文章同步发表或更新在个人博客(地址在公众号主页)。欢迎点赞红心关注
一、大模型是什么
1.1 大模型的定义
起源:大语言模型(Large language Models,LLMs),围绕自然语言处理任务而创建的一系列模型。
发展:基础模型(Foundation Models),可以处理多模态数据,不局限于自然语言。
下图粗略地概括了工人智能、机器学习、深度学习、大模型之间的关系。

定义
定义1:是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法,通过大量无标注文本进行训练。—出自书籍《大规模语言模型从理论到实践》
定义2:任意的在大规模数据上训练并且可以适配(例如微调)广泛下游任务的模型。—出自论文《On the Opportunities and Risks of Foundation Models》
发散思考与学习内容
-
• 自监督学习
自监督学习是一种机器学习范式,它不依赖人工标注的数据,而是通过数据自身提供的内在结构或隐藏信息来生成监督信号,从而进行模型训练。它可以被看作是一种特殊的无监督学习,因为它不需要人工标签,但它的训练方式类似于监督学习。
-
• 无标注文本
无标注文本(Unlabeled Text)指的是没有附加人工标注信息的文本数据,通常只是原始的自然语言数据,不包含类别标签、情感评分、实体标注等额外信息。
无标注文本在自然语言处理(NLP)任务中被广泛使用,尤其在自监督学习(Self-Supervised Learning)和无监督学习(Unsupervised Learning)中,它们用于预训练语言模型,帮助模型学习语言结构和语义信息,而无需人工标注数据。
1.2 大模型的特性
基本特点
1.大规模参数量,超过百亿参数规模的神经网络模型。
2.大规模训练数据,通过海量数据进行自监督预训练。
3.涌现能力,表现出了人类才会有的智能(上下文学习、思维链)。
4.多模态数据多领域适应性(通用人工智能,AGI,artificial general intelligence),经适当微调或提示,能应用于不同领域,且效果显著。
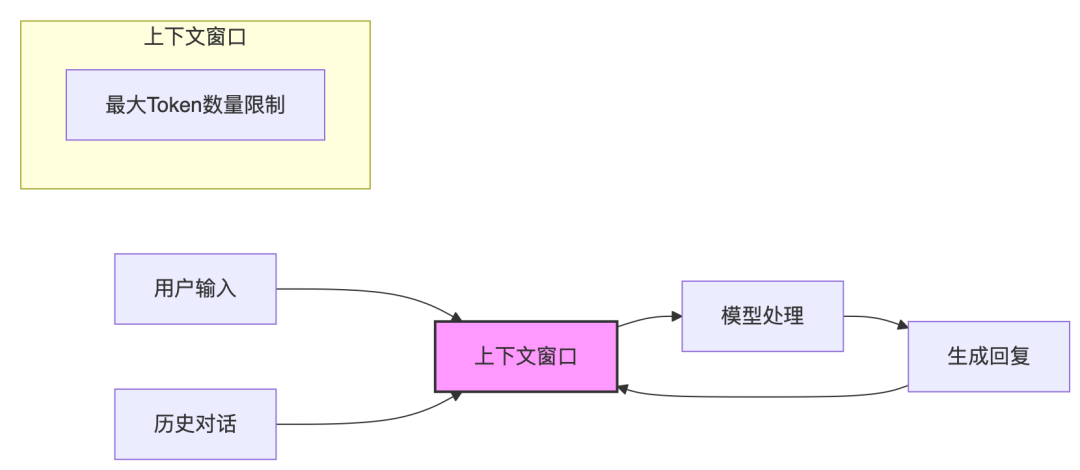
5.超长上下文感知,基于Transformers的注意力机制(Google的论文《Attention is All You Need》)保证其能充分理解信息,并做出合理推断。
6.不是搜索引擎,无法感知实时数据。(这个不足可以能过联网搜索来加以弥补,但不是大模型本身的推理能力即离开了互联网大模型将缺失这种能力)
其他特点
1.模型同质化。当前大模型都是以Transformer为基础衍生而来的
2.大力出奇迹。参数规模与预训练语料量级是模型性能的关键影响因素。例如与GPT-2的15亿参数相比,GPT-3有1750亿个参数,从而在性能方面有关质的提升。
3.从开源走向闭源。某些模型根本不会对外发布或只对少数提供API访问权限(如openai的模型),甚至一些数据集(如GPT-2)也没有公开发布
4.头部垄断。由于数据资源与算力制约,中小型企业基本无法与头部科技公司竞争。
典型代表(国外)
-
1. GPT系列:https://chat.openai.com/ -
2. 谷歌gemini:https://gemini.google.com/ -
3. 微软Copilot:https://www.bing.com/chat -
4. Meta的Llama:https://llama.meta.com/llama2 -
5. Claude系列:https://claude.ai -
6. XAI的grok:https://x.ai、https://grok.com/ -
7. MistralAI:https://mistralai7b.com/
典型代表(国内)
-
1. 通义千问:https://tongyi.aliyun.com/qianwen/ -
2. 文心一言:https://yiyan.baidu.com/welcome -
