导读 随着人工智能技术的迅猛发展,特别是大语言模型的爆发式增长,AI 已经开始深入影响数据科学工作的各个方面。本文将由 Snap 公司 Core Data Science 组数据科学家徐萌老师,从数据科学家的日常工作出发,探讨如何利用 AI 技术优化数据处理流程、提供工作效率,并思考 AI 时代的职业发展路径。
1. 背景介绍
2. AI 在数据收集和清理中的应用
3. AI 在建模中的应用
4. AI 提高数据科学工作效率的其他应用
5. AI 的局限、人机协作及职业发展思考
6. Q&A
分享嘉宾|徐萌 Snap Inc. Tech lead of core data science
编辑整理|旭锋
内容校对|李瑶
出品社区|DataFun
01
背景介绍
1. 数据科学家的核心工作模块

数据科学家的核心工作模块包括以下内容:
当拿到一个商业问题时,首先需要考虑的是如何将其转化为描述性问题、预测性问题或因果推论问题。确定问题类型后,还需选择具体的方法,例如对于因果推论问题,需要思考是通过实验回答,还是依赖观测性数据。最后选择对应方法。这一步在数据科学工作中至关重要。
接下来,数据科学家需要收集和清理数据,然后用统计和机器学习方法进行建模。
分析完成后,通常需要借助可视化方法和沟通技巧,将结论与决策层进行有效沟通。因为决策层可能缺乏专业的数据科学背景。代码实现贯穿所有步骤。
2. 人工智能的基本概念
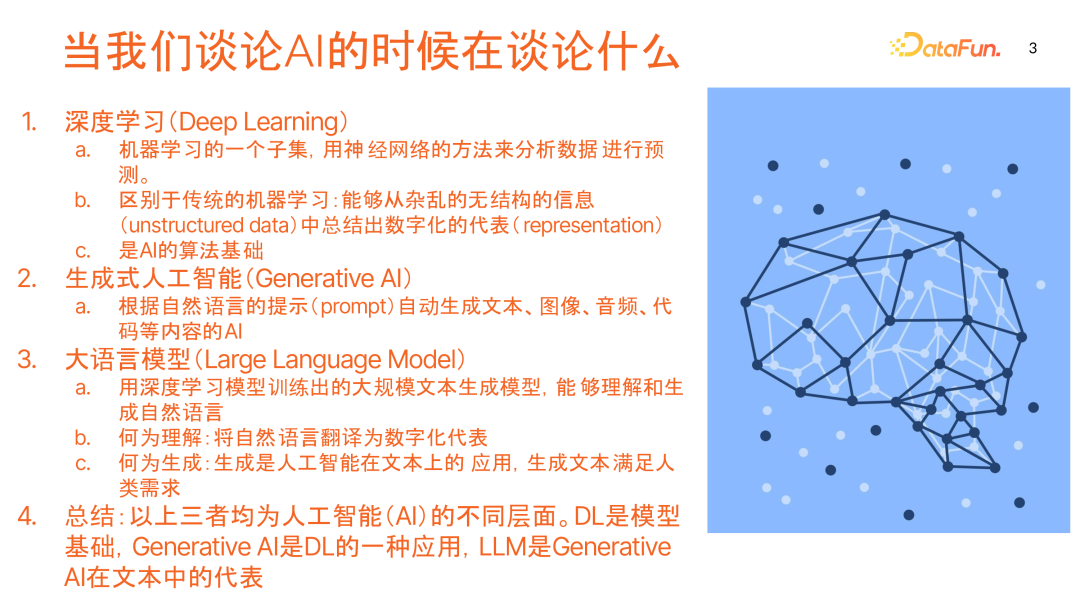
在讨论 AI 应用之前,有必要明确几个核心概念:
-
深度学习:是机器学习的一个子集,使用神经网络方法分析数据并进行预测。与传统机器学习不同,深度学习不仅能处理结构化数据,还能从非结构化信息(如文本、图片、视频、音频)中提取数字化表示。它是 AI 算法的基础。 -
生成式人工智能:指根据自然语言提示自动生成文本、图像、音频、代码等内容的 AI。 -
大语言模型:是通过深度学习训练出的大规模文本生成模型,能够理解和生成自然语言。
这三者代表了人工智能的不同层面:深度学习是模型基础,生成式 AI 是深度学习的一种应用,大语言模型则是生成式 AI 在文本领域的代表。
02
AI 在数据收集和清理中的应用
1. 文本向量表示
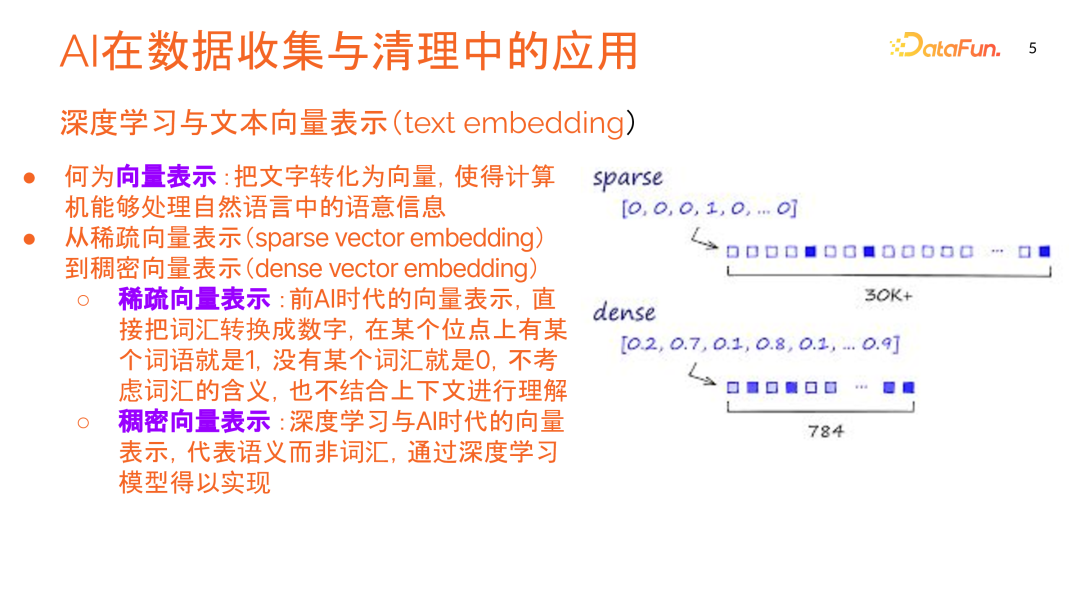
文本向量表示(Text Embedding)是将文字转化为向量,即把文字数字化,使计算机能处理自然语言中的语义信息。
文本向量化发展经历了从稀疏向量到稠密向量的演变:
-
稀疏向量表示:前 AI 时代的常见做法,直接将词汇转换为数字,不考虑词汇含义或上下文,通常生成包含大量零的长向量。
-
稠密向量表示:在深度学习和 AI 时代,使用几百维的稠密连续数字向量来表示文本含义,而非仅仅表示单个词汇。

