编者按:当你在使用 ChatGPT、Claude 或 Perplexity 时,是否好奇过为什么它们不仅能够回答你的问题,还能主动挖掘相关信息、交叉验证事实性信息,甚至提出你没想到的关联问题?为什么同样是 AI,有些只能机械地重复训练数据,而有些却能进行真正的“Deep Research”?
本文详细解析了 AI 研究助手从理解用户查询到答案生成的完整工作流程。作者基于对 Perplexity、ChatGPT 等前沿 AI 系统的理解,阐述了 ReAct 推理循环、向量搜索技术、RAG 检索增强生成等算法如何协同工作,让 AI 具备了“像人类一样思考和研究”的能力。
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。原文链接:https://diamantai.substack.com/p/ai-deep-research-explained
作者 | Nir Diamant
编译 | 岳扬

使用 Google 进行快速搜索与深度研究的本质区别是什么?当你搜索时,得到的只是一堆链接;而当你研究时,是在沿着问题脉络深入探索——交叉验证不同来源、质疑既有结论,并从多维度整合洞见。真正的研究是循环递进的 —— 每个答案都会引向新的问题,每一份资料都会暴露待补全的认知空白。
直到不久前,AI 还仅能做到像一本百科全书一样。你提问时,它要么从训练数据中提取答案,要么凭空捏造。但新一代的 AI 助手已习得人类的研究能力 —— 能顺着直觉深挖线索、主动核实事实,并像拼图般逐步构建认知框架。
这些系统不再停留于简单调取数据,而是展开真正的知识勘探。它们会主动质疑、多向探索、严格核验,最终融会贯通。面对复杂问题时,能将其拆解为子问题模块,追踪多条线索,交叉比对结论,最终形成逻辑严密的完整答案 —— 这就是查资料和真正解决问题之间的区别。
这也标志着 AI 能力从根本上进行了转变 —— 从静态知识库跃升为动态探索引擎。接下来,让我们从算法层切入,解析这些 AI 研究助手的运作机制,揭示其强大调查能力背后的复杂机制。

深度研究系统如何理解用户查询 (Query Understanding)
从你按下提问的“回车键”那一刻起,第一阶段的智能解析就已启动。AI 助手会深度理解你的需求 —— 它不再只是机械地匹配词汇,而是像人类一样进行解读。
想象你面前有一位经验丰富的图书馆管理员:你提出问题后,管理员会先确认你的真实需求 —— 是要具体的事实?还是全面的解析?还是实时的动态?同样,AI 助手会运用先进的语言理解技术,来精准解析你的意图。
如果你问“上周更名的那个国家的首都是哪里?”,系统会判定这是需要网络检索的、具有时效性的事实性问题;而“写一首关于月亮的诗”这类请求,系统就会意识到无需进行外部研究。
像 Perplexity 这样的系统会根据用户意图将用户查询转到相应的处理程序,Grok 会判断是否需要进行实时网络搜索 —— 若涉及热搜话题,它不仅会检索网页,还会抓取 X/Twitter 的最新推文。对于常识性问题,则可能完全跳过网络检索。
这种意图分析(intent analysis)制定了 AI 助手的行动蓝图:决定 AI 助手是否需要启动外部研究,以及以何种方式展开深度研究。
深度研究系统的研究循环 (The Research Loop)
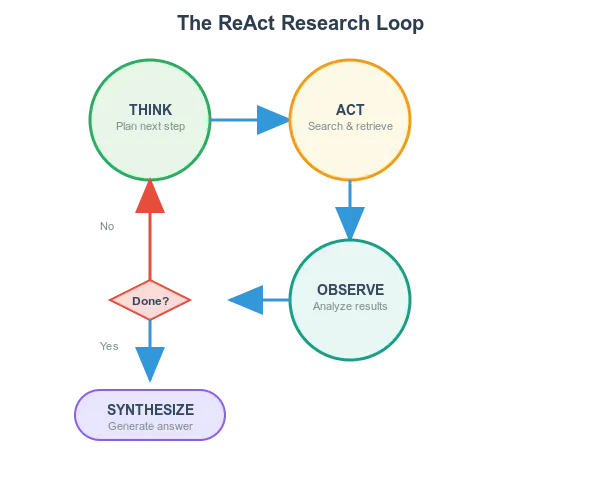
当 AI 判定需要进行外部研究(external research)时,就会启动名为 ReAct 模式(推理+行动)的决策循环 —— 这与人类研究者处理复杂问题的方式高度相似。
