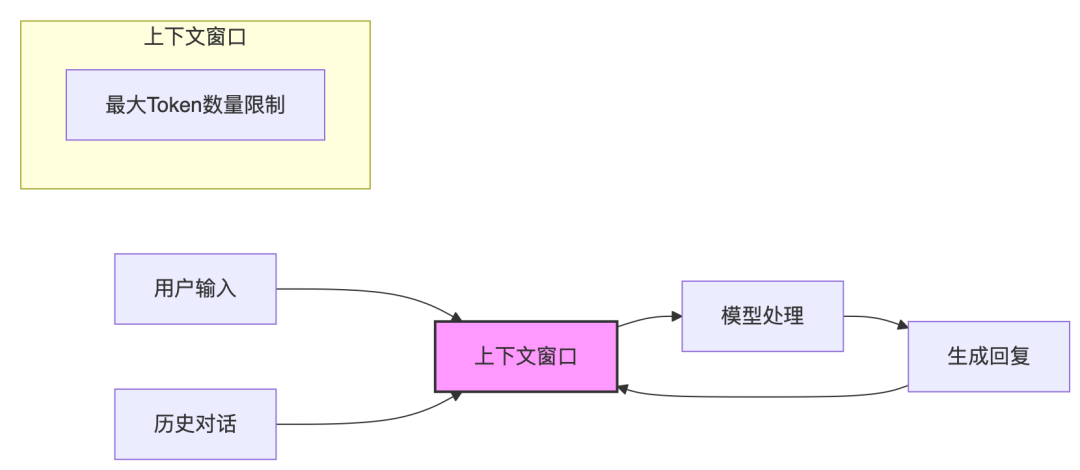
一、上下文长度的重要性与挑战
大模型(LLM)正扮演着越来越重要的角色,它们在文本生成、机器翻译、问答系统等多个任务中展现出强大的能力。然而,LLM 的一个关键瓶颈在于其上下文长度的限制。
-
什么是上下文长度? 简单来说,就是模型在处理一个任务时,能够“记住”多少历史信息。上下文长度越长,模型就能够理解更复杂的语境,处理更长的文档,完成更高级的任务。
-
为什么上下文长度很重要? 想象一下,如果让 LLM 阅读一本小说,然后回答关于小说情节的问题。如果 LLM 的上下文长度很短,它可能只能记住最近几句话的内容,而无法理解整个故事的来龙去脉。因此,更长的上下文长度意味着更强的理解能力和更广泛的应用场景。
-
扩展上下文长度的挑战: 尽管上下文长度很重要,但扩展 LLM 的上下文长度并非易事. 现有的方法往往面临以下挑战:
-
性能下降: 在扩展上下文长度的同时,模型在原始短上下文任务上的性能可能会下降。
-
训练成本高昂: 为了保持性能,通常需要使用大量的训练数据进行微调,这导致训练成本大幅增加。
-
技术复杂性: 一些方法需要复杂的多阶段训练策略,增加了系统复杂性。
因此,如何在扩展 LLM 上下文长度的同时,保持其在原始任务上的性能,并降低训练成本,成为了一个亟待解决的问题。这正是 LongRoPE2 想要解决的核心问题。

二、LongRoPE2:核心创新
这篇论文的核心贡献在于提出了 LongRoPE2,一种能够近乎无损地扩展 LLM 上下文长度的方法。 简单来说,LongRoPE2 能够在扩展 LLM 上下文长度的同时,最大限度地保持其在原始短上下文任务上的性能,并且只需要较少的训练数据。
LongRoPE2 的核心创新点主要体现在以下三个方面:
创新1: 新的 RoPE OOD 假设
-
RoPE(旋转位置嵌入) 是目前 LLM 中常用的一种位置编码方法。它通过旋转的方式将位置信息嵌入到词向量中,使得模型能够感知到词语之间的相对位置关系。
-
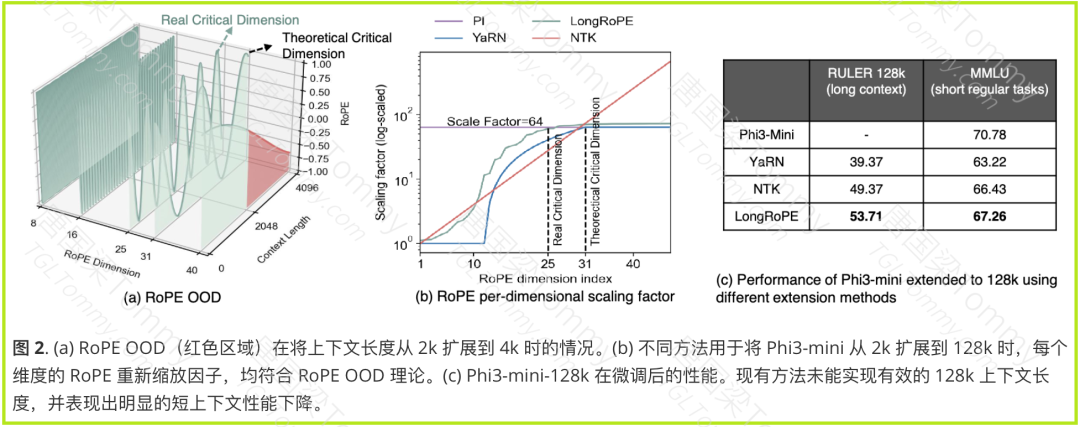