Google BQML 中的 Text Embedding 功能简单易用,只需一行代码就能将文本转换为 768 维向量。例如,将“我爱猫“转换为向量,如果改为英文“I love cat”,结果会非常相似,表明这种转换基于文本含义而非文本本身。
2. 利用向量距离量化文本相似度
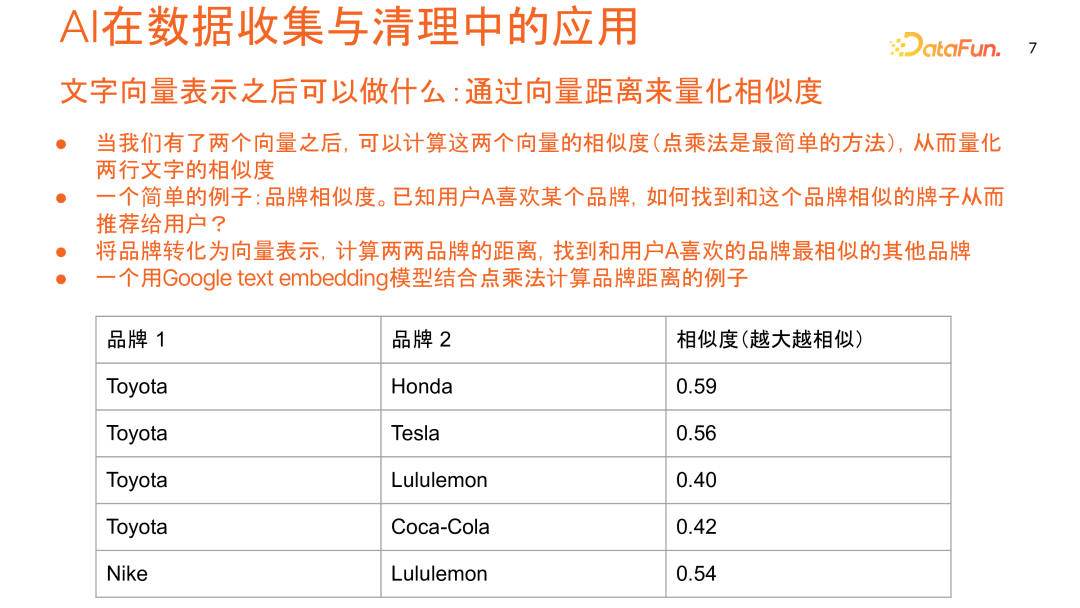
将文本转换为向量后,可以通过计算向量距离来量化文本相似度。最简单的方法是点乘法,通过计算两个向量的点积来衡量相似度。
例如,在品牌相似度计算中,我们可以使用 Google Text Embedding 模型结合点乘法来计算品牌之间的距离:
-
丰田(Toyota)和本田(Honda)都是传统日本车品牌,相似度为 0.59
-
丰田与特斯拉(Tesla)的相似度为 0.56,略低于与本田的相似度
-
丰田与运动品牌 Lululemon 的相似度仅为 0.4
-
丰田与饮料品牌可口可乐的相似度仅为 0.42
-
耐克与 Lululemon 同为运动品牌,相似度为 0.554
3. 预训练模型与微调模型