想象你在探究一个难题时的思考过程:
“我需要获取什么信息?或许应该先查证 X 数据…搜索 X 有了结果…这些线索表明需要进一步查证 Y…现在要将 X 和 Y 整合推导结论…”
AI 研究助手以闪电般的速度执行着几乎同样的事情:
-
思考(推理):AI 在思考、分析下一步应该怎么做。“用户询问 ChatGPT 首年的用户增长数据,应先检索其发布的内容详情”
-
行动:执行搜索操作。Search(“ChatGPT launch date user statistics”),生成检索指令并调用搜索引擎
-
观察:获取返回结果。“ChatGPT 于 2022 年 11 月发布,仅用两个月就获得 1 亿用户…”
-
二次思考:基于新数据,动态修正推理路径:“已掌握发布时间,但需补充首年度完整数据。现在检索详细的增长指标。”
-
二次行动:发起新搜索:Search(“ChatGPT user growth 2023 statistics milestone”)
这个研究循环会持续进行,直至 AI 获取足够的信息生成完整答案。ReAct 模式使语言模型升级为能自主思考、调用工具的智能体,既能处理复杂查询,又可避免因未核实事实而产生的幻觉输出。
信息检索 (Information Retrieval)
“行动”(Act)环节涉及将传统搜索与现代人工智能相结合的复杂检索机制。
3.1 构造有效、优质的搜索查询 (Crafting Effective Searches)
AI 助手会将您的请求转化为优质的搜索查询(search queries),通常会优化原有措辞或添加上下文。如果你的问题含糊不清,它可能会添加特定的关键词。这种查询构建过程受到智能体推理的指导 —— 它清楚每一步需要查找什么信息。
3.2 外部资源与内部资源 (External vs. Internal Sources)
许多 AI 助手会调用网页搜索 API(如 Bing、Google)来获取最新结果。而像 Perplexity 这样的 AI 助手,还会利用自己的网页爬虫(PerplexityBot)抓取并索引最新内容。
在这一过程的背后,通常使用的是向量搜索技术(vector search)。查询内容被预处理成数值化的嵌入向量(numerical embeddings),使系统能够快速找到语义相关的文档。诸如“iPhone 15 电池问题”这样的查询会被转换成嵌入向量,即使这些文档不包含完全相同的关键词,也能提取出概念上匹配的文档。
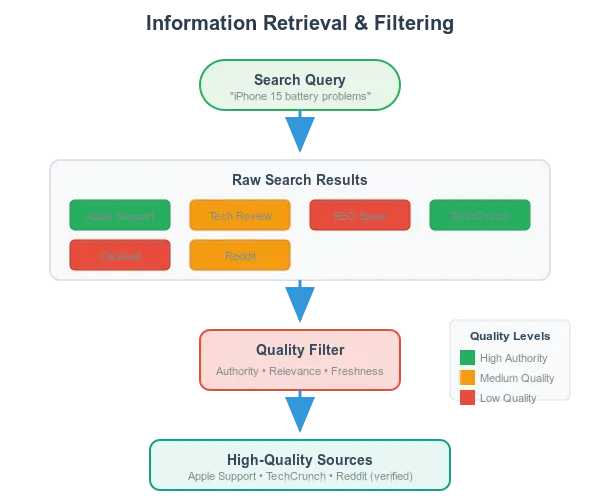
3.3 排序与筛选搜索结果 (Ranking and Filtering Results)
网页内容质量参差不齐。先进的 AI 助手会采用排序算法(ranking algorithms),优先选择值得信赖的相关内容来源。Perplexity 明确表示其“优先考虑权威、可信的内容来源,不喜欢过度 SEO 优化的或带有偏见的内容”,更青睐学术期刊和信誉良好的新闻网站,而非普通博客。
这种质量筛选机制确保 AI 的答案建立在坚实可靠的信息基础上,而非存疑的数据之上。
资料来源分析 (Source Analysis)
当 AI “打开”一个网页时,会解析文本内容并定位问题相关信息 —— 如同在多个文档间并发执行超高速的 Ctrl+F 搜索。
AI 助手会利用语言模型对每个资料来源进行摘要生成或关键点提取。如果其中一篇文章是维基百科,AI 就会精确定位相关章节,并将相关段落凝练为要点。
