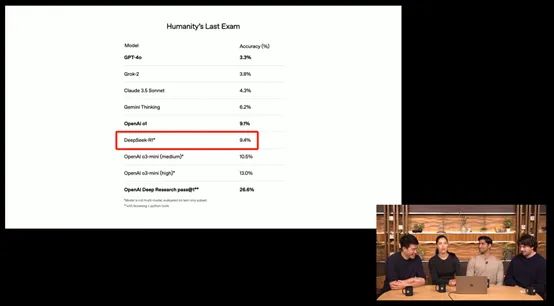
![图片[1]-Codex 6连更:AI看屏、锁屏控制、自主干一整天 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2026/07/20260709_6a4f481399579.jpg)
Appshots:双击 Command,让 AI 看到你的屏幕
这次更新最让我眼前一亮的功能。
以前跟 AI 编程助手协作,最烦的是什么?给它上下文。你得把报错截图、复制代码、描述问题……光"喂信息"就花掉一半时间。
Appshots 的解决方式粗暴但管用:在 Mac 上,同时按一下左右 Command 键,Codex 会自动截取当前最前面那个应用窗口的截图 + 提取其中的文字内容,直接塞进对话里。
![图片[2]-Codex 6连更:AI看屏、锁屏控制、自主干一整天 - AI资源导航站-AI资源导航站](https://www.aitube.vip/wp-content/uploads/2026/07/20260709_6a4f481440445.jpg)
关键细节:
- 不只截你看得见的部分,窗口里滚动区域之外的文字内容也会被提取,Codex 能拿到的上下文远比你手动复制粘贴多
- 所有 Mac 计划(Free/Pro/Team)都能用,企业版后续上线
- 操作路径极短:双击 Command → 选窗口 → 自动附带截图+文字到对话
说白了,这个功能解决的是人机协作里最大的摩擦——上下文传递。与其你费劲描述"我的 Figma 里这个按钮的颜色不对",不如让 AI 直接看一眼。
Goal 模式正式毕业:让 AI 干几个小时甚至几天
之前是实验性功能,现在正式上线了,覆盖 Codex 桌面应用、IDE 插件和 CLI 三端。
Goal 模式解决的问题也很明确:有些任务不是一个回合能搞定的。
比如"重构这个模块的认证逻辑",可能需要跨好几个文件,涉及数据库 migration、API 变更、前端适配……传统模式下你得一步步指挥。Goal 模式下,你给 Codex 定一个目标,它会自己规划、自己执行、自己检查,中间你随时可以介入调整方向。
几个实用技巧:
- Side chat:开一个侧边对话查看当前任务进展,不打断主任务
- Pause & Steer:中途暂停、调整方向,不用从头来
- 跨时间持久:目标可以跨小时甚至跨天,Codex 会记住进度
从 Codex CLI 0.133.0 的 changelog 来看,Goal 模式这次是实打实地做了底层重构——有了专门的 Goal 存储数据库,进度跨会话追踪,不再是之前靠上下文窗口"硬记"的土办法。
锁屏远程操控:人走了,AI 还在干活
这个功能有点科幻感——你的 Mac 锁屏了,Codex 还能继续操作桌面应用。甚至可以从手机上的 Codex Mobile 远程操控。
先说 Computer Use 本身。Codex 的 Computer Use 不是简单的远程桌面,而是一套完整的 GUI 操作系统:它能看到屏幕、截图、操作窗口菜单、模拟键盘输入、读取剪贴板。前提是你授予了 macOS 的屏幕录制和辅助功能两项权限。安装方式也很简单——Codex 设置里找到 Computer Use,点 Install,然后按系统提示授权就行。
适用场景很广:
- 测试 macOS 应用或 iOS 模拟器流程
- 复现只在 GUI 中出现的 bug
- 修改必须点击 UI 才能改的应用设置
- 操作没有插件/MCP 接入的数据源
- 执行跨多个应用的流程
用法也很直觉——在 prompt 里 @Computer 或 @AppName,或者直接说“用 computer use 打开 XX 应用”:
用 computer use 打开应用,复现 onboarding 流程里的 bug, 然后修复导致 bug 的最小代码路径。每次改完后重新跑一遍 UI 流程。