OOD(超出分布) 问题是指模型在处理超出训练数据范围之外的输入时,性能会显著下降. 在扩展上下文长度时,由于 RoPE 的周期性,模型可能会遇到在训练期间没有见过的位置编码值,从而导致 OOD 问题。
-
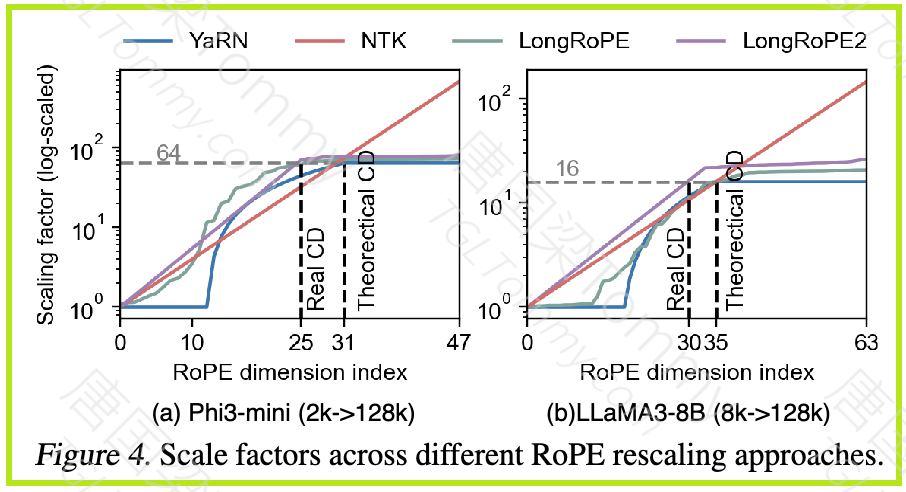
LongRoPE2 认为,RoPE 中较高维度的训练不足是导致 OOD 问题的根本原因。由于较高维度的 RoPE 在预训练期间的旋转周期不完整,因此在扩展上下文时会产生 OOD 值。
创新2: RoPE 重缩放因子搜索
-
为了解决 RoPE 的 OOD 问题,LongRoPE2 提出了一种 RoPE 重缩放算法。该算法通过调整 RoPE 的旋转角度,使得模型在扩展上下文长度时,仍然能够获得合理的 RoPE 值。
-
进化搜索: LongRoPE2 采用 进化搜索 来寻找最佳的重缩放因子。进化搜索是一种模拟生物进化过程的优化算法,它通过不断迭代、选择、交叉和变异等操作,逐步逼近最优解。
-
Needle-driven 困惑度评估: 为了更准确地评估重缩放因子的效果,LongRoPE2 提出了一种 Needle-driven 困惑度评估方法。该方法使用合成的 “needle” 数据来指导搜索,仅关注长文档中需要深度上下文理解的特定答案 tokens 的困惑度。
创新3: 混合上下文窗口训练
-
为了在扩展上下文长度的同时,保持模型在原始短上下文任务上的性能,LongRoPE2 提出了一种 混合上下文窗口训练方法。
-
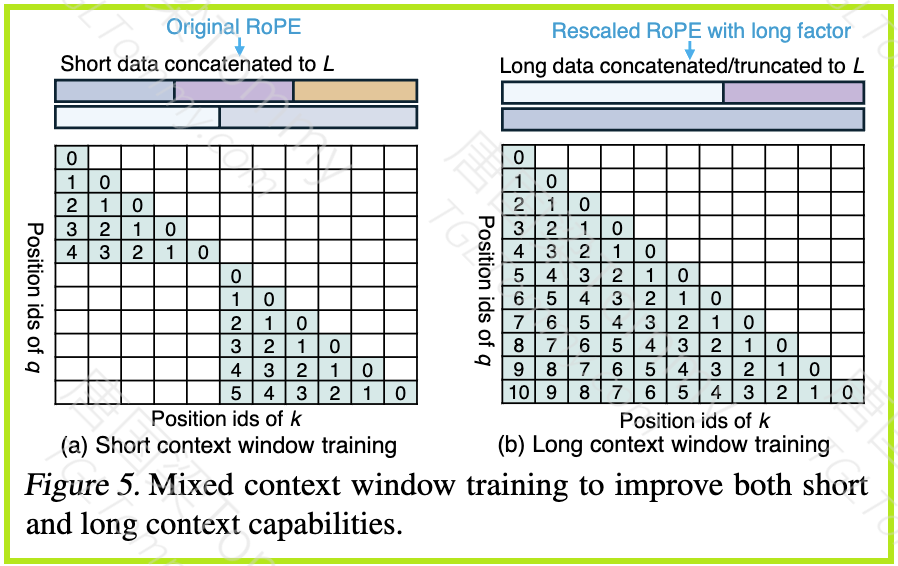
该方法同时训练具有原始 RoPE 的短上下文窗口和具有重缩放 RoPE 的长上下文窗口。这样,模型既能够适应长上下文序列的重缩放 RoPE,又能够保持在短上下文任务上的性能。
三、方法解析:技术细节与实现
接下来,我们深入了解一下 LongRoPE2 的方法细节,看看它是如何一步步实现上下文长度扩展的。
3.1 新的 RoPE OOD 假设