3. 智谱清言:https://chatglm.cn/main/detail -
4. 百川大模型:https://www.baichuan-ai.com/home -
5. 豆包:https://www.doubao.com/ -
6. 讯飞星火:https://xinghuo.xfyun.cn/ -
7. 天工:https://www.tiangong.cn/ -
8. 商汤商量:https://chat.sensetime.com/wb/login -
9. 腾讯混元大模型:https://hunyuan.tencent.com/?ref=feizhuke.com -
10. Kimi:https://kimi.moonshot.cn/ -
11. 华为盘古大模型(需提前申请):https://www.huaweicloud.com/product/pangu.html -
12. 360智脑:https://chat.360.com/?src=ai_360_com -
13. 深度求索DeepSeek:https://chat.deepseek.com/
1.3 大模型能做什么
-
1. 文本生成:问题回答、文稿撰写、代码生成、数学解题。 -
2. 智能客服:包括通用聊天机器人和基于RAG技术的垂直领域机器人。 -
3. 机器翻译:生成目标语言的高质量译文。 -
4. 文本摘要:对于长篇文章或报告,模型可以提炼关键信息生成简洁的摘要。 -
5. 情感分析:分析文本中的情感色彩,判断作者的态度是正面、负面还是中立。 -
6. 视觉任务:文生图、文生视频、看图说话等
1.4 大模型应用
-
1. 医疗保健和生物医学《On the Opportunities and Risks of Foundation Models》 -
2. 法律《On the Opportunities and Risks of Foundation Models》民事案件各个步骤的示例以及基础模型可能有帮助的地方 -
3. 教育《On the Opportunities and Risks of Foundation Models》 -
4. …
二、大模型的前世今生
2.1 从神经网络到大模型
-
1. 单层感知机(解决线性可分问题,20世纪40年代) -
2. BP传播算法(解决线性不可分问题,20世纪80年代) -
3. 深度神经网络(海量图片分类,2010年左右) -
4. 大模型/基础模型(通用人工智能,2020年左右)
2.2 大模型发展大事件
-
1. 2017年谷歌发表论文《Attention Is All You Need》,正式提出Transformer网络,革RNN(循环神经网络,Recurrent Neural Network)/CNN(卷积神经网络,Convolutional Neural Network)的命。 -
2. 2018年OPENAI发表论文《Improving Language Understanding by Generative Pre-Training》即“通过生成式预训练提高语言理解能力”,GPT诞生。 -
3. 2018年Google发布BERT,该模型在诸多自然语言处理任务中展现了卓越的性能,激发了大量以预训练语言模 型为基础的自然语言处理研究。 -
4. 2020年6月,OpenAI发布了 GPT-3模型。 -
5. 2022年11月,ChatGPT(就是GPT-3.5-turbo)的问世引爆全球关注。 -
6. 2023年初至今,各大科技公司纷纷推出自己的大模型,“万模大战”开始。 -
7. 2024年12月下旬与2025年1月下旬,DeepSeek相继发布 DeepSeek-V3 模型、DeepSeek-R1 模型,创新的架构与训练方法、低训练成本、优惠的API调用价格与强大高效的语言处理能力,使其迅速火遍全球、登顶中美应用下载榜首,成为中国骄傲与争相学习、推广的对象、以美国为首的西方大模型强国研究的对象。