使用大语言模型时,我们通常会用到两种类型的模型:
-
预训练模型:在大规模数据集上提前训练的模型,分为预训练语言理解模型(将语言转换为向量,如 Bert)和预训练语言生成模型(如 GPT 系列,这类模型优势在于即取即用,基于海量人类语言训练,通用性强)。
-
微调模型:在预训练模型基础上,使用特定任务数据继续训练的模型。它在特定需求上更准确,适合用户情感分析、企业私有知识问答、多语言适配等场景。
预训练模型可比作不偏科的高中学霸,全面发展且有潜质;微调模型则让这位全能高中毕业生进一步学习特定专业知识。

微调的必要性体现在向量表示对场景和语境的依赖上。例如,“一种新的苹果产品“在科技新闻推荐系统中指的是苹果公司产品(iPhone、MacBook 等),而在水果电商客服对话中指的是水果。预训练模型只能学到平均意义,无法准确判断特定语境,需要微调来适应。
微调模型的基本步骤包括:
-
收集训练内容,按情景需求标注正负样本 -
使用不同预训练模型进行预测,理解各模型准确度 -
选择适当的损失函数(loss function) -
运行微调过程,使用验证集提高准确度 -
使用评估数据集评估模型准确度
Python 库 sentence-transformers 提供了常见预训练模型和选择损失函数的指南,值得推荐。
4. 语义搜索
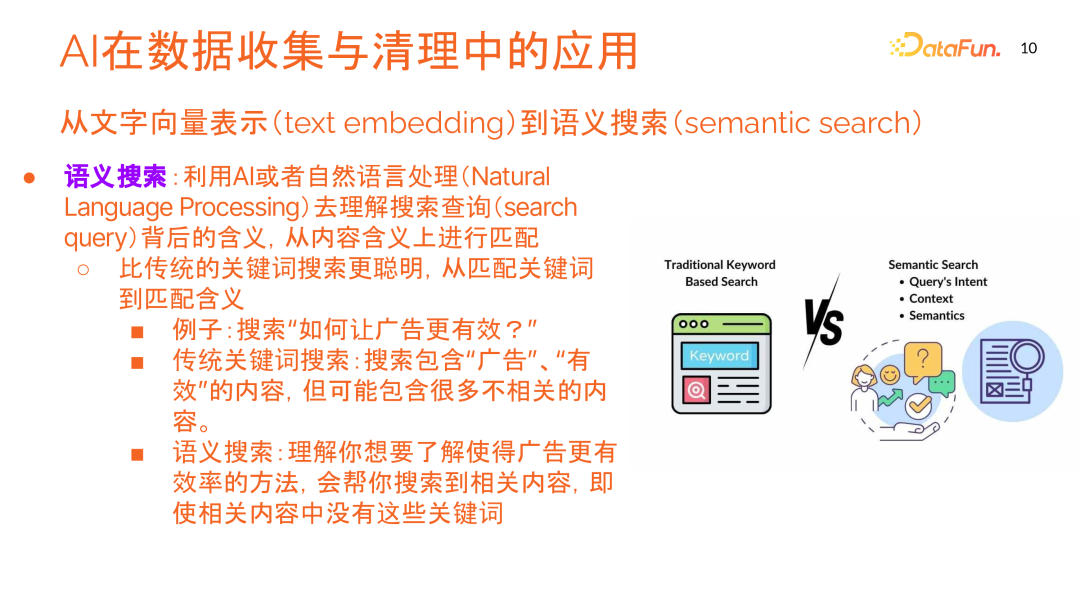
语义搜索使用 AI 或自然语言处理来理解搜索查询背后的含义,从内容含义上进行匹配。相比传统关键词搜索,语义搜索更加智能,不仅匹配关键词,还匹配内容含义。
例如,搜索“如何让广告更有效“时,传统关键词搜索会查找包含“广告“、“有效“等词的内容,可能包含许多不相关信息。而语义搜索则理解用户想了解提高广告效率的方法,会搜索相关内容,即使这些内容中没有这些关键词。