LongRoPE2 的核心假设是 RoPE 中较高维度的训练不足。为了理解这个假设,我们需要先了解 RoPE 的工作原理。
-
RoPE 的周期性:RoPE 是一种周期函数,每个维度的周期长度由其旋转角度决定。
-
公式:
Ti = 2π / θi,其中Ti是第 i 个维度的周期长度,θi是第 i 个维度的旋转角度。 -
维度与周期长度的关系: RoPE 的旋转角度
θi随着维度 i 的增加而减小,导致较高维度的周期长度较长。 -
训练数据与周期覆盖: 在预训练期间,较低维度的 RoPE 经历了多次完整的旋转周期,获得了充分的训练。而较高维度的 RoPE 可能只经历了不到一个完整的旋转周期,导致训练不足。
举例: 想象一下一个旋转的摩天轮。
-
较低维度就像一个转得飞快的摩天轮,在预训练期间转了很多圈,每个位置都被充分训练。
-
较高维度就像一个转得很慢的摩天轮,在预训练期间可能只转了半圈,有些位置根本没被训练到。
LongRoPE2 认为,这种较高维度的训练不足是导致 OOD 问题的根本原因。
3.2 RoPE 重缩放因子搜索
为了解决 RoPE 的 OOD 问题,LongRoPE2 提出了一种 RoPE 重缩放算法。该算法的核心在于 寻找最佳的重缩放因子 λi,用于调整 RoPE 的旋转角度。
-
重缩放公式:
θ̂i = θbase / (λi * 2i/d),其中θ̂i是重缩放后的旋转角度,θbase是原始的 RoPE 基础值,λi是第 i 个维度的重缩放因子。 -
重缩放的目标: 通过调整重缩放因子
λi,使得较高维度的 RoPE 值在扩展上下文长度时,仍然落在预训练期间见过的范围内。
LongRoPE2 使用进化搜索来寻找最佳的重缩放因子。
-
进化搜索的步骤:
-
初始化种群: 随机生成一组候选的重缩放因子。
-
评估适应度: 使用 Needle-driven 困惑度评估方法,评估每个候选重缩放因子的性能。
-
选择: 选择性能最好的候选重缩放因子,作为下一代的基础。
-
交叉: 将选择出的重缩放因子进行交叉操作,生成新的候选重缩放因子。
-
变异: 对新的候选重缩放因子进行变异操作,引入一定的随机性。
-
