

阿里妹导读
本文围绕 Cursor 编程助手 在日常开发中的应用展开,重点讲解其计费机制、工具调用方式、对话管理策略、Rules 规则配置等核心使用要点,并结合作者实践经验,总结出一套高效使用 Cursor 的方法论与避坑指南。
计费模式
在第一步最重要的就是cursor是如何计费的,很多同学以为cursor开通了会员以后,就可以无限制的免费使用,于是很快就将额度用完,在过去cursor计费是非常不好统计的,很容易就超出费用,但是在0.50版本以后,cursor统一了全部的计费模式,无论是Agent模式还是chat模式均采用交互次数进行计费,所谓交互次数,就是你问一个问题,cursor一次回答就记为一次交互次数,每个周期有500次免费的交互额度,在交互额度用完以后,只能额外付费(我记得是0.15刀一次)或者采用慢模式,也就是排队模式,使用体验不是很好。
基于这种计费模式的场景,我们应该尽可能的在一次会话中让cursor做尽可能多的事情,而不是简单的问一些问题,需要榨干他的每一分价值。
还有就是cursor规定在一次交互中,最多使用25次工具,比如读取文件就是一个工具,检索文件夹也是一个工具,在一次交互中如果超出25个工具,那么cursor就会需要你继续执行,就会额外进行一次交互次数的消耗,但是一般普通请求很难超过25个工具,所以一般不会额外请求。
在cursor中使用不同的模型有不同的价格:
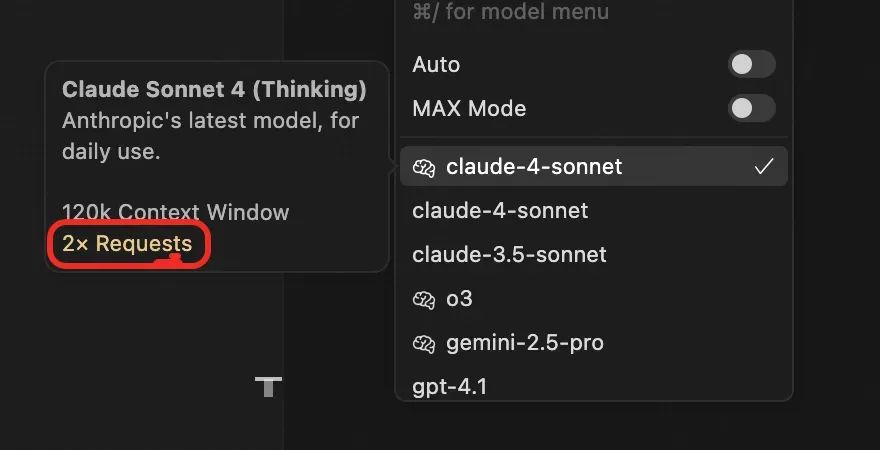
拉开模型选框可以看到选择不同模型的价格(上周这个模型还是0.75x)比如如果你使用深度思考的Claude那么一次交互就代表要消耗两次额度,所以在日常使用中,可以根据需求选择模型,cursor默认是auto选择模型的,我的建议是最好自己选择模型,cursor在选择模型时一定会考虑到自己的经济因素,我们开发代码最好默认选择Claude最新版本的模型即可,至于是否需要深度思考可以自行选择(我感觉区别不是特别大)。
最后简单介绍一个cursor的MAX模式,可以理解成cursor的超级赛亚人模式,支持超大上下文,取消25次工具的限制,读取文件行数增加,与之相对的就是超贵的收费额度,MAX模式不再简单的采用交互次数来进行计算,而是直接用大模型的费用来计费,cursor在中间收取20%的服务费,但是计费方式还是采用次数来进行计费,也就是将使用token的费用折算成次数展示在后台,比如你只有一次交互,但是cursor计算完成token以后,可能计费就是10次。我在计费重置之前用Max模式写了一个MCP工具,一下午就可以消耗300多个交互次数。