2.3 大语言模型的三个发展阶段
来自复旦大学张奇等人编写书籍《大规模语言模型从理论到实践》
-
1. 基础模型阶段,主要集中在2018年至2021年期间,期间发布了一系列代表性的大语言模型,如BERT、GPT、百 度ERNIE、华为盘古-α、Palm等。这些模型的发布为大语言模型的研究打下了基础。 -
2. 能力探索阶段,主要发生在2019年至2022年期间。研究人员开始尝试指令微调(Instruction Tuning)方案,将各种类型的任务统一为生成式自然语言理解框架,并使用构造的训练语料对模型进行微调。 -
3. 突破发展阶段,以2022年11月ChatGPT的发布为起点。ChatGPT通过一个简单的对话框,利用一个大语言模型就能够实现问题回答、文稿撰写、代码生成、数学解题等多种任务
三、大模型爆火的原因
3.1 原因一 能通过图灵测试
让人们看到了通用人工智能乃至强人工智能的希望
➢ 功能极其强大,(ChatGPT)远超同期其他模型
➢ 可以完成跨领域、跨模态任务
在ChatGPT之前,还没有大模型能通过图灵测试。它不仅可以进行日常对话,还能够完成复杂任务,如撰写文章、回答问题等。令人惊讶的是,所有这些任务 都由一个模型完成。在许多任务上,ChatGPT的性能甚至超过了针对单一任务进行训练的有监督算法。这对于 人工智能领 域具有重大意义。
注:什么是图灵测试?
-
• 测试者(人)与被测试者(机器)隔开 -
• 测试者通过一些装置(如键盘)向被测试者随意提问 -
• 测试者根据所接受回答判定对方是人或机器 -
• 多次测试后平均每个测试者做出超过30%的误判(将机器判定成人) -
• 这台机器就被认为具有人类智能
3.2 原因二 极具争议的AI觉醒
-
• “ChatGPT是我一生中见到的两项最具革命性技术之一”——比尔盖茨 -
• “AI将是人类未来文明的最大风险之一”——埃隆·马斯克 -
• “AI是谷歌正在开发的最深奥的技术”——谷歌CEO桑达尔•皮查伊 -
• “AI将颠覆社会”——巴菲特
3.3 原因三 使用方式极其简单
在对话框中提出你的需求即可,ChatGPT活跃用户数一个月内就破亿。

四、大模型原理介绍
4.1 GPT(生成式模型)的工作过程:单字接龙
GPT是英文“Generative Pre-trained Transformer”的缩写,它的中文全称是生成式预训练变换器,是一种生成式模型。
模型输入:我们
模型输出:发明了一个新的和简单的模型

文本生成的过程本质就是单字接龙。
那么单字接龙为什么可以产生这么大的威力?
4.2 ChatGPT构建流程
ChatGPT构建主要包含四个阶段:预训练、有监督微调、奖励建模、强化学习。这四个阶段都需要不同规模 数据集合 以及不同类型的 算法 ,会产出不同类型的 模型 ,同时所需要的 计算资源 也有非常大的差别。

