导读 生成式 AI 的应用与大模型的开发是一个复杂的过程,涉及从模型选择、微调到部署和监控的全生命周期管理。通过精细化的角色划分,提供者负责构建基础大模型,调优者进行行业定制化优化,消费者则在此基础上应用模型解决实际问题。技术上,检索增强生成(RAG)和高效微调(如 PEFT)等方法有助于提升模型的准确性和适应性。亚马逊云科技的生成式 AI 服务通过简化的 API 接口,支持用户快速调用和定制大模型,提供持续优化和监控功能,确保模型在实际应用中的稳定性和效果。整个流程需要严格的评估、反馈和优化,才能推动生成式 AI 在各行业中的有效落地和持续改进。
本次分享的主要内容包括:
1. 生成式 AI 用例
分享嘉宾|王宇博 亚马逊云科技 开发者关系负责人,首席布道师
编辑整理|陈思永
内容校对|李瑶
出品社区|DataFun
生成式 AI 用例
1. 生成式 AI 用例:电子邮件摘要生成器
![图片[1]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6a8cdd5b.png)
2. 从小处着手,从大处着想
![图片[2]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6a9ae5d0.png)
-
核心诉求:用户希望通过大模型快速获得电子邮件的摘要,这需要将大模型应用于信息提炼。 -
扩张思考:摘要生成后,用户可能需要查阅相关文档、产品能力介绍、服务说明等,这需要更复杂的关联功能来实现。 -
未来规划:随着技术的进步,期望大模型能帮助用户解决更多的领域细节问题。
MLOps 与 LLMOps
![图片[3]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6aae6b30.png)
-
模型的适应性与可扩展性:大模型的一个主要挑战是其适应性和可扩展性。随着企业和项目的需求变化,如何让大模型在不同的场景中都能高效工作,是一个技术难题。例如,一个专为电子邮件摘要设计的大模型,如何在客户服务、技术支持或市场营销等多领域中都能产生有用的信息?这需要模型具有较高的泛化能力,能够根据实际场景灵活调整。 -
成本问题:大模型的训练和部署通常需要庞大的计算资源,这使得它们在生产环境中的运维成本非常高。为了应对这一挑战,云计算和分布式技术的结合显得尤为重要,尤其是采用云端结合的架构来优化成本和计算资源的利用。 -
隐私保护与数据安全:大模型在处理大量敏感数据时,如何确保用户隐私和数据安全是一个亟待解决的问题。尤其是在处理电子邮件或企业内部通讯时,数据泄露或模型训练过程中不当的数据使用可能带来巨大的风险。对此,需要加强数据加密、合规审查、去标识化等技术措施。
![图片[4]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6ac21e18.png)
![图片[5]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6ad08137.png)
-
人:按人群画像,分为模型提供者、模型微调者和消费者。
-
型号选择:包括专有模型还是开源模型的选择,模型大小,并综合考虑性能、准确率、成本,以及许可证。
-
版本控制的构件:包括提示、LLM 版本、LLM 超参数,以及数据集。
-
编排:将 LLM 连接到外部存储器、代理、数据库。
-
调整模型:包括提示工程、RAG、微调。
-
评估模型:包括多任务、场景,以及各项指标。
-
部署模型:需要考虑单租户或多租户形式,以及成本、延迟、量化和数据隐私等多个方面。
-
长期监控性能:大模型可能出现偏见或幻觉问题,需要依据人类反馈长期监控。
![图片[6]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6ade50dc.png)
-
提供者:提供者负责从头开始构建大模型。这包括数据处理以及模型的训练、调优、部署和推理等工作。提供者在技术上需要具备端到端的大模型构建能力,并能够针对不同的业务需求设计或选择合适的模型。 -
调优者:调优者通常是基于提供者提供的基础大模型进行微调,以满足特定领域和应用场景的需求。他们将调整后的模型作为服务(Model as a Service)提供给消费者。调优者需要具备扎实的机器学习技能,尤其是在模型部署、推理、调参方面,同时需要有一定的行业知识,如教育、医疗、金融等,才能更好地进行领域定制化调优。 -
消费者:消费者是最终使用大模型的用户,通常集中在应用开发领域。消费者不一定需要具备深入的机器学习知识,但需要具备对业务领域的深刻理解。通过提示工程,他们能帮助模型更好地适应实际应用场景。消费者在实际应用中是大模型的最终使用者,他们的需求和反馈对于大模型的优化至关重要。
构建核心用例
![图片[7]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6aea490b.png)
![图片[8]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6af5e638.png)
![图片[9]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b02ae97.png)
![图片[10]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b1c5eaf.png)
![图片[11]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b2ba0e9.png)
![图片[12]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b3c2fd3.png)
![图片[13]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b4a1260.png)
-
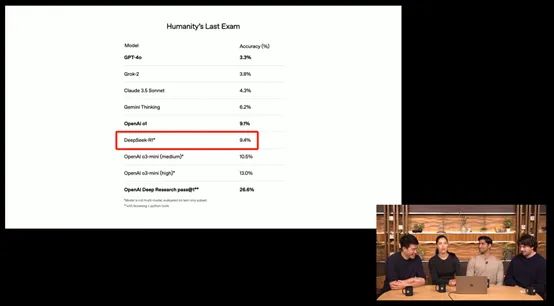
实例测试:例如,针对特定问题(如当前英国首相的名字),用不同的模型生成答案,并根据实际准确度、时效性等标准进行评分。
-