给大家贴一下cursor的计费板地址https://www.cursor.com/cn/dashboard在控制台中可以看到你当前每月使用的额度,以及额度重置的时间,大家要时常关注,避免超额使用影响体验。
cursor工具
接下来跟大家分享一下cursor中的工具使用,也就是用可以手动指定的一些工具方便大家更好的使用cursor。
![图片[1]-Cursor 0.50 版本升级后如何省钱又高效?一份给开发者的避坑指南 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/07/20250716_6876fc674b338.jpg)
在对话中通过@可以手动指定一些工具,其中大概能力如下:
-
files&folders:读取文件以及文件夹,可以让cursor重点观察一些文件;
-
docs:指定文档给cursor读取,并且如果你给cursor的文档最后是以/结尾的话,cursor会读取这个链接下的所有网页,比较适合读取一些开发说明文档;
-
git:读取git提交,可以进行一些提交内容的比较,用的也比较少;
-
past chat:过去的会话,cursor可以分析这些会话,并且加入到本次读取的上下文中;
-
cursor rules:cursor的规则,后面会着重讲,一般不会在聊天框使用;
-
terminals:终端,如果在终端运行命令时报错的话,可以用这个命令把这个终端告诉cursor让他解决;
-
linter errors:代码规范的错误,一般不会使用;
-
web:要求cursor先在网上检索,然后再进行交互,一般不会使用;
cursor使用小技巧
多对话框(新版本已优化)
在日常agent使用中,如果直接点击右上角的加号新开窗口,会导致当前的这个工作流暂停。

体验非常差,会导致我们浪费交互次数,但是cursor其实是支持后台运行对话框的,可以使用ctrl(command)+T新建对话框。
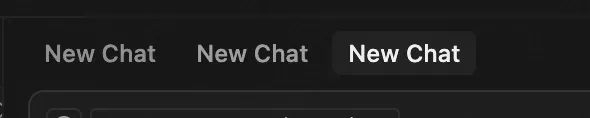
这三个对话框是独立运行的,每个都可以单独运行任务而不被打断,我的建议是每次使用直接打开三个tab,不要使用右上角的加号。避免工作流以及信息。