通过上图,我们也较容易归纳出“人工智能发展的三大因素:数据(上图中的数据集合)、算法(上图中的算法)和算力(上图中的资源需求)”。上图中还有一个内容“模型”,它其实是数据集合与算法的产物。
上图中相关专业术语解释:
-
• SFT模型:Supervised Fine-Tuning Model,即监督微调模型 -
• RM模型:Reward Model,即奖励模型 -
• RL模型:Reinforcement Learning Model,即强化学习模型
4.3 阶段一 自监督预训练
自监督预训练,英文全称”Unsupervised pre-training“
核心思路:利用前k个词(token)预测第k+1个词。
设有语料?={?1,…,??},其中 ?? 表示语料中的第 i个词(token)。
预训练的目标是最大化以下 对数似然函数 :
其中,P(ui∣ui−k,...,ui−1;θ)表示在给定前 k 个词 ui−k,...,ui−1 的条件下,模型预测下一个词是 ui的概率。?表 示模型中的可变参数。
概括性地说,上述内容描述一种通过利用前 k 个词来预测下一个词的语言模型预训练方法,并通过最大化对数似然函数来优化模型参数。

海量训练数据包括互联网网页、维基百科、书籍、GitHub、论文、问答网站等,构建包含数千亿甚至数万亿单词 的具有多样性的内容。
基础大模型构建了 长文本建模能力 ,隐含的构建了包括 事实性知识 和 常识知识 在内的 世界知识 ,根据输入的提示 词(Prompt),模型可以 生成文本补全句子 。
4.4 阶段二 有监督微调/指令微调
有监督微调/指令微调。英文全称Supervised Fine-tuning / Instruction Tuning。
有监督微调(Supervised Fine-tuning,SFT)也称为指令微调(Instruction Tuning),在阶段一的模型上继续训练。 训练数据为高质量数据集合,包含用户输入的提示词(Prompt)和对应的理想输出结果。 用户输入包括问题、闲聊对话、任务指令等多种形式和任务。
提示词(Prompt):复旦大学有几个校区?
理想输出:复旦大学现有4个校区,分别是邯郸校区、新江湾校区、枫林校区和张江校区。其中邯郸校区是复旦大学的主校区,邯郸校区与新江湾校区都位于杨浦区,枫林校区位于徐汇区,张江校区位于浦东新区。
经过微调后的有监督微调(SFT)模型具备了初步的指令和上下文理解能力,能够完成开放领域问题、阅读理解、 翻译、生成代码等能力,也具备了一定的对未知任务的泛化能力。
4.5 阶段三 奖励建模
奖励建模,英文全称”Reward Modeling“。
奖励建模(Reward Modeling)阶段的目标是构建一个文本质量评估模型。
奖励建模(Reward Modeling)用来对SFT模型的输出文本进行质量评估。
为训练得到奖励模型,须人工标注百万量级的样本库,奖励模型的训练过程独立于GPT模型。
奖励建模(Reward Modeling)阶段的目标是构建一个文本质量评估模型。
把同一个提示词多次传入SFT模型,会得到多个不同输出结果,奖励模型可以对这些结果的质量进行排序。
4.6 阶段四 强化学习
强化学习。英文全称是”Reinforcement Learning“。
强化学习(Reinforcement Learning)阶段是对指令微调(SFT)模型的进一步训练。
根据数十万用户给出的提示词,SFT模型生成相应输出,然后再利用奖励模型(RM)对这些输出进行质量评估。 结合评估结果再对SFT模型 进一步调整 ,最终得到ChatGPT。
4.7 ChatGPT构建流程回顾
4.8 token是什么
在模型中被处理的数据单元并不是单词/词语,而是token。
token是文本处理过程中的基本单元,通常是指一个单词、标点符号或者是由空格分隔的文本片段。
token是大模型世界中的“单词”,所有文本都可以由token组合而来。