优秀的研究型 AI 会交叉验证不同来源的信息,而不是采信任何单一信源。如果资料来源 A 与资料来源 B 均显示“海王星有 14 颗卫星”,AI 助手就会相信这是可靠的。如果存在差异,它可能会进一步深挖或分情况进行解释。
这种交叉验证使检索增强系统 (retrieval-augmented systems) 比纯记忆模型更具事实准确性。
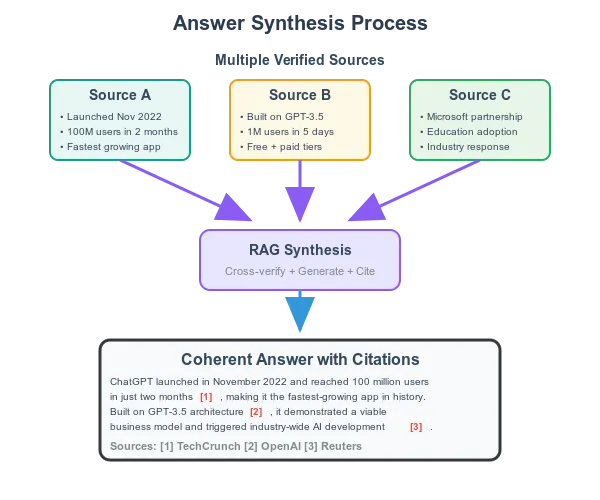
答案合成 (Answer Synthesis)
现在,神奇的事情来了:将收集到的事实信息综合成一个连贯的答案。当相关信息齐备后,AI 的任务就是将它们整合为结构清晰的完整响应。
想象一下你摊开所有参考书撰写论文的场景。系统会将精选信息与原始问题共同输入语言模型,其运作逻辑等同于发出指令:“这是待解问题,这是资料来源 A/B/C 提供的相关事实…请据此作答。”
这种技术称为检索增强生成(RAG):模型知识通过实时外部信息得到增强。由于答案生成时始终关联源材料,最终响应往往扎根于检索到的事实性信息,而非可能过时的模型记忆。
在整个过程中,资料信源可追溯系统会为每段具体的陈述附加引用标记。每段重要的事实性信息都会有一个编号脚注,链接至参考材料来源,既支持验证又增强可信度。
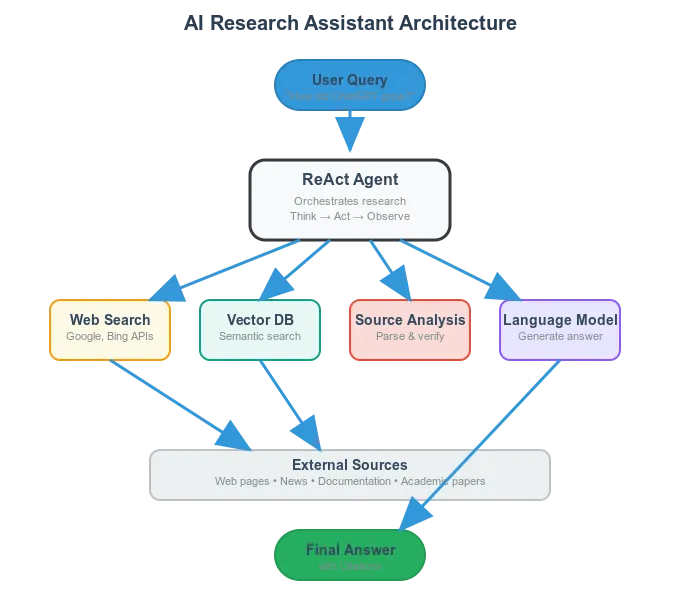
系统架构 (System Architecture)
这些研究助手由多个协同工作的组件构成,就像主厨调配专业的副厨团队一样。其中「主厨」是智能体逻辑层(遵循 ReAct 框架),而「副厨」是功能工具组(搜索 API/网页解析器/主 LLM/上下文管理器)。
当用户提出问题时,系统可能会先调用一个小型模型来决定「此问题是否需网络检索」,再由大语言模型生成搜索指令,搜索工具执行查询,解析模块提取结果 —— 所有组件都在一个循环中实时交互。
有些系统使用多个具有不同优势的模型 —— Perplexity 采用多模型路由机制(GPT-4o 处理复杂推理,更高效的模型应对简单问题)。部分系统还配备有后备验证模型,可以反复检查答案是否真正解决了问题。
AI 研究助手的算法设计为终端用户带来的可感知价值 (User Experience Benefits)
这些算法设计共同创造了以下核心价值:
实时知识更新:AI 研究助手可提供有关近期事件的信息,而旧版模型只会回答“我不知道”。现在一小时前发生的突发新闻也能即时获取。
更高的准确度 & 更少的幻觉:通过主动查找事实性信息并进行交叉验证,答案更加基于现实。AI 研究助手像是在“进行开卷考试”,而非依赖记忆盲目猜测。
引用内容非常透明:标注参考资料来源,使其可供查证并增强可信度。如同阅读一篇带有详尽脚注的深度文章。
响应内容与上下文相关:多步骤的处理方法确保 AI 能够精准定位用户的具体问题,通过准确获取所需内容来定制答案,而非机械地重复通用答案。
闪电般的速度:尽管需要进行多次搜索、阅读多篇文章并生成答案,得益于经过优化的系统后端和并行处理机制,所有结果都能快速返回。
END
本期互动内容 🍻
❓你平时是怎么验证 AI 给出信息的准确性的?有什么实用技巧?
本文经原作者授权,由 Baihai IDP 编译。如需转载译文,请联系获取授权。
原文链接:
https://diamantai.substack.com/p/ai-deep-research-explained

AI 及大模型技术分享交流群