对话打断
在agent模式下,有些情况下AI的表现并不符合预期,但是如果要直接重新生成又很浪费时间,cursor是支持在上下文中进行打断的,如果你发现生成的文件大部分都不符合预期,那么就可以直接reset到checkpoint进行重置,但是如果大部分是正确的,只有最后的一小部分是不正确的,那么可以在错误生成之前的会话框中进行打断。
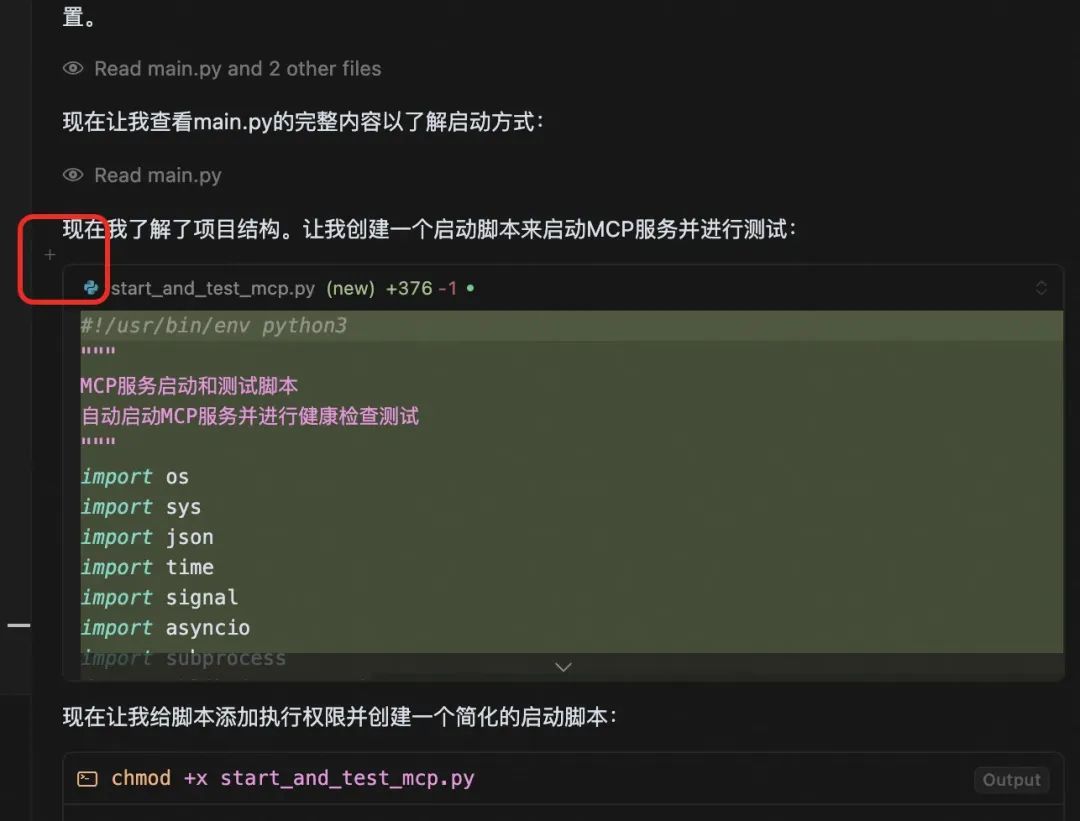
可以在这里点击这个加号,可以在这里输入新的描述,然后保存上面的修改然后回滚后续的修改,来继续生成。
单一职责原则
在cursor的使用中,我们尽量保证每一个对话框只做一件事,比如你需要开发一个简单的需求,那么这个需求就可以作为一个对话框,在这个对话框中完成全部的功能,但是如果你做的是一个非常复杂的需求,那么尽量把这个需求拆解开成为多个小需求,然后通过不同的对话框来完成。
因为在普通模式下,cursor的上下文是有限的,并且由于大模型的幻觉问题,上下文越长,那么大模型出现幻觉的情况会越来越严重,所以我们要尽可能的让对话框的上下文保持精简,避免由于上下文过长导致的大模型幻觉而无法完成任务。
但是这里需要注意的是,我们的单一指责是指整个对话框而不是一次交互,我们再一次交互尽依旧尽可能的完成多个任务,但是需要注意这些任务都是与本需求有关的,而不是把多个不相干的任务放在一个会话中,反而更影响cursor的表现。
任务拆解
使用cursor完成某项需求时,尽可能的将你的诉求描述的清晰,不要用一句话来描述你的需求,你需要更清楚的表达你的上下文,从而避免大模型理解错误从而浪费开发时间。
比如你的需求是实现一个评价系统,不能只说实现一个评价系统,而是将该需求拆分成一个一个的任务,并且按照顺序列出,比如:
我需要完成一个评价系统,你需要完成以下:
1.使用Evaluation作为评价实体;
2.创建Evaluation DTO作为传输类,并且提供Convert工具;
3.使用Evaluation中的itemId来关联商品id;
4.创建EvaluationFacade接口作为曝光接口;
5.EvaluationFacade需要实现,用户评价(用户id,评价内容,商品id)删除评价(用户id,评价id)能力;
6.创建EvaluationFacadeImpl实现EvaluationFacade;
7.同一个用户对同一个商品只能作出一次评价;
8…….