语义搜索实现步骤:
-
将待搜索内容转换为向量表示 -
将搜索查询转换为向量表示 -
计算搜索查询向量与每条内容向量的距离(可使用点乘法) -
按距离从小到大排序内容,最接近的内容最符合搜索需求
语义搜索常用于搜索引擎、问答机器人等场景。在数据科学中,可用于推荐系统,根据用户喜好搜索意思相近的内容。
在实际应用中,亚马逊已从关键词搜索升级到语义搜索:以前搜索“quality”会显示所有包含该词的评论并加粗该词;现在则显示所有讨论产品质量的评论,即使评论中没有“quality”关键词,AI 也会从相关评论中提炼产品质量总结。

关键词搜索并非毫无价值,它简单高效,适合大数据量快速检索。而语义搜索虽然更准确,但计算成本高,对每条内容逐一进行向量转换在商业实践中会很昂贵。实践中可先用关键词搜索缩小范围,再用语义搜索排除不相关内容。
5. 利用生成式 AI 进行文本分类

除了传统机器学习分类和基于语义搜索的分类外,还可以利用生成式 AI 进行文本分类:
-
传统机器学习模型:输入离散结果和数字化预测特征,调整模型参数提高表现 -
语义搜索分类:利用相似度设置阈值进行分类 -
生成式 AI 分类:输入文字、图像、视频、音频等非数字化资料,用自然语言作为提示词要求 AI 帮助分类,通过调整提示词而非参数来提高模型表现

-
将所有标签用大语言模型转换为向量表示 -
将“品牌”一词转换为向量表示 -
计算“品牌”与每个标签的距离 -
设置阈值进行分类
生成式 AI 分类表现更佳,但需要尝试不同提示词(prompt)。以下是几种提示词的效果对比:
-
初始提示词:“Is the following tag a brand name? The tag is X.”(AI 不直接回答问题,而是解释一番)
-
改进提示词:“Is the following tag a brand name? The tag is X. Only answer yes or no.”(结果仍不满意,AI 会将类似“yogurt”这种指代具体事物但非特定品牌的标签归类为品牌)
-
最佳提示词:加入具体例子,如“Yogurt is not a brand, but Nike is a brand.”(在测试数据上表现极佳,准确识别所有品牌)

Google BQML 提供了简单的代码实现方式,只需编写 SQL 调用标签、给出提示词,并调用 Google 内建生成式 AI 模型,即可完成文本分类。

文本分类的一些经验总结:
-
提示词不要过于复杂,复杂任务应分步给出提示词 -
问答式提示词比完形填空式提示词表现更好
-
GPT-4o 和 GPT-4比GPT-4 Turbo 表现稍微好一些。GPT-4o mini 表现更差。Claude 比 GPT 表现差
-
只有解码器的语言理解模型(如 BERT)比包含解码器和编码器的语言生成模型计算更便宜高效
-
应使用评估样本来评估不同模型和提示词的表现,降低过度拟合可能性
03
AI 在建模中的应用

将向量表示转为模型特征:
1. 机器学习模型
-
将文本、图像、视频直接转化为向量表示,作为新特征加入机器学习模型
-
使用生成式 AI 的文本分类结果作为预测性更强的特征
2. 因果推论模型
-
利用向量表示计算的内容相似度作为特征(如计算广告与内容相似度,研究相似度如何影响广告表现)
3. 推荐系统模型
-
将用户评价和物品描述转化为向量表示,分别作为用户特征和物品特征;
将向量表示作为新特征有两个主要优势:一是将内容深层含义数字化,便于模型处理;二是生成稠密向量,维度较低,便于后续模型处理。