重复: 重复步骤 2-5,直到找到最佳的重缩放因子。
-
Needle-driven 困惑度评估:
-
传统困惑度的不足: 传统的困惑度评估方法会平均所有 tokens 的损失,这可能会忽略长文档中需要深度上下文理解的特定答案 tokens。
-
Needle-driven 困惑度的优势: Needle-driven 困惑度评估方法只关注长文档中需要深度上下文理解的特定答案 tokens 的困惑度,从而更准确地评估重缩放因子的效果。
3.3 混合上下文窗口训练
为了在扩展上下文长度的同时,保持模型在原始短上下文任务上的性能,LongRoPE2 提出了一种混合上下文窗口训练方法。
混合训练的策略:
-
短上下文训练: 使用原始 RoPE,并在短序列上进行微调,以保持预训练性能。
-
长上下文训练: 应用重缩放的 RoPE,并在长序列上进行微调,以实现有效的长上下文理解。
通过混合上下文窗口训练,LongRoPE2 能够让模型同时掌握短上下文和长上下文的处理能力。
四、实验结果:性能提升与优势
为了验证 LongRoPE2 的有效性,作者在 LLaMA3-8B 和 Phi3-mini-3.8B 上进行了大量的实验. 实验结果表明,LongRoPE2 在多个基准测试上都取得了显著的性能提升。
-
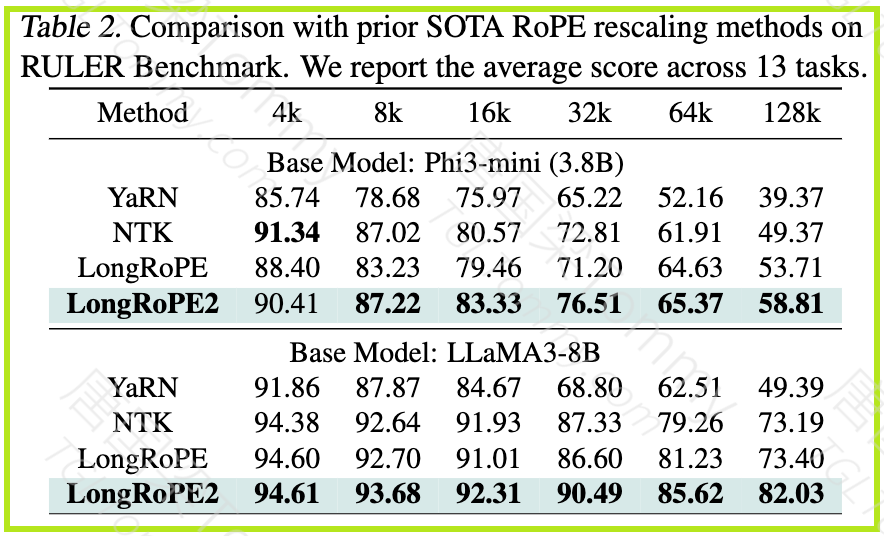
RULER 基准测试:
LongRoPE2 在 RULER 基准测试上始终优于现有方法,在 128k 窗口内的所有评估长度上都实现了卓越的结果。
-
数据: 在 LLaMA3-8B 上,LongRoPE2 在 128k 上保持了 82.03 的强劲分数,而之前的方法在较长上下文中显著下降。
-
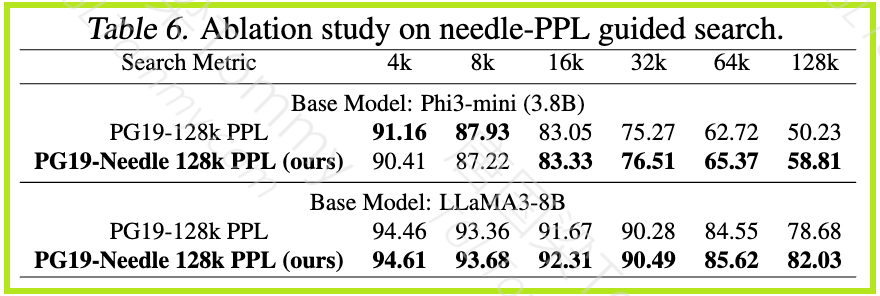
Needle in a Haystack 压力测试: LongRoPE2 在 128k 上下文窗口内的所有评估长度上都实现了接近完美的准确率。
-
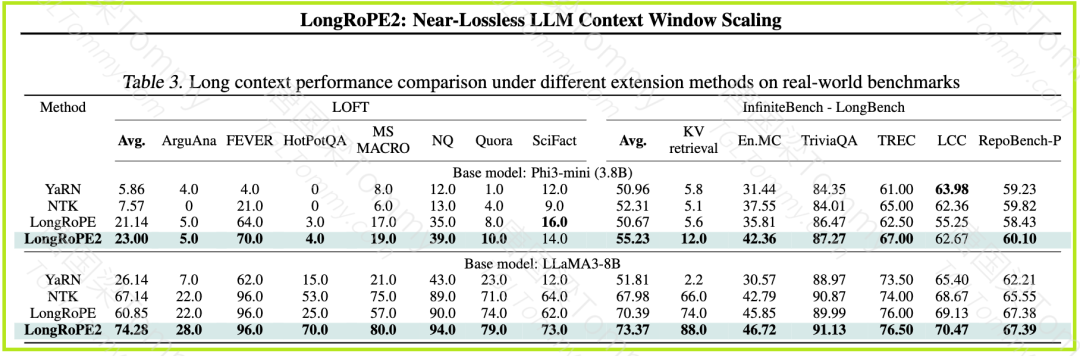