评分与反馈:通过定量的评分和定性的反馈来评估模型,结果可形成一个基于实际应用的“评分表”,帮助开发者决定最终选择的模型。
![图片[14]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b55731c.png)
![图片[15]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b689e3e.png)
![图片[16]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/20250213_67add6b778112.png)
-
RAG 的工作原理:RAG 结合了生成模型和检索模型,首先通过检索机制从大量的数据源中获取与任务相关的信息,然后利用这些信息作为上下文输入到生成模型中,生成更加准确且有用的结果。这种方法有效弥补了大模型在缺乏外部知识支持时的局限性,尤其在处理动态数据或时效性要求较高的任务时表现尤为突出。 -
提升生成准确性:通过集成检索功能,RAG 能够在生成过程中引入更多的背景知识,提高生成内容的准确性和相关性。例如,在自动化客服系统中,RAG 可以实时检索最新的产品文档和用户反馈,以生成更加符合用户需求的答案。 -
支持多领域知识:RAG 不仅能够增强生成模型的知识广度,还能更好地支持特定行业的需求。
![图片[17]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/accesswximgaid99120urlaHR0cHM6Ly9tbWJpei5xcGljLmNuL21tYml6X3BuZy96SGJ6UVBLSUJQalh5WUxTeFVkaWJPOGliWk1tbnBQSm01VGliRzl2MGNoaWM1VlZNNkNOdlRvbDZnOTk0M3d0M09ScTNBTWljQkFlNnRCOGFWa2RhSnMzUjBBLzY0MD93eF9mbXQ9cG5nJmFtcAfromappmsg.png)
-
评估和选择模型:由于大模型通常是“黑盒”的,选择合适的模型至关重要。评估时需考虑多个因素,包括模型的准确性、处理速度、资源消耗等。同时,需要通过调整输入的上下文信息,使得模型能够生成符合预期的结果。 -
人机交互与反馈优化:生成 AI 的成功应用不仅依赖于初始的模型能力,还需要通过不断的用户反馈来优化生成结果。用户的互动行为(如对生成内容的评分或评论)能够为模型提供改进的方向,从而不断提升系统的响应能力。 -
个性化微调:微调是优化生成 AI 模型的一种常见方法,尤其是在面向特定行业或领域的应用时。例如,通过上传行业数据、用户历史记录等进行微调,模型可以生成更加个性化和定制化的内容,满足特定用户的需求。
![图片[18]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/21_d3hfZm10PXBuZyZhbXAfromappmsg.png)
调优之旅
![图片[19]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/accesswximgaid99120urlaHR0cHM6Ly9tbWJpei5xcGljLmNuL21tYml6X3BuZy96SGJ6UVBLSUJQalh5WUxTeFVkaWJPOGliWk1tbnBQSm01MlRiREg2ZUY0aWJXSnA3bGxpYXJPM0c1RzRyb3FtbEdUTThMS0Z4Rk5PVzVZcFJoWm1kUUlEYncvNjQwP3d4X2ZtdD1wbmcmYW1wfromappmsg.png)
-
数据标注:数据标注是微调过程中的一个关键步骤,它为模型提供了学习的基础,帮助模型更好地理解和处理特定任务。在微调时,数据的标注质量直接影响模型的最终效果,因此,确保标注数据的准确性和高质量至关重要。
-
模型微调:通过修改模型的参数或训练策略,使其在特定领域(如金融、医疗、法律等)表现更好。
-
部署和提示工程:需权衡准确度、延迟和成本等多方面因素。
-
监控:模型部署后的监控是确保生成式 AI 能够稳定、有效运行的重要步骤。通过用户反馈、打分等手段持续优化模型。
![图片[20]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/accesswximgaid99120urlaHR0cHM6Ly9tbWJpei5xcGljLmNuL21tYml6X3BuZy96SGJ6UVBLSUJQalh5WUxTeFVkaWJPOGliWk1tbnBQSm01aWJaOTg1QUlocUN1QUNHMGljeEgwMUoxRlN0ZjdpY1hJdlZnN2ZIVkU1Y2tiV2xJMWlhYWdOMmljbGcvNjQwP3d4X2ZtdD1wbmcmYW1wfromappmsg.png)
![图片[21]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/accesswximgaid99120urlaHR0cHM6Ly9tbWJpei5xcGljLmNuL21tYml6X3BuZy96SGJ6UVBLSUJQalh5WUxTeFVkaWJPOGliWk1tbnBQSm01eXRBaWJTN2xONldLMGlielVzMEFpYlZsc3VhMlZGVnJVUnJLdDFJVGhTenJkQ2JTelVqZVZERnF3LzY0MD93eF9mbXQ9cG5nJmFtcAfromappmsg.png)
![图片[22]-亚马逊云科技:LLMOps驱动生成式 AI 应用的运营化 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2025/02/accesswximgaid99120urlaHR0cHM6Ly9tbWJpei5xcGljLmNuL21tYml6X3BuZy96SGJ6UVBLSUJQalh5WUxTeFVkaWJPOGliWk1tbnBQSm01UDFIbkFkRDROS3B0QlBmMlFia2tOYnl2VjV0TTgzamJzWVZrdTAyYUJjSHdrd0drcmx3Rk5BLzY0MD93eF9mbXQ9cG5nJmFtcAfromappmsg.png)