-
让 AI 建议基于现有特征生成新特征
利用 AI 从日期判断节假日
让 AI 帮助计算特征间的比值(特别适用于需要提高线性模型解释性的场景)
-
使用 AI 清洗离散变量,修正空格、乱码、打字错误等问题
-
利用自然语言让 AI 判断缺失值、多重共线性、数据重复等问题
04
AI 提高数据科学工作效率的其他应用
1. 代码编写与处理

AI 在代码方面的应用表现视任务复杂度而定:
-
对于简单直接的任务,AI 表现相当出色
-
对于步骤多、复杂的任务,AI 容易出错,需要不断调整提示词;需要专业知识帮助 AI 调试,确保代码逻辑正确
-
有时 AI 会固执地输出错误代码,此时应放弃使用 AI
AI 在代码方面的其他有用应用:
-
帮助理解他人代码,辅助学习 -
在不同编程语言间转换代码(如 R 转 Python) -
将本地代码转换为云端处理代码(如转为 SQL 代码) -
优化代码计算效率
2. 数据可视化

AI 在数据可视化方面表现出色,可以根据自然语言描述生成 R 或 Python 的绘图代码。对 AI 而言,绘图是相对简单直接的任务,能创建美观、符合要求的图表。
3. 写作与沟通

比如今天的分享内容,向 AI 输入演讲主题概要,AI 协助构建了框架结构,随后再进行内容填充。
AI 在英语写作方面展现出卓越能力。对于非英语母语的国外工作者而言,英语写作在 AI 出现前一直是明显短板:撰写博士论文时,之前会专门聘请编辑协助修改,而现在这类任务可以交由 AI 完成。AI 能使文章达到信、达、雅的标准。
此外,AI 可以指导我们如何更有效地与上下级沟通、开展团队协作。在数据科学领域,有许多优秀数据科学家都属于内向型人格(INTJ)。这类人群的技术能力(technical skills)通常优于人际交往能力(people skills),不擅长与他人沟通。AI发展的这几年中,利用 AI 指导人际沟通有助于提升职场软技能。例如,需要向上级反映问题时,可以向 AI 学习表达得更有理有据,甚至会预测上级可能的回应并帮助准备应对策略。

数据科学家需要持续跟进最新研究成果,保持终身学习,AI在这方面也提供了帮助。AI 能够概括文献主要内容,使用时先了解AI的总结,再深入阅读感兴趣的部分。
然而,若让 AI 进行文献综述,效果仅能达到及格水平。虽然 AI 能涵盖一些重要文献,但对领域熟悉的人会发现其总结并不全面。
AI 还可以将文献中的新方法转化为代码。常见情况是,统计学新方法的作者仅在论文中提供算法描述而无具体代码,此时可请AI协助编写代码。值得注意的是,AI 处理多步骤的复杂任务时容易出错,因此不能完全依赖 AI。必须真正理解方法背后的逻辑,协助 AI 调试。
在知识问答方面,AI 对成熟概念的总结相当出色,但对前沿概念的解释可能存在不准确之处。
05
AI 的局限、人机协作及职业发展思考

1. AI 的局限性
通过对多种 AI 应用的探讨,可以看出 AI 仍存在诸多局限:
AI 常表现出“懂王”倾向,提供看似合理但实际可能有误的答案,需要专业人士进行判断。若使用者对相关领域毫无了解,盲目采纳 AI 建议而不理解其原理,容易被误导。
AI 难以处理复杂的多步骤问题,往往顾此失彼。每个步骤都需要具备专业技能的人员仔细评估。实践中应避免将复杂内容直接交给 AI 处理,而应将问题分解为小步骤。与 AI 协作类似于指导实习生,需要提供清晰简单的指令。
AI 倾向于总结现有思路,缺乏创新能力,大致相当于大学生水平,而非博士层次。人类专家更善于综合各种方法提出复合性创新解决方案。例如,本次峰会上的诸多演讲都基于专家创新,这不是 AI 能简单完成的。
此外还存在隐私问题,企业应限制员工使用公开 AI 平台,设置公司专用AI系统,禁止上传数据至大语言模型后台,以确保商业资料安全。
AI 对前沿知识的了解也较为有限,对数据科学家而言,最关键的环节是将商业问题转化为数据科学问题。这方面 AI 可以提供头脑风暴辅助,但无法全面思考或提供创新思路。
2. 人机协作与职业发展

