北京时间凌晨三点,老板格局不大,但编码能力不错的Anthropic扔出AI领域的重磅炸弹——正式发布全球首个混合推理大模型Claude 3.7 Sonnet,
同步推出的还有让开发者沸腾的智能编码工具Claude Code(可能是看Cursor的营收眼红了)
这场发布让全球各家大模型公司继续圈,先列一下重点。
1、Claude 3.7 是首个结合一般大语言模型和推理模型功能的混合推理模型。
注意看??下面的交互,选择标准模式提供快速响应,选择扩展思考模式实现逐步推理。
只是我觉得这个交互有点傻,完全可以直接用DeepSeek R1的交互方式,让用户多选择一步,就浪费用户多一秒的生命,不如直接像OpenAI、Grok3直接借鉴。
2、业内都知Claude 3.5一直是全球开发者的首选,包括风靡全球的Cursor也是基于Claude 3.5的编码能力
这次Anthropic 推出了用于智能编码的命令行工具 Claude Code。
它目前作为有限的研究预览版本使用,使开发人员能够直接从他们的终端将大量工程任务委托给 Claude。
我自己的猜测,估计是看到Cursor的日活和收入,眼红了,不如我自己做一个智能编码工具吧
至于最终能不能影响Cursor,我们还要看Claude Code能力如何,不过看官网文档介绍评测数据,Claude可能一心往AI编码方向发展了。
同时我也在X上第一时间看到Cursor表忠心,请看下图:
虽然R1很火,但其实很多场景,R1是思考过度的,特别是在B端场景应用,不能控制思维链的过程,就会导致非常慢,用户体验不好,且成本非常高,
Claude 3.7考虑到不同场景下速度、成本和精确度的不同需求,开发者可以设置一个“thinking budget”,来控制模型思考的上限,这个很有意思,
当通过 API 使用 Claude 3.7 Sonnet 时,用户还可以控制思考预算。
你可以告诉 Claude 思考不超过 N 个 token。对于任何 N 值,其输出限制为 128K 个 token。这允许用户在速度(和成本)和答案质量之间进行权衡。
期待进一步实测,前提还是要看模型底层推理能力,推理能力不行,就是屎上雕花。
在开发自家的推理模型时,Anthropic 对数学和计算机科学竞赛问题的优化较少,而是将重点转向更能反映企业实际使用 LLM 方式的现实任务。
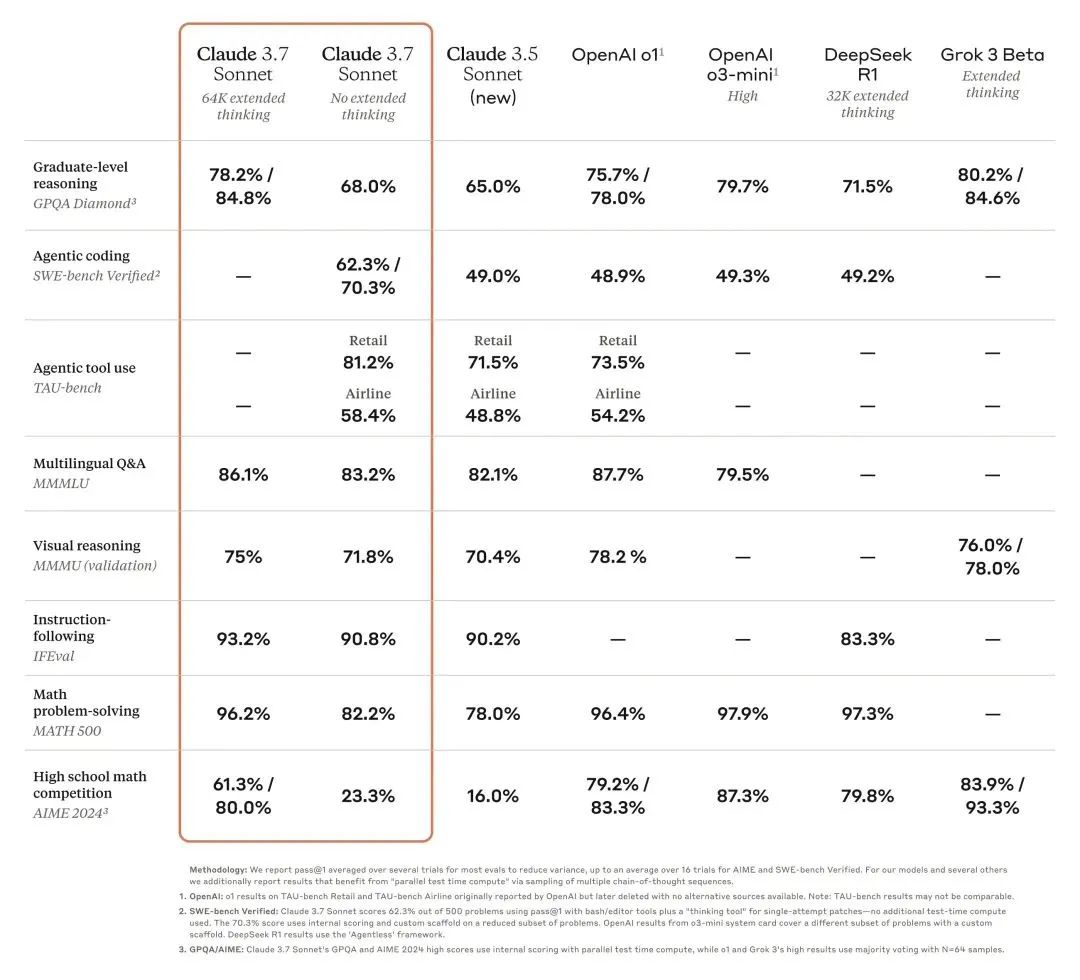