类似这种,将某个具体的需求,拆解成一个个的任务交给cursor去完成,而不是把你的需求一句话贴给他,这样可以使AI更高效的提升你需求的完成率。
对话引用
cursor本身是不会记忆你之前写过的需求的,当你有一个新需求需要之前使用cursor使用的代码的时候,如果直接让cursor去读取的话,cursor可能会判断有误,或者在某些场景下,当之前的某次对话已经产生幻觉了,但是问题还没有解决,你需要新开一个对话框但是又不想重复进行之前的对话,那么可以使用cursor中的@past chats功能来引用之前的对话,大模型会对该对话进行总结,将总结后的内容塞入本次的上下文中,帮助大模型更好的理解你之前的对话,提升任务的完成率。
画图+总结能力(汇报神器!!!)
在使用cursor完成一个需求以后,可以让cursor根据完成需求的方案,总结出一个工作的流程图,或者时序图等等 采用plantUML格式或者mermaid格式输出到一个文件中,可以使用语雀的文本画图功能展示出来,可以更好的留档,并且也可以把总结直接给cursor让他知道某个功能是如何实现的。

cursor rules
cursor rules是我认为cursor最核心的功能,也是提升cursor使用效率最高的方式,先简单介绍一下cursorrules是什么。
cursorrules是cursor默认需要遵守的规则,也就是全部的会话以及代码生成都是基于这个规则的,你可以理解为大模型的系统上下文,并且这个规则没有一个放之四海而皆准的规则,因为普通的代码规范如《阿里巴巴代码开发规约》早已经在大模型的知识库中了,在cursor的规则完全是基于你的项目或者你个人的开发规则,创建合适的规则可以使你的开发事半功倍。
cursorrules分为user rules和project rules,顾名思义,user rules就是针对你个人的开发规则,而project rules则是项目的开发规则,在首选项->cursor setting 中可以看到全部的规则。
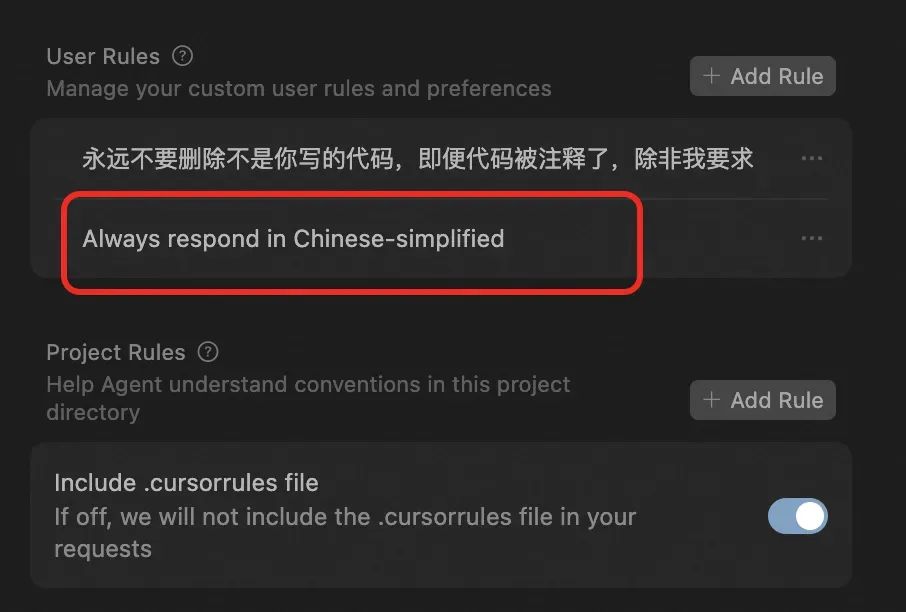
可以看到在user rules中默认有一条来规范大模型响应语言的规则,其他的规则可以通过右上角的add rule 来添加。
project rules相对来说就比较复杂,在过去的版本中,cursor只能使用根目录下的.cursorrules 文件来规范cursor rules,这就导致我们只能精简一部分规则放在文件中,在最近的版本,cursor优化了这部分能力,我们可以针对项目创建多个规则,并且所有使用cursor开发该项目的同学都可以使用。
创建project rules的方法与user rules相似,在user rules下方就是创建project rules,并且有一个开关来决定是否使用.cursorrules文件的规则。
点击project rules的add rule 后,会让你为这个规则起一个名字,然后就是详细的规则内容。