真实世界基准测试: LongRoPE2 在 LOFT、InfiniteBench 和 LongBench 等真实世界基准测试上始终提高了性能,展示了对实际场景的强大泛化能力。
-
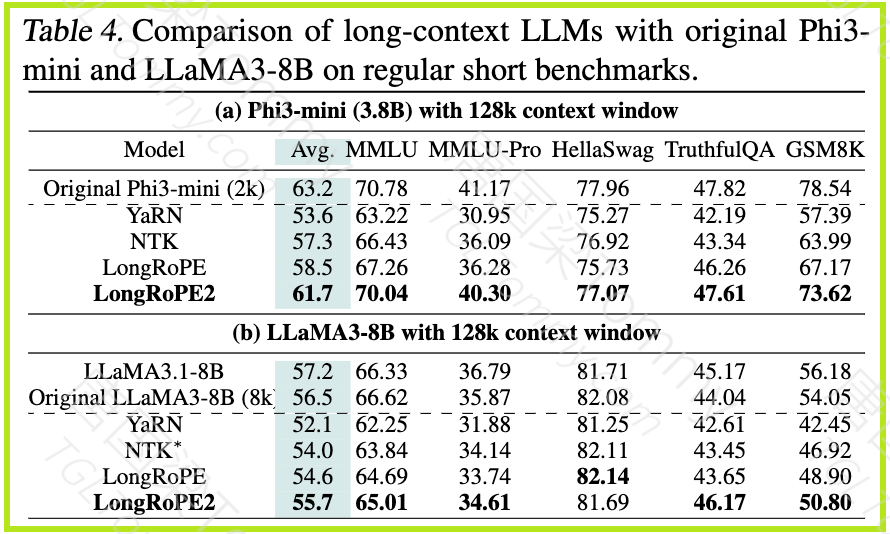
短上下文性能: LongRoPE2 保留了 Phi3-mini-3.8B 和 LLaMA3-8B 上 97.6% 和 98.6% 的预训练性能,成为第一个保留核心功能的无损扩展方法。
五、应用与启示:未来方向与价值
LongRoPE2 的提出,为 LLM 的上下文长度扩展提供了一种新的思路和方法. 它的潜在应用场景非常广泛:
-
长文档处理: LongRoPE2 可以用于处理更长的文档,例如书籍、论文、法律文件等,从而提高 LLM 在信息提取、摘要生成、问答等任务中的性能。
-
多轮对话: LongRoPE2 可以用于处理更长的对话历史,从而提高 LLM 在多轮对话任务中的连贯性和准确性。
-
代码生成: LongRoPE2 可以用于处理更长的代码序列,从而提高 LLM 在代码生成任务中的效率和质量。
未来研究方向:
-
更大的上下文窗口: 将 LongRoPE2 扩展到更大的上下文窗口,例如 1M 或更大。
-
更有效的 KV 缓存管理: 研究更有效的方法来管理 KV 缓存,减少推断延迟。
-
与其他位置编码方法的结合: 将 LongRoPE2 与其他位置编码方法结合,进一步提高性能。
总而言之,LongRoPE2 是一项非常有价值的研究,它为 LLM 的上下文长度扩展提供了一种新的解决方案,有望推动 LLM 在更多领域得到应用。
参考文献
论文链接: https://arxiv.org/abs/2502.20082
GitHub:https://github.com/microsoft/LongRoPE.git
更多关于精品课程的相关介绍,请查阅:《精品付费课程学习指南》
欢迎你到我的B站:唐国梁Tommy
或 我的个人网站:TGLTommmy.com
学习更多AI前沿技术课程,请参阅我为大家整理的:《免费公开课学习指南》
?点击左下角“阅读原文”可直接跳转至我的B站