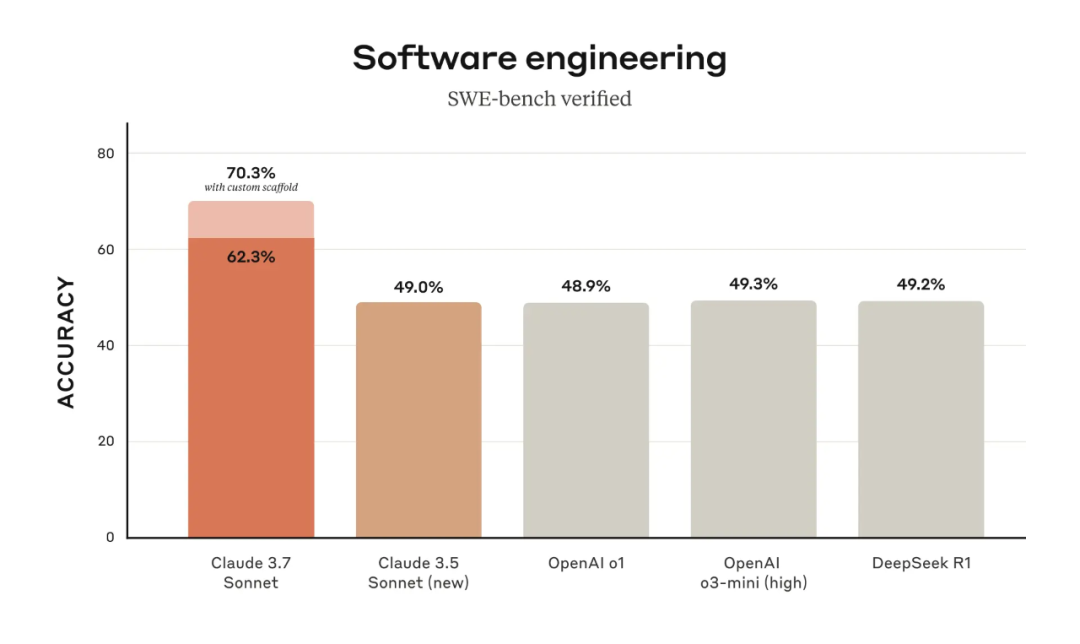
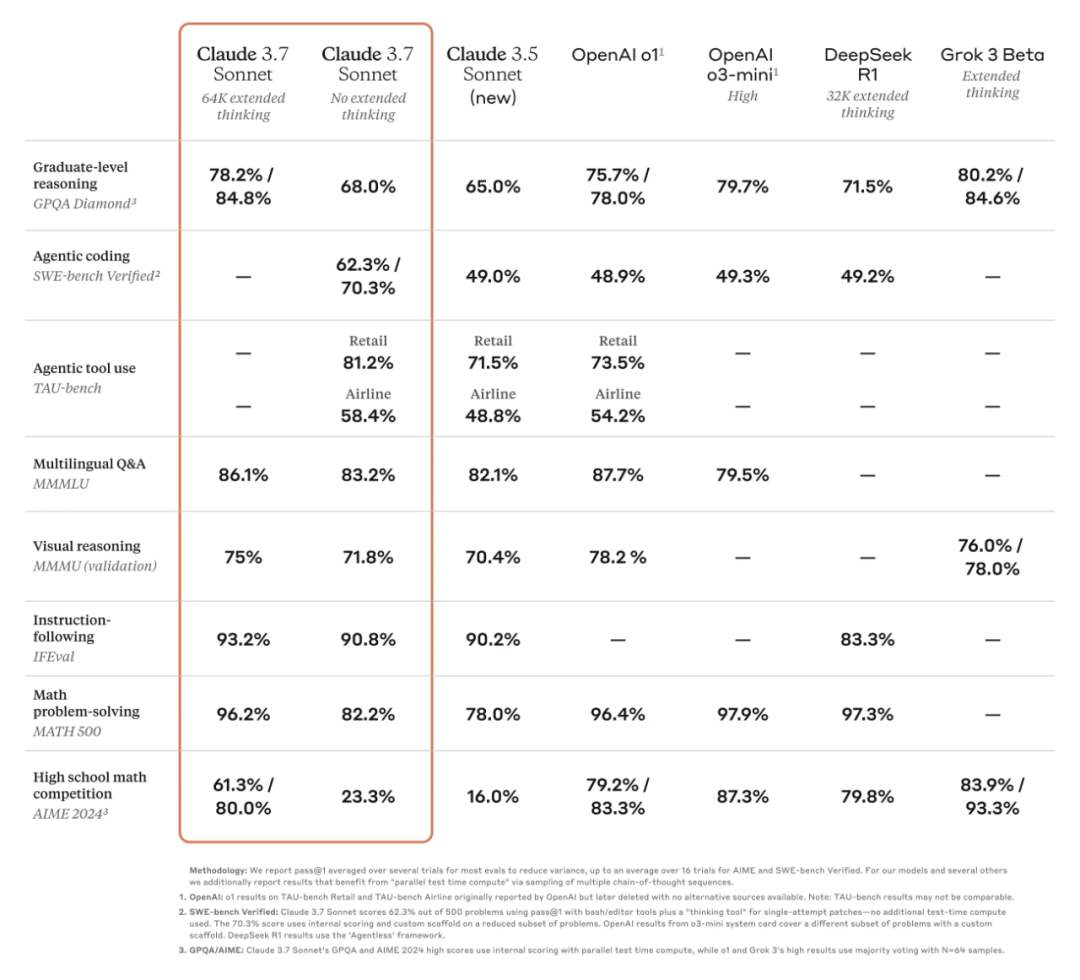
我们来看下 Claude 3.7 Sonnet 的基准测试结果,其中在 SWE-bench Verified(评估 LLM 解决 GitHub 上真实软件问题能力的基准测试数据集)上,Claude 3.7 Sonnet 实现了 SOTA 性能,远远超过了 Claude 3.5 Sonnet、OpenAI 的 o3-mini (high) 和 o1 以及 DeepSeek R1。
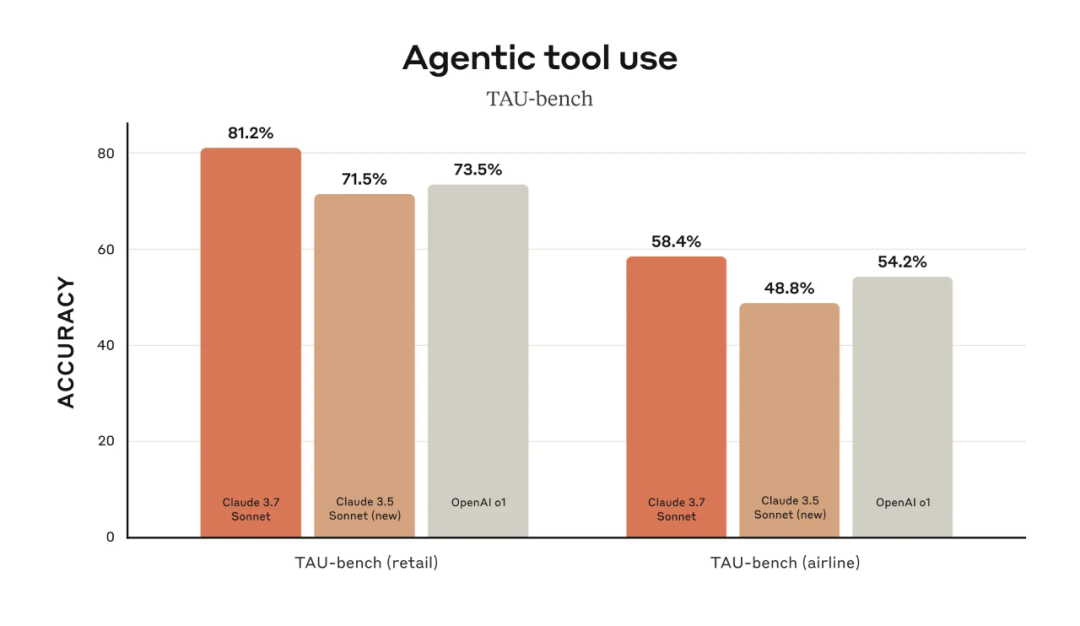
在 TAU-bench(评估 LLM 在复杂真实场景中用户与工具交互能力的基准测试平台)上,Claude 3.7 Sonnet 同样实现了 SOTA 性能,超过了 Claude 3.5 Sonnet 和 OpenAI 的 o1。
Claude 3.7 Sonnet 在指令遵循、通用推理、多模态能力和智能编码方面表现出色,扩展思考在数学和科学方面实现了显著提升,但在一些方面依然不及 OpenAI 的 o3-mini (high)、Grok-3 Beta 等。