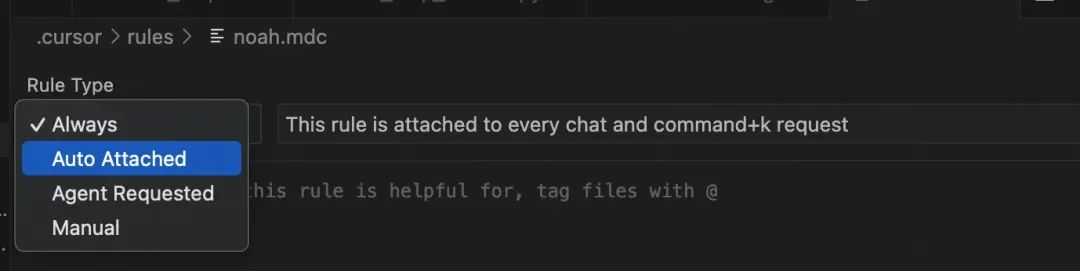
创建完成后会创建一个.mdc文件,这是markdown文件的一个拓展类型文件,你可以直接当做markdown格式进行编写,在左边的ruleType,则是这个规则的类型,主要分四种:
-
always:一定会被使用的规则;
-
auto attached:使用正则表达式匹配的规则,如文件后缀,文件格式,某个文件夹下等等;

-
agent requested:写入使用场景,由大模型来判断是否调用该规则;
-
manual:agent永远不会主动调用,除非手动指定该规则(基本不会使用);
可以根据需求来创建不同类型的cursor rules来使用。
而cursor的具体内容,可以让cursor来帮你写,比如定时任务中有一些开发规范,那么可以让cursor直接总结每个定时任务中的共性来总结一个cursor rules,或者你说一些简单的规则,cursor会根据你代码的上下文来写出一个完整的规则。
那么什么时候判断应该修改cursor rules呢,在我的经验中,如果某一个规则你需要在开发中反复跟他强调,那么你就要考虑将它总结成一个cursor rules。
cursor的坑
cursor无法读取jar包
cursor无法正确判断jar包中的接口,所以在新建rpc的时候要明确说明调用方法以及响应结果,并且使用哪个字段也要说清楚,否则cursor会使用object作为响应结果,然后采用反射调用,生成无用代码,也可以生成cursor规则要求cursor规范rpc的调用使用。
cursor会偷懒
cursor在解决问题,如果尝试了很多次无法解决后,就可能想办法把这个问题掩盖过去,比如有一个验证功能的脚本运行有问题,cursor在尝试解决两次无法解决后,就开始修改验证功能的脚本让验证看起来成功,所以在尝试让cursor解决问题时,尽量让cursor不要修改验证脚本,也可以把它生成成一条规则。
慎用checkpoint
在cursor对话中,每次会话前cursor都会保留一个checkpoint,如果生成不满意,cursor会将代码回滚到checkpoint点的样式,但是如果多次交互,或者多个会话,都会导致checkpoint不稳定,所以同学们还是善用版本管理工具,只在单次会话中使用checkpoint回滚。
谨慎验证cursor修改
每次提交代码时,一定要验证cursor每次修改的内容范围,不要修改完毕直接提交,因为cursor可能会修改预期之外的代码,一定要验证提交内容,避免可能导致的预期之外的bug。
Flink CDC 实现企业级实时数据同步
传统的数据集成通常由全量和增量同步两套系统构成,在全量同步完成后,还需要进一步将增量表和全量表进行合并操作,这种架构的组件构成较为复杂,系统维护困难。本方案提供 Flink CDC 技术实现了统一的增量和全量数据的实时集成。
点击阅读原文查看详情。