英文语料中1个token约有4个英文字母,100个token约等于75个单词的长度(平均起来大概5.3个英文字母对应一个英文单词)。
中文里1个token绝大部分情况对应1~2个字,1个字居多。
大模型的token字典一般跨语种,字典中token数量为十万量级。
token从海量语料中统计而来,有不同的统计方法,其一般由高频词和低频词的子词组成。
token要保留原始文本中单词间的语义关系。
尽可能避免出现未登录词(即不在训练数据中的词。英文全称Out-Of-Vocabulary,简称OOV),但字典又不能太大。
五、AIGC简介
5.1 AIGC是什么
AIGC(Artificial Intelligence Generated Content)是指利用人工智能技术来生成全新的、逼真的、有用的数据,如 文本、图像、音频和视频等,可以在一定程度上模仿人类的创造力和写作风格。
在此之前的内容生成方式主要为:
-
1. PGC(Professional Generated Content),专家生产内容,如图书、报纸、期刊等。 -
2. UGC(User Generated Content),用户生产内容,如微博、公众号、自媒体等。
5.2 AIGC作品展示


Sora文生视频: https://www.bilibili.com/video/BV1m4421F7Yc/?spm_id_from=333.337.search-card.all.click&vd_source=0b5fe5d5aa31f64bf7462d1d094b70a2
5.3 AIGC与大模型的关系

-
1. 大模型为AIGC提供了强大的生成能力:由于大模型具有强大的学习能力和理解能力,因此可以生成更加丰富、 多样和高质量的内容,从而推动AIGC的发展。 -
2. AIGC为大模型提供了丰富的应用场景:大模型在AIGC领域的应用非常广泛,包括文本生成、图像生成、音乐创作等。这些应用场景不仅展示了大模型的强大能力,也为大模型的研究和发展提供了实际的需求和动力。 -
3. AIGC与大模型协同进化:随着AIGC应用的不断深入,对大模型的需求也在不断提高,这将推动大模型不断进行技术优化和创新。同时,大模型的进步也将进一步推动AIGC的发展,两者形成了一种协同进化的关系。
5.4 AIGC技术特点
-
1. 高效自动化。AIGC具有出色的自动化处理能力,能够迅速分析和处理大量数据,并自动生成所需内容,极大地提升了工作效率,减少了人工干预的需求,使得内容生成过程更加快速、准确。 -
2. 个性化定制。AIGC具备深度学习和分析用户行为的能力,能够根据用户的个性化需求和偏好,生成定制化的内容,能够更好地满足用户的期望,提升用户体验。 -
3. 多媒体形态。与传统的人工智能生成内容主要以文本形式为主不同,AIGC能够生成包括图像、音频、视频等多种形式的多媒体内容,使得AIGC在内容创作上更加灵活多样,能够更好地适应不同的传播渠道和用户需求。 -
4. 准确性高。在处理和分析数据时,AIGC展现出了极高的准确性,它能够精确提取关键信息,生成可靠的结论或建议,使得AIGC在决策支持、数据分析等领域具有广泛的应用价值。 -
5. 存在误导性。误导性与准确并行,AIGC基于算法和模型进行工作,底层大多是生成式的概率模型,其内容生成具有随机性,并不完全依赖于客观事实,故可能会产生误解、误判或生成不准确的内容。
5.5 中国AIGC产业图谱
“2023年中国AIGC产业图谱”即下图,由艾瑞咨询整理,发布于2023年8月。

“2024年中国AIGC产业图谱V4.1”即下图,由非凡产研整理,发布于2024年6月4日

5.6 小结
-
1. AIGC是指利用人工智能技术来生成全新的、逼真的、有用的数据。 -
2. 大模型为AIGC提供了强大的生成能力,AIGC为大模型提供了丰富的应用场景。 -
3. AIGC技术具有高效自动化、个性化定制、多媒体形态、准确性高、创新性强、可扩展性好等特点,但并不是 万能的,也可能生成具有误导性的内容。 -
4. AIGC技术的前景广阔,随着技术的突破与跨界融合的深入,未来将广泛应用于各行各业。