Claude 3.7 已经全量上线可以体验了,考虑到老板格局不大,如果你的 Claude 付费账户没有被封禁的话,另外你可以通过亚马逊的平台调用API使用。
作为个人用户, Cursor、Monica 等应该也会马上接入。
下面是官方基于 extended thinking mode 向用户解释三门问题的示例。
下图所示,2025 的对应了 OpenAI 所说的 L3 智能体(不仅可以思考,还能采取行动的 AI 系统),2027 的相当于 L5 组织者(可以完成组织工作的 AI)
写在最后
当所有人都在追赶OpenAI时,Anthropic选择在推理架构和开发者生态另辟蹊径。
这场「非对称战争」能否改写行业格局?答案或许藏在即将到来的开发者迁移潮中。
不过呢,你们管你们卷,我们的Sam好像并不着急,前几天看到他在安心带娃,首先恭喜Sam当父亲,其次呢,希望未来的AGI可以充满爱与慈悲。
因为肉眼可见的各家领先的大模型公司的价值观是不一样的?
比如Anthropic的创始人在说出科学没有国界,科学家必须有国界这类格局不大话的时候…..
比如DeepSeek是一个集体主义下看着还挺有趣的灵魂。
AI现在就是一个未长大的孩子,至于长成什么样,未知啊