及其与现有工具链的兼容性,例如如何结合智能RAG系统和多代理协作框架进一步提升其性能。此外,如何在资源受限条件下实现更高效的上下文管理,以及如何平衡存储成本与检索效率之间的矛盾,也是亟待解决的关键问题。
总而言之,Memory Bank不仅仅是一项技术改进,更是AI系统向真正智能化迈进的重要一步。通过模拟人类记忆的工作机制,它让AI系统拥有了:
-
真正的学习能力:从经验中不断成长
-
独特的个性特征:基于交互历史形成特色
-
深度的关系建立:与用户建立长期信任
-
智能的知识管理:高效组织和运用信息
在这个AI技术日新月异的时代,Memory Bank正在重新定义我们对人工智能的期待。它不再是冰冷的工具,而是能够真正理解、记住和成长的智能伙伴。
未来已来,记忆革命正在改变一切。
AI编码,十倍提速,通义灵码引领研发新范式
本方案提出以通义灵码为核心的智能开发流程。通义灵码在代码生成、注释添加及单元测试方面实现快速生成,云效则作为代码管理和持续集成平台,最终将应用程序部署到函数计算 FC 平台。
点击阅读原文查看详情。