锁屏模式(Locked Computer Use) 是这次的新功能。核心原理:Codex 安装了一个 Apple authorization plug-in,参与 macOS 的解锁流程。
但设计上非常克制——它不是一个通用的远程解锁通道,别人(或其他应用)没法通过这个机制解锁你的 Mac。只有 Codex 在活跃的、受信任的 Computer Use turn 内,才能触发临时解锁。
安全机制做了几层:
- 短时授权窗口:解锁窗口只在当前尝试期间生效,不是一直开着
- 仅限 Codex:自动解锁只对 Codex 的 Computer Use turn 开放,其他应用/进程无法利用
- 覆盖所有显示器:临时解锁期间,所有屏幕都会被覆盖显示,防止信息泄露
- 本地输入立即中断:一旦检测到本地键盘或鼠标输入,立刻重新锁定并暂停自动解锁,直到你手动解锁
- 手动解锁兜底:遇到任何异常,手动解锁即可完全接管
几个值得注意的限制:
- 不能操作终端应用和 Codex 自身(防止绕过 Codex 安全策略)
- 不能以管理员身份认证,也不能批准系统安全和隐私权限弹窗
- 文件编辑和 shell 命令仍遵循 Codex 的沙箱和审批设置
- 目前仅 macOS(EEA、英国、瑞士暂不可用)
典型场景:你在公司跑着 Codex 做前端调试,下班锁屏走人。回家路上掏出手机,打开 Codex Mobile 看看进展,甚至远程点两下让它改个配色。人不在电脑前,活照样干。
浏览器标注升级:设计师终于能精准反馈了
Codex 内置浏览器做了一波体验优化,重点在"标注"功能:
- 直接调整页面元素:不用口头描述"这个字太小了",直接在页面上改字号、颜色、间距,Codex 能看到你的修改
- 即时预览:改完马上看到效果,不用等一个完整的 turn
- 批量标注:一次性标记多处需要修改的地方,不用来来回回说
配合 Chrome 扩展的改进——不再创建标签组(之前很多人吐槽这个),改用标签图标显示状态,Windows 可靠性也修了一波。
对设计师和前端开发者来说,这个更新大幅降低了"说清楚我要什么"的成本。
团队插件共享
Business 用户现在可以把自建插件分发给整个团队了。Plugin 里可以包含技能、应用集成和 MCP 服务器。
Enterprise 版本还在路上,但方向很明确:把 Codex 从个人工具变成团队基础设施。团队内部的工具链、代码规范、部署流程,都可以打包成插件统一分发。
Analytics 升级:老板终于知道钱花哪了
这次还给 Business 和 Enterprise 加了更详细的分析面板:
| 维度 | 说明 |
|---|---|
| 活跃用户 | 谁在用、用了多少 |
| Credits 消耗 | Token 用量一目了然 |
| 代码行数 | AI 生成了多少代码 |
| 插件使用率 | 哪些插件最受欢迎 |
| 用户排行榜 | 团队里的 AI 使用达人 |
配合 Analytics API,企业可以把 Codex 用量集成到自己的内部看板。
说到底,OpenAI 在押注什么?
把这 6 个更新串起来看,一条暗线很清楚:Codex 正在从"代码生成器"变成"开发操作系统"。
Appshots 让 AI 获得了视觉上下文 → Goal 模式让 AI 能长期自主执行 → 锁屏控制让 AI 不受物理位置限制 → 浏览器标注让 AI 理解设计意图 → 插件共享让团队标准化 → Analytics 让管理层看得见 ROI。
每一环都在降低"人指挥 AI"的成本,提高"AI 自主干活"的上限。
当然也有槽点——评论区一堆 Windows 用户在哭,Appshots 和锁屏远程控制目前都是 Mac Only,Chrome 扩展在 Windows 上的稳定性还刚修完。OpenAI 的产品节奏明显跟着苹果生态走,这事儿短期内改不了。
竞争对手方面,Claude Code 同一天发了 2.1.147 更新(Workflow 确定性多智能体编排),Cursor 也在持续迭代。AI 编程赛道的竞争已经从"谁的模型写代码更准"升级到"谁的开发体验更丝滑"——而体验的关键,是减少你描述需求的时间,增加 AI 执行的时间。