关于 AI 时代的职业思考, AI 与数据科学家仍是互补关系:
确实有一些低端数据分析工作正在被 AI 取代,例如 ChatGPT 的 Advanced Data Analysis 工具已能胜任简单的数据分析工作。但如前所述,AI 有诸多局限,目前难以取代真正的专业技术人员。专家可利用 AI 提高工作效率,形成“强者通吃“格局——数据科学家若具备创新能力,且可以熟练使用 AI,其职场价值将更高。
最近一项有趣的中国经济学家研究发现,与 AI 互补的岗位变得更加内卷,工作效率提高但工作时间增加,员工满意度降低。积极方面是这些岗位的收入相对于非 AI 互补岗位有所增加。这反映了 AI 使专业技术人员更全能,形成赢家通吃的局面。

AI 时代企业招聘需与时俱进,在评估人才能力时,应从考察编码能力转向评估代码逻辑理解、AI 协作、识别 AI 错误及调试的能力。同时,从考察浅层知识转向评估深层理解,考察候选人是否关注前沿方法,是否具备将商业问题转换为数据科学问题的能力,以及结合不同方法进行创新的能力。
对于数据科学家,终身学习至关重要。我们需要追求前沿知识,善用 AI 成为全栈发展的数据科学家。在利用 AI 提高数据科学素养的同时,也可向 AI 学习,提升职场软技能,同时提高自身的数据科学专业能力和沟通交流能力。
06
Q&A
Q1:在结构化数据的小样本建模中,将结构化数据 XML 或 JSON 化后送入大语言模型(LM),通过提示词优化或参数高效微调(PEFT)进行分类建模,与传统机器学习(ML)建模的差距有多大?有相关的论文研究吗?
A1:我没有细读相关的研究文献,但可能存在一些相关研究。对于结构化数据,我确实没有实践经验。不过对于非结构化数据,人工智能模型能够达到较高的准确度。不一定需要将其输入大语言模型(LLM)进行处理,您可以尝试一些深度学习方法,但实际应用需视具体情况而定。根据我的经验,如果数据结构非常规范清晰,在许多情况下,基于树的模型(tree-based models)可能比深度学习模型表现更优,并且计算成本更低。
Q2:小样本数据可以考虑谷歌开源的预训练模型,据说效果不错,您尝试过吗?
A2:是的,我使用的正是谷歌的开源模型,效果确实很好。但如我之前所提到的例子,当数据量非常大时,处理速度会显著降低。对于几万条数据,可能 30 分钟内能完成处理,但若尝试用谷歌开源模型处理几千万条数据,则效率极低。因此我建议结合关键词搜索和语义搜索的方法,先通过关键词筛选缩小样本规模,然后再交由谷歌模型处理。
Q3:对于数据质量有什么好的评估方式?设计数据一直是痛点。
A3:这个问题与 AI 关联度不高。数据质量评估方法取决于具体数据类型,不同类型的数据有不同的质量衡量标准。不过,确实可以利用 AI 提高部分数据质量,例如我之前提到的分类编码(category code)中存在的乱码、空格或拼写错误(typo)等问题,可以让 AI 协助改进这些部分。
Q4:有什么垂直领域(垂类)大模型的评估体系?特定行业的模型,例如医学、金融等领域的专业模型。
A4:这实际上是我之前提到的从预训练通用模型到专业模型的转化。专业模型需要特定领域知识进行训练,以提高其在该领域的表现。


分享嘉宾
INTRODUCTION

徐萌
Snap Inc.
Tech lead of core data science
徐萌是 Snap Inc. 的 Tech lead of core data science,她从北京大学元培学院获得经济学和法学学士学位,从加州大学洛杉矶分校经济学系获得博士学位,其后加入了Snap Inc.,专注于利用观察数据进行因果推断。她的研究兴趣在于因果推断(Causal Inference),包括加权平衡方法(Balancing Approach)、合成控制(Synthetic Control)、因果中介分析(Causal Mediation Analysis)、因果机器学习(Causal Machine Learning)、随机对照试验中的选择问题(Selection Problem)、分位数回归(Quantile Regression)和方差缩减(Variance Reduction)。

往期推荐

点个在看你最好看
SPRING HAS